《STL源码剖析》——第五、六:关联容器与算法
第五章、关联容器
5.0、关联容器
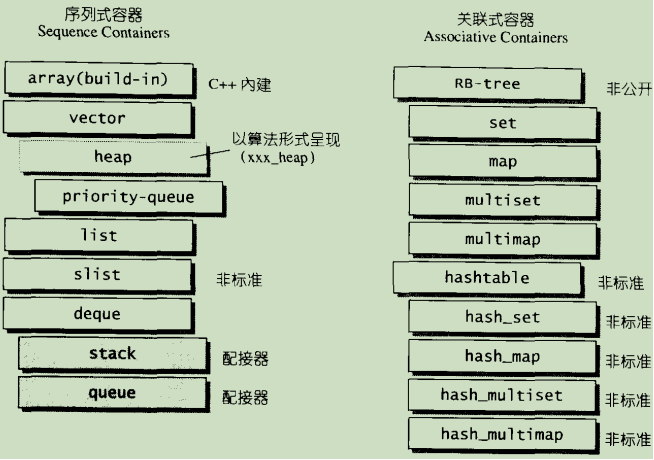
- 标准的STL关联式容器分为set(集合)和map(映射表)两大类,以及这两大类的衍生体multiset(多键集合)和multimap(多键映射表)。这些容器的底层机制均以RB-tree(红黑树)完成。RB-tree也是一个独立容器,但并不开放给外界使用。
- SGISTL还提供了一个不在标准规格之列的关联式容器:hash_table
(散列表),以及以此hash_table为底层机制而完成的hash_set(散列集合)、hash_map(散列映射表)、hash_multiset(散列多键集合)、hash_multimap
(散列多键映射表)。
- 所谓关联式容器,观念上类似关联式数据库:每笔数据(每个元素)都有一个键值(key)和一个实值(value)。当元素被插入到关联式容器中时,容器内部结构(可能是RB-tree,也可能是hash-table)便依照其键值大小,以某种特定规则将这个元素放置于适当位置。关联式容器没有所谓头尾(只有最大元素和最小元素),所以不会有所谓 push_back()、push_front()、pop_back()、pop_front()、begin()【即无法通过*.begin()取出数据】、endt()这样的操作行为。
5.1、树的导览
即讲解数据结构中的二叉树、二叉搜索树、平衡二叉树。。。
5.2、RB-tree(红黑树)
- 红黑树定义及其特性
1. 每个节点或是黑色或是红色
2. 根节点是黑色
3. 每个叶节点是黑色(叶节点为空节点)
4. 如果一个节点是红色,则它的两个子节点必须是黑色
5. 从任意的一个节点到该节点的所有叶节点的路径包含相同数目的黑色节点
6.红黑树是一种平衡二叉树,当不是完全的平衡二叉树,红黑树只要求最多三次旋转来尽可能达到平衡
【也就是说没有规定左子树与右子树的高度差必须<=1!!!!!!】
- 迭代器
- operator++
 operator--
operator-- 自身迭代器
自身迭代器 
- operator++
关于红黑树的具体数据结构,请看[博文]
5.3、 set
- set底层是由红黑树构造的
- set key值不能重复
- set中的key值不允许改变
- STL特别提供了一组set/multiset相关算法,包括交集set_intersection、联集set_union、差集 set_difference、对称差集set_symmetric_difference。
5.4、map
- map不可以通过迭代器修改键值,但可以修改实值
- map拥有list的某些性质:即增删改查其迭代器不会失效
- map几乎是在调用RBTree的接口函数
- map底层仍然是红黑树构造的
5.5、multiset
- 与set一样,只不过是允许键值存在重复
5.6、multimap
与map一样,但允许键值重复
5.7 、hashtable
- 详细讲解请见[博文](http://zzw1024.top/2019/12/23/hash-biao-xiang-jie/)
- hashtable没有向后的迭代器operator--()
5.8、hash_set
- hash_set拥有set的功能,底层使用的是hashtable,且不排序
5.9、 hash_map
- hash_map拥有map的功能,但底层是由hashtable组成的,且无排序功能
5.10、hash_multiset
- 与multiset功能完全相同,其底层换成了hashtable
- 与hash_set的区别就是可以键值重复
5.11、 hash_multimap
- hash_multimap与multimap的功能完全类似,但底层是以hashmap基本
第六章 算法algorithms
6.1、概述
- 算法的五大特征如下:
