Run Your Tensorflow Deep Learning Models on Google AI
People commonly tend to put much effort on hyperparameter tuning and training while using Tensoflow&Deep Learning. A realistic problem for TF is how to integrate models into industry: saving pre-trained models, restoring them when necessary, and doing predictions regarding to request input. Fortunately, Google AI helps!
Actually, while a model is trained, tensorflow has two different modes to save it. Most people and blog posts adopt Checkpoint, which refers to 'Training Mode'. The training work continues if someone load the checkpoint. But a drawback is you have to define the architecture once and once again before restore the checkpoint. Another mode called 'SavedModel' is more suitable for serving (release version product). Applications can send prediction requests to a server where the 'SavedModel' is deployed, and then responses will be sent back.
Before that, we only need to follow three steps: save the model properly, deploy it onto Google AI, transform data to required format then request. I am going to illustrate them one by one.
1. Save the model into SavedModel:
In a typical tensorflow training work, architecture is defined first, then it is trained, finally comes to saving part. We just jump to the saving code: the function used here is 'simple_save', and four parameters are session, saving folder, input variable&name, output variable&name.
tf.saved_model.simple_save(sess, 'simple_save/model', \
inputs={"x": tf_x},outputs={"pred": pred})
After that, we got the saved model on the target directory:
saved_model.pb
/variables/variables.index
/variables/variables.data-00000-of-00001
2. Deploy SavedModel onto Google AI:
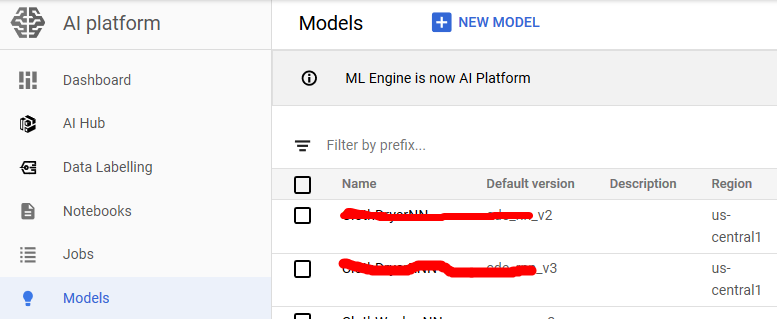
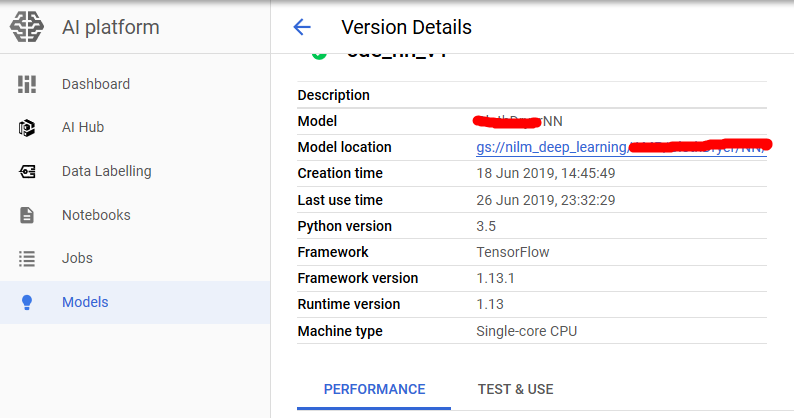
On Google Cloud, files are stored on Google Bucket, so first a Tensorflow model (.pb file and variables folder) need to be uploaded. Then create a Google AI model and a version. Actually there can be multiple versions under a model, which is quite like solving one task by different ways. You can even use several deep learning architectures as
different version, and then switch solutions when request predictions. Versions and Google Bucket location that stores the SavedModel are bound.
3. Doing online predictions:
Because we request prediction inside the application, and require immediate response, so we choose online prediction. The official code to request is shown below, which is HTTP Request and HTTP Response. The input and output data are all in Json Format. We can transform our input data into List, and call this function.
def predict_json(project, model, instances, version=None):
"""Send json data to a deployed model for prediction. Args:
project (str): project where the AI Platform Model is deployed.
model (str): model name.
instances ([Mapping[str: Any]]): Keys should be the names of Tensors
your deployed model expects as inputs. Values should be datatypes
convertible to Tensors, or (potentially nested) lists of datatypes
convertible to tensors.
version: str, version of the model to target.
Returns:
Mapping[str: any]: dictionary of prediction results defined by the
model.