- 有穷性(Finiteness)。算法的有穷性是指算法必须能在执行有限个步骤之后终止;
- 确切性(Definiteness)。算法的每一步骤必须有确切的定义;
- 输入项(Input)。一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定出了初始条件;
- 输出项(Output)。一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;
- 可行性(Effectiveness)。算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步,即每个计算步都可以在有限时间内完成(也称之为有效性)。
- 时间复杂度
时间复杂度是衡量算法好坏的重要指标之一。时间复杂度反映的是不确定性样本量的增长对于算法操作所需时间的影响程度,与算法操作是否涉及到样本量以及涉及了几次直接相关,如遍历数组时时间复杂度为数组长度n(对应时间复杂度为O(n)),而对数据的元操作(如加减乘除与或非等)、逻辑操作(如if判断)等都属于常数时间内的操作(对应时间复杂度O(1))。
在化简某算法时间复杂度表达式时需遵循以下规则:
对于同一样本量,可省去低阶次数项,仅保留高阶次数项,如O(n^2)+O(n)可化简为O(n^2),O(n)+O(1)可化简为O(n)
可省去样本量前的常量系数,如O(2n)可化简为O(n),O(8)可化简为O(1)
对于不同的不确定性样本量,不能按照上述两个规则进行化简,要根据实际样本量的大小分析表达式增量。如O(logm)+O(n^2)不能化简为O(n^2)或O(logm)。而要视m、n两者之间的差距来化简,比如m>>n时可以化简为O(logm),因为表达式增量是由样本量决定的。
- 额外空间复杂度
算法额外空间复杂度指的是对于输入样本,经过算法操作需要的额外空间。比如使用冒泡排序对一个数组排序,期间只需要一个临时变量temp,那么该算法的额外空间复杂度为O(1)。又如归并排序,在排序过程中需要创建一个与样本数组相同大小的辅助数组,尽管在排序过后该数组被销毁,但该算法的额外空间复杂度为O(n)。
- 算法:
算法主要是由头文件<algorithm> <functional> <numeric>组成。
<algorithm>是所有 STL 头文件中最大的一个,其中常用的功能涉及到比较,交换,查找,遍历,复制,修改,反转,排序,合并等...
<numeric>体积很小,只包括在几个序列容器上进行的简单运算的模板函数.
<functional> 定义了一些模板类,用以声明函数对象。
- STL算法概况
【质变指定是算法的稳定性】



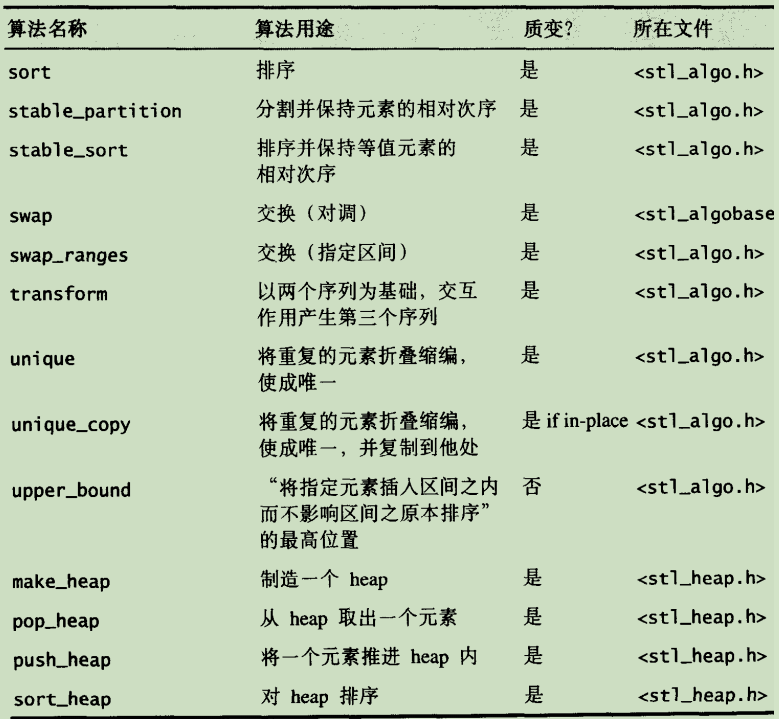
- 质变的算法——会改变操作对象之值
所有的STL算法都作用在由迭代器[first,last)所标示出来的区间上。所谓“质变算法”,是指运算过程中会更改区间内(迭代器所指)的元素内容。诸如拷贝(copy)、互换(swap)、替换(replace)、填写(fill)、删除(remove)、排列组合(permutation)、分割(partition)、随机重排(random shuffling)、排序(sort)等算法,都属此类。
- 不质变的算法——不改变操作对象之值
所有的STL算法都作用在由迭代器[first,last)所标示出来的区间上。所谓“非质变算法”,是指运算过程中不会更改区间内(迭代器所指)的元素内容。
诸如查找(find)、匹配(search)、计数(count)、巡访(for_each)、比较(equal,mismatch)、寻找极值(max,min)等算法,都属此类。但是如果你在for_each(巡访每个元素)算法身上应用一个会改变元素内容的仿函数(functor)。
6.2、算法的泛化过程
- 算法函数传参最好是传引用参数,这样可以避免由于对象的庞大而付出大的代价
- 这样的find()很好,几乎适用于任何容器——只要该容器允许指针指入,而指针们又都支持以下四种find()函数中出现的操作行为:
·inequality(判断不相等)操作符
·dereferencelm(提领,取值)操作符
·prefix increment(前置式递增)操作符
·copy(复制)行为(以便产a'x生函数的返回值)
6.3、数值算法<stl numeric.h>
- 头文件<numeric>

- accumlate

算法accumulate用来计算init和[first,last)内所有元素的总和。注意,你一定得提供一个初始值init,这么做的原因之一是当[first,last)为空区间时仍能获得一个明确定义的值。如果希望计算[first,1ast)中所有数值的总和,应该将init设为0.
- adjacent_difference

算法adjacent_difference用来计算[first,last)中相邻元素的差额。也就是说,它将*first 赋值给*result,并针对[first+1,last)内的每个迭代器i,将*i-*(i-1)之值赋值给*(result+(i-first))。
注意,你可以采用就地(in place)运算方式,也就是令result等于first。
- inner_product
算法inner_product能够计算[first1,last1)和[first2,first2+
(1ast1-first1))的一般内积(generalized inner product)。注意,你一定得提供初值init。这么做的原因之一是当[first,last)为空时,仍可获得一个明确定义的结果。如果你想计算两个vectors的一般内积,应该将init设为0.
- partical_sum
算法partial_sum用来计算局部总和。它会将*first赋值给*result,将*first和*(first+1)的和赋值给*(result+1),依此类推。注意,result可以等于first,这使我们得以完成就地(in place)计算。在这种情况下它是一个质变算法(mutating algorithm)。
运算中的总和首先初始为*first,然后赋值给*result。对于
[first+1,last)中每个迭代器i,从头至尾依序执行sum=sum+*i(第一版本)或sum=binary_op(sum,*i)(第二版本),然后再将sum赋值给*(result+(i-first))。此式所用之二元仿函数不必满足交换律(commutative)和结合律(associative)。所有运算行为的顺序都有明确设定。
本算法返回输出区间的最尾端位置:result+(last-first)。
- power

- itoa

6.4、基本算法<stl algobase.h>
- for_each
- equal
- fill
- fill_n
- iter_swap
- lexicographical_compare
- 以“字典排列方式”对两个序列[first1,last1)和tfirst2,1ast2)进行比较。比较操作针对两序列中的对应位置上的元素进行,并持续直到
- (1)某一组对应元素彼此不相等;
- (2)同时到达1ast1和last2(当两序列的大小相同);
- (3)到达1ast1或last2(当两序列的大小不同)。
- 以“字典排列方式”对两个序列[first1,last1)和tfirst2,1ast2)进行比较。比较操作针对两序列中的对应位置上的元素进行,并持续直到
- 当这个函数在对应位置上发现第一组不相等的元素时,有下列几种可能:
·如果第一序列的元素较小,返回true.否则返回false。
·如果到达last1而尚未到达last2,返回true。
·如果到达last2而尚未到达last1,返回false。
·如果同时到达last1和last2(换句话说所有元素都匹配),返回false;
- max
- min
- mism atch