"""
# Create the AI Platform service object.
# To authenticate set the environment variable
# GOOGLE_APPLICATION_CREDENTIALS=<path_to_service_account_file>
service = googleapiclient.discovery.build('ml', 'v1')
name = 'projects/{}/models/{}'.format(project, model) if version is not None:
name += '/versions/{}'.format(version) response = service.projects().predict(
name=name,
body={'instances': instances}
).execute() if 'error' in response:
raise RuntimeError(response['error']) return response['predictions']
The response is also in Json format, I wrote a piece of code to transform it into Numpy Array:
def from_json_to_array(dict_list):
value_list = []
for dict_instance in dict_list:
instance = dict_instance.get('pred')
value_list.append(instance)
value_array = np.asarray(value_list)
return value_array
Yeah, that's it! Let's get your hands dirty!
Reference:
https://www.tensorflow.org/guide/saved_model
https://cloud.google.com/blog/products/ai-machine-learning/simplifying-ml-predictions-with-google-cloud-functions
https://cloud.google.com/ml-engine/docs/tensorflow/online-predict
Run Your Tensorflow Deep Learning Models on Google AI的更多相关文章
- How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras
Hyperparameter optimization is a big part of deep learning. The reason is that neural networks are n ...
- a Javascript library for training Deep Learning models
w强化算法和数学,来迎接机器学习.神经网络. http://cs.stanford.edu/people/karpathy/convnetjs/ ConvNetJS is a Javascript l ...
- Towards Deep Learning Models Resistant to Adversarial Attacks
目录 概 主要内容 Note Madry A, Makelov A, Schmidt L, et al. Towards Deep Learning Models Resistant to Adver ...
- (转) Awesome Deep Learning
Awesome Deep Learning Table of Contents Free Online Books Courses Videos and Lectures Papers Tutori ...
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- (转) Deep Learning Resources
转自:http://www.jeremydjacksonphd.com/category/deep-learning/ Deep Learning Resources Posted on May 13 ...
- Machine and Deep Learning with Python
Machine and Deep Learning with Python Education Tutorials and courses Supervised learning superstiti ...
- The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near
The Brain vs Deep Learning Part I: Computational Complexity — Or Why the Singularity Is Nowhere Near ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Regularization)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Regularization Welcome to the second assignment of this week. Deep ...
随机推荐
- vue 跳转页面返回时tab状态有误的解决办法
一.前言 最近在做新vue项目的时候遇到了一个问题,就是tab间的切换没有问题,当跳转到其他页面时,且这个页面并非子路由,再用浏览器的返回按钮返回首页时,tab的active始终指向默认的第一个选项. ...
- C# 中File和FileStream的用法
原文:https://blog.csdn.net/qq_41209575/article/details/89178020 1.首先先介绍File类和FileStream文件流 1.1 File类, ...
- C#中ComboBox动态绑定赋值
http://www.crifan.com/csharp_combobox_data_dynamic_binding/ C#中,已有一个List,想要动态的,绑定到ComboBox中. [解决过程] ...
- HTML使用框架跳转到指定的节
内容区(links.html) <html> <body> <h2>Chapter 1</h2> <p>This chapter expla ...
- [好好学习]在VMware中安装Oracle Enterprise Linux (v5.7) - (3/5)
进入OEL
- linux命令截取文件最后n行(所有命令)
linux命令截取文件最后n行(所有命令) tail -n a.txt > b.txt 联想:系统信息 arch 显示机器的处理器架构(1) uname -m 显示机器的处理器架构(2) una ...
- Windows结束某个端口的进程
1.打开cmd命令窗口,输入命令:netstat -ano | findstr 8080,根据端口号查找对应的PID.结果如下: 发现8080端口被PID(进程号)为2188的进程占用. 2.根据PI ...
- OSI参考模型与TCP/IP参考模型与TCP/IP协议栈
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11484126.html OSI参考模型与TCP/IP参考模型与TCP/IP协议栈 TCP/IP分层模型 ...
- hdu 2815 : Mod Tree 【扩展BSGS】
题目链接 直接用模板好了.实在不行,反正有队友啊~~~~ #include<bits/stdc++.h> using namespace std; typedef long long LL ...
- 迁移数据时 timestamp类型字段报错: 1067 - Invalid default value for 'login_time'
MySQL数据库升级 8.0.13,原版本5.5:执行导出来的SQL文件时报错 1067 - Invalid default value for 'login_time' 原因:MySQL 5.6以后 ...