用来平行比较两个序列,指出两者之间的第一个不匹配点。返回一对迭代器,分别指向两序列中的不匹配点,如下图。如果两序列的所有对应元素都匹配,返回的便是两序列各自的last迭代器。缺省情况下是以equality操作符来比较元素;但第二版本允许用户指定比较操作。如果第二序列的元素个数比第一序列多,多出来的元素忽略不计。如果第二序列的元素个数比第一序列少,会发生未可预期的行为。
- swap
- copy
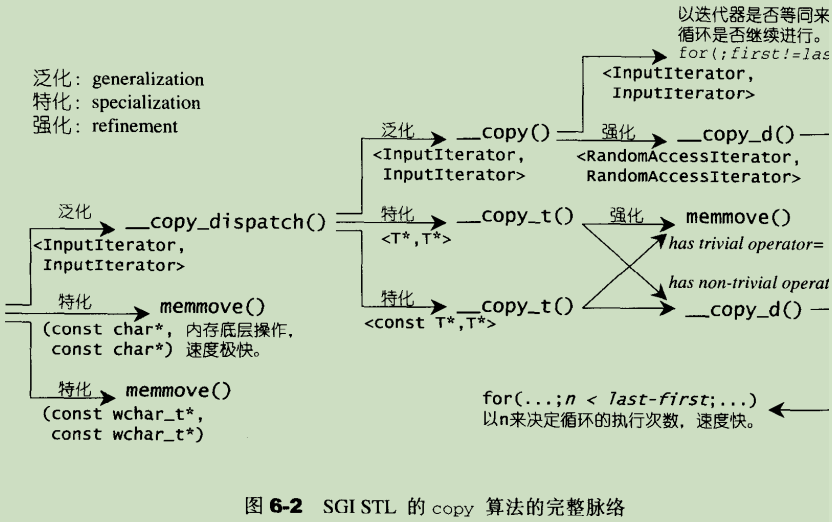
6.5、set相关算法
STL一共提供了四种与set(集合)相关的算法,分别是并集(union)、交集(intersection)、差集(difference)、对称差集(symmetric difference)。
- set_union
算法set_union可构造s1、s2之并集。也就是说,它能构造出集合s1Us2,此集合内含s1或s2内的每一个元素。s1、s2及其并集都是以排序区间表示。返回值为一个迭代器,指向输出区间的尾端。
由于s1和s2内的每个元素都不需唯一,因此,如果某个值在s1出现n次,在s2出现m次,那么该值在输出区间中会出现max(m,n)次,其中n个来自s1,其余来自s2。
set_union 是一种稳定(stable)操作,意思是输入区间内的每个元素的相对顺序都不会改变。set-union有两个版本,差别在于如何定义某个元素小于另一个元素。
- set_intersection
算法 set_intersection可构造s1、s2之交集。也就是说,它能构造出集合s1 n s2,此集合内含同时出现于s1和s2内的每一个元素。s1、s2及其交集都是以排序区间表示。返回值为一个迭代器,指向输出区间的尾端。
如果某个值在s1出现n次,在s2出现m次,那么该值在输出区间中会出现min(m,n)次,并且全部来自s1。
set_intersection 是一种稳定(stable)操作,意思是输出区间内的每个元素的相对顺序都和s1内的相对顺序相同。它有两个版本,差别在于如何定义某个元素小于另一个元素。
- set_difference
算法 set_difference可构造s1、s2之差集。也就是说,它能构造出集合s1-s2,此集合内含“出现于s1但不出现于s2”的每一个元素。s1、s2及其交集都是以排序区间表示。返回值为一个迭代器,指向输出区间的尾端。
由于s1和s2内的每个元素都不需唯一,因此如果某个值在s1出现n次,在s2出现m次,那么该值在输出区间中会出现max(n-m,0)次,并且全部来自S1。
set_difference 是一种稳定(stable)操作,意思是输出区间内的每个元素的相对顺序都和S1内的相对顺序相同。它有两个版本,差别在于如何定义某个元素小于另一个元素。第一版本使用operator<进行比较,第二版本采用仿函数comp进行比较。
- set_symmetric_difference
算法setsymmetric_difference 可构造s1、s2之对称差集。也就是说,它能构造出集合(S1-S2)U(S2-S1),此集合内含“出现于s1但不出现于s2”
以及“出现于s2但不出现于s1”的每一个元素。S1、S2及其交集都是以排序区间表示。返回值为一个迭代器,指向输出区间的尾端。
由于s1和s2内的每个元素都不需唯一,因此如果某个值在s1出现n次,在s2出现m次,那么该值在输出区间中会出现ln-ml次。如果n>m,输出区间内的最后n-m个元素将由s1复制而来,如果n<m则输出区间内的最后m-n个元素将由s2复制而来。在STL set容器内,m≤1且n<=1。
setsymmetric_difference 是一种稳定(stable)操作,意思是输入区间内的元素相对顺序不会被改变。它有两个版本,差别在于如何定义某个元素小于另一个元素。第一版本使用operators进行比较,第二版本采用仿函数comp。
6.6、heap算法
6.7、其它算法
深入源代码之前,先观察每一个算法的表现,是个比较好的学习方式。以下程序示范本节每一个算法的用法。程序中有时使用STL内建的仿函数(functors,如less,greater,equeal_to)和配接器(adapters,如bind2nd),有时使用自定义的仿函数(如display,even_by_two)。
- adjacent find
找出第一组满足条件的相邻元素。这里所谓的条件,在版本一中是指“两元素相等”,在版本二中允许用户指定一个二元运算,两个操作数分别是相邻的第一元素和第二元素。
- count
运用equality操作符,将[first,last)区间内的每一个元素拿来和指定值value比较,并返回与value相等的元素个数。
- count_if
将指定操作(一个仿函数)pred实施于[first,1ast)区间内的每一个元素身上,并将“造成pred之计算结果为true”的所有元素的个数返回。
- find
- find it
- find_end
- find_first of
- for_each
- generate
- generate_n
- includes(应用于有序区间)
- max element
- merge(应用于有序区间)
- min_element
- partition
partition 会将区间[first,last)中的元素重新排列。所有被一元条件运算pred判定为true的元素,都会被放在区间的前段,被判定为false的元素,都会被放在区间的后段。这个算法并不保证保留元素的原始相对位置。如果需要保留原始相对位置,应使用stable_partition。
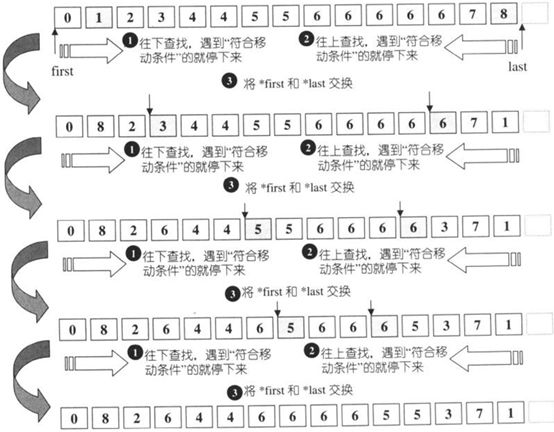
- remove移除(但不删除)
移除[first,1ast)之中所有与value相等的元素。这一算法并不真正从容器中删除那些元素(换句话说容器大小并未改变),而是将每一个不与value相等(也就是我们并不打算移除)的元素轮番赋值给first之后的空间。返回值Fonwarditerator 标示出重新整理后的最后元素的下一位置。
例如序列
{0,1,0,2,0,3,0,4],如果我们执行remove(),希望移除所有0值元素,执行结果将是{1,23,4,0,3.0.4]。每一个与0不相等的元素,1,2,3,4,分别被拷贝到第一、二、三、四个位置上。第四个位置以后不动,换句话说是第四个位置之后是这一算法留下的残余数据。返回值Forwardlterator 指向第五个位置。如果要删除那些残余数据,可将返回的迭代器交给区间所在之容器的erase()member function。注意,array 不适合使用remove()和remove_if(),因为array无法缩小尺寸,导致残余数据永远存在。对array而言,较受欢迎的算法是remove_copy()和
- remove_copy
- remove_if
- remove_copy.if
- replace
- replace_copy
- replace if
- replace_copy._if
- reverse
- reverse_copy
- rotate
将[first,middle)内的元素和[middle,last)内的元素互换。middle所指的元素会成为容器的第一个元素。
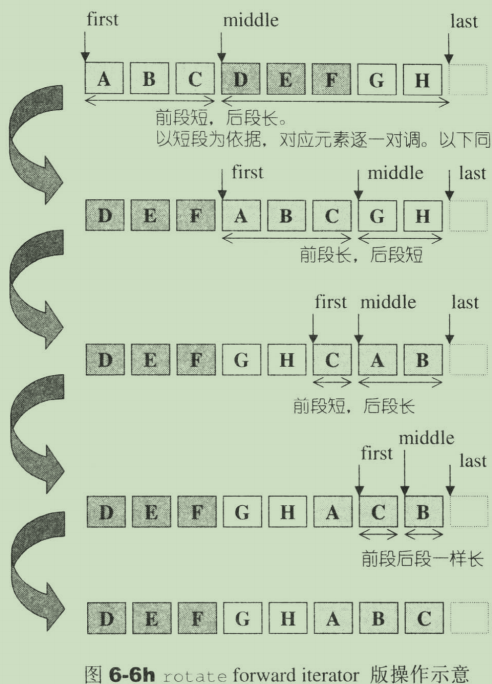
- rotate_copy
- search
- search_n
在序列[first,last)所涵盖的区间中,查找“连续count个符合条件之元素”所形成的子序列,并返回一个迭代器指向该子序列起始处。如果找不到这样的子序列,就返回迭代器last。上述所谓的“某条件”,在search_n版本一指的是相等条件“equality”,在search_n版本二指的是用户指定的某个二元运算(以仿函数呈现)。
例如,面对序列{10,8,8,7,2,8,7,2,2,8,7,0},查找“连续两个8”所形成的子序列起点,可以这么写:
iter1 = search_n(iv.begin(),iv.end(),2,8);
查找“连续三个小于8的元素”所形成的子序列起点,可以这么写:
iter2 = search_n(iv.begin(),iv.end(),3,8,1ess<int>();
- swap_ranges
- transform
- unique
- unique_copy
- lower_bound(应用于有序区间)
这是二分查找(binary search)的一种版本,试图在已排序的(first,last)中寻找元素value。如果[first,last)具有与value相等的元素(s),便返回一个迭代器,指向其中第一个元素。如果没有这样的元素存在,便返回“假设这样的元素存在时应该出现的位置”。也就是说,它会返回一个迭代器,指向第一个“不小于value”的元素。如果value大于[first,last)内的任何一个元素,则返回last。以稍许不同的观点来看1ower_bound,其返回值是“在不破坏排序状态的原则下,可插入value的第一个位置”。
- upper_bound(应用于有序区间)
算法upper_bound是二分查找(binary search)法的一个版本。它试图在已排序的[first,last)中寻找value。更明确地说,它会返回“在不破坏顺序的情况下,可插入value的最后一个合适位置”。
- binary_search(应用于有序区间)
算法binary_search 是一种二分查找法,试图在已排序的[first,last)中寻找元素value。如果[first,last)内有等同于value的元素,便返回true,否则返回false。
返回单纯的bool或许不能满足你,前面所介绍的lower_bound和upper_bound能够提供额外的信息。事实上binary_search便是利用lower_bound先找出“假设value存在的话,应该出现的位置”,然后再对比该位置上的值是否为我们所要查找的目标,并返回对比结果。
- next_permutation
STL提供了两个用来计算排列组合关系的算法,分别是nextpermucation和 prev_permutation。首先我们必须了解什么是“下一个”排列组合,什么是“前一个”排列组合。
考虑三个字符所组成的序列(a,b,c)。这个序列有六个可能的排列组合:abc,acb,bac,bca,cab,cba。这些排列组合根据less-than操作符做字典顺序(lexicographical)的排序。也就是说,abc名列第一,因为每一个元素都小于其后的元素。
next_permutation()会取得[first,last)所标示之序列的下一个排列组合。如果没有下一个排列组合,便返回false;否则返回true。
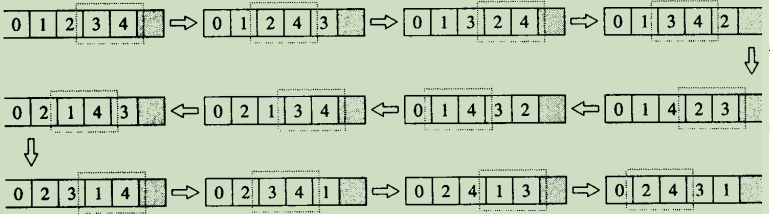
- 6.7.6 prev_permutation
所谓“前一个”排列组合,其意义已在上一节阐述。实际做法简述如下,其中所用的符号如图6-8所示。首先,从最尾端开始往前寻找两个相邻元素,令第一元素为*i,第二元素为*ii,且满足*i>*ii。找到这样一组相邻元素后,再从最尾端开始往前检验,找出第一个小于*i的元素,令为*j,将i,j元素对调,再将ii之后的所有元素颠倒排列。此即所求之“前一个”排列组合。
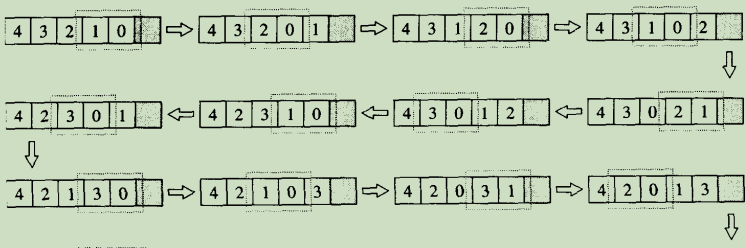
- random_shufle
这个算法将[first,last)的元素次序随机重排。也就是说,在N!种可能的元素排列顺序中随机选出一种,此处N为last-first。
N个元素的序列,其排列方式有N!种,random_shuffle会产生一个均匀分布,因此任何一个排列被选中的机率为1/N!。这很重要,因为有不少算法在其第一阶段过程中必须获得序列的随机重排,但如果其结果未能形成“在N!个可能排列上均匀分布(uniform distribution)”,便很容易造成算法的错误。
- partial_sort/partial_sort
本算法接受一个middle 迭代器(位于序列[first,last)之内),然后重新安排[first,last),使序列中的middle-first个最小元素以递增顺序排序,置于(first,middle)内。其余1ast-middle个元素安置于[middle,last)中,不保证有任何特定顺序。

- sort
STL的sort 算法,数据量大时采用Quick Sort,分段递归排序。
一旦分段后的数据量小于某个门槛,为避免Quick Sort的递归调用带来过大的额外负荷(overhead),就改用Insertion Sort。
如果递归层次过深,还会改用Heap Sort。
- equal_range(应用于有序区间)
算法equal_range是二分查找法的一个版本,试图在已排序的[first,last)中寻找value。它返回一对迭代器i和j,其中i是在不破坏次序的前提下,value可插入的第一个位置(亦即1ower_bound),j则是在不破坏次序的前提下,value可插入的最后一个位置(亦即upper_bound)。因此,[i,j)内的每个元素都等同于value,而且[i,j)是(first,last)之中符合此一性质的最大子区间。
于是,算法lower_bound返回区间A的第一个迭代器,算法upper_bound返回区间A的最后元素的下一位置,算法equalrange则是以pair的形式将两者都返回。
- inplace_merge(应用于有序区间)
如果两个连接在一起的序列[first,middle)和[middle,last)都已排序,那么inplacemerge可将它们结合成单一一个序列,并仍保有序性(sorted)。
如果原先两个序列是递增排序,执行结果也会是递增排序,如果原先两个序列是递减排序,执行结果也会是递减排序。
和merge一样,inplace_merge也是一种稳定(stable)操作。每个作为数据来源的子序列中的元素相对次序都不会变动;如果两个子序列有等同的元素,第一序列的元素会被排在第二序列元素之前。
- nth_element
这个算法会重新排列[first,last),使迭代器nth所指的元素,与“整个
[first,1ast)完整排序后,同一位置的元素”同值。此外并保证(nth,last)内没有任何一个元素小于(更精确地说是不大于)[first,nth)内的元素,但对于[first,nth)和[nth,last)两个子区间内的元素次序则无任何保证一—这一点也是它与partial_sort很大的不同处。以此观之,nth_element比较近似partition 而非 sort 或 partial_sort。
例如,假设有序列{22,30,30,17,33,40,17,23,22,12,20},以下操作:
nth_element(iv.begin(),iv.begin()+5,iv.end());便是将小于*(iv.begin()+5)(本例为40)的元素置于该元素之左,其余置于该元素之右,并且不保证维持原有的相对位置。获得的结果为{20,12,22,17,17,
22,23,30,30,33,40]。执行完毕后的5th个位置上的元素值22,与整个序列完整排序后{12,17,17,20,22,22,23,30,30,33,40]的5th个位置上的元素值相同。
- 6.7.13 merge sort
以上的排序算法详见[博文]
《STL源码剖析》——第五、六:关联容器与算法的更多相关文章
- 面试题总结(三)、《STL源码剖析》相关面试题总结
声明:本文主要探讨与STL实现相关的面试题,主要参考侯捷的<STL源码剖析>,每一个知识点讨论力求简洁,便于记忆,但讨论深度有限,如要深入研究可点击参考链接,希望对正在找工作的同学有点帮助 ...
- 【STL 源码剖析】浅谈 STL 迭代器与 traits 编程技法
大家好,我是小贺. 点赞再看,养成习惯 文章每周持续更新,可以微信搜索「herongwei」第一时间阅读和催更,本文 GitHub : https://github.com/rongweihe/Mor ...
- STL"源码"剖析-重点知识总结
STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略多 :) 1.STL概述 STL提供六大组件,彼此可以组合 ...
- 【转载】STL"源码"剖析-重点知识总结
原文:STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点 ...
- STL源码剖析 迭代器(iterator)概念与编程技法(三)
1 STL迭代器原理 1.1 迭代器(iterator)是一中检查容器内元素并遍历元素的数据类型,STL设计的精髓在于,把容器(Containers)和算法(Algorithms)分开,而迭代器(i ...
- STL"源码"剖析
STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略 ...
- 《STL源码剖析》相关面试题总结
原文链接:http://www.cnblogs.com/raichen/p/5817158.html 一.STL简介 STL提供六大组件,彼此可以组合套用: 容器容器就是各种数据结构,我就不多说,看看 ...
- STL源码剖析之序列式容器
最近由于找工作需要,准备深入学习一下STL源码,我看的是侯捷所著的<STL源码剖析>.之所以看这本书主要是由于我过去曾经接触过一些台湾人,我一直觉得台湾人非常不错(这里不涉及任何政治,仅限 ...
- 《STL源码剖析》学习之traits编程
侯捷老师在<STL源码剖析>中说到:了解traits编程技术,就像获得“芝麻开门”的口诀一样,从此得以一窥STL源码的奥秘.如此一说,其重要性就不言而喻了. 之前已经介绍过迭代器 ...
- 《STL源码剖析》读书笔记
转载:https://www.cnblogs.com/xiaoyi115/p/3721922.html 直接逼入正题. Standard Template Library简称STL.STL可分为容器( ...
随机推荐
- 什么是 Python 的命名空间?
在 Python 中,所有的名字都存在于一个空间中,它们在该空间中存在和被操作——这就是命名空间.它就好像一个盒子,每一个变量名字都对应装着一个对象.当查询变量的时候,会从该盒子里面寻找相应的对象.
- java定时任务详解
首先,要创建你自己想要定时的实体类 @Service("smsService")@Transactionalpublic class SmsSendUtil { @Autowire ...
- jQuery中$.get()和$.post()的异同点
相同点:两者都是向服务器异步请求数据的. 不同点: 1.$.get() 方法使用GET方法来进行异步请求的,$.post() 方法使用POST方法来进行异步请求的. 2.如果前端使用$.get() 方 ...
- webstorm 2019 去掉编辑器右侧白线
第一步:打开设置 第二步: 第三部:apply 关闭设置
- 在数据库中分析sql执行性能
SET STATISTICS PROFILE ON SET STATISTICS IO ON SET STATISTICS TIME ON GO /*--SQL脚本开始*/ SELECT * FROM ...
- Linux性能优化从入门到实战:12 内存篇:Swap 基础
内存资源紧张时,可能导致的结果 (1)OOM 杀死大内存CPU利用率又低的进程(系统内存耗尽的情况下才生效:OOM 触发的时机是基于虚拟内存,即进程在申请内存时,如果申请的虚拟内存加上服务器实际已用的 ...
- 使用Varnish加速Web
通过配置Varnish缓存服务器,实现如下目标: - 使用Varnish加速后端Web服务 - 代理服务器可以将远程的Web服务器页面缓存在本地 - 远程Web服务器对客户端用户是透明的 - 利用缓存 ...
- node.js从入门到放弃《什么是node.js》
1.什么是node.js Node.js是一个后端的Javascript运行环境(支持的系统包括*nux.Windows),这意味着你可以编写系统级或者服务器端的Javascript代码. Node. ...
- Codeforces Round #595 (Div. 3) 题解
前言 大家都在洛谷上去找原题吧,洛谷还是不错的qwq A 因为没有重复的数,我们只要将数据排序,比较两两之间有没有\(a_j - a_i == 1 (j > i)\) 的,有则输出 \(2\) ...
- CSS3选择器 :read-only选择器 CSS3选择器 :read-write选择器
CSS3选择器 :read-only选择器 “:read-only”伪类选择器用来指定处于只读状态元素的样式.简单点理解就是,元素中设置了“readonly=’readonly’” 示例演示 通过“: ...