Google File System 论文阅读笔记
核心目标:Google File System是一个面向密集应用的,可伸缩的大规模分布式文件系统。GFS运行在廉价的设备上,提供给了灾难冗余的能力,为大量客户机提供了高性能的服务。
1.一系列前提
GFS的系统构建针对其自身使用的特点在传统的分布式系统的基础上又进行了一些创新,基于的前提假设主要包括以下方面:
1、由于系统由廉价的商用机构成,组件失效被认为是一种常态,系统必须可以持续监控自身的状态。
2、系统存储以大文件为主,小文件也支持,但是没有进行特别的优化处理。
3、系统的工作负载主要包含:
大规模的连续读取和小规模的随机读取
大规模的、顺序的、追加的方式写入数据
对于小规模的读和写,效率并不是很高。
4、由于同时读写数据的客户端很多,因此使用最小的同步开销来实现的原子的多路追加数据操作是必不可少的,操作原子性以及同步互斥(论文中所谓的行为定义明确的)等问题是必须要考虑的。
5、目标程序(客户端)绝大部分要求能够高速率的、大批量的处理数据,高性能稳定的网络带宽比延迟更重要。
2.主要架构
2.1基本模块与大致工作流程
GFS的大致架构就是如同下图中描述的这样:
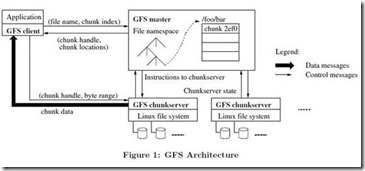
GFS的主要组成模块包含以下方面:一个单独的Master节点(逻辑上是单独的),多个chunk服务器,这些chunk服务器是一些普通的符合最低风险要求的Linux服务器。Master节点与chunk服务器同时被多个客户端访问着。
文件的基本单位是chunk(64M)每一个chunk都有备份,被分别存储在不同的chunk服务器当中。客户端访问Master节点仅仅是拿到一个chunk数据位置的信息(即元数据 相当于一个地图 根据这个地图去对应的服务器中找具体的chunk数据)根据这个元数据(文件和chunk的命名空间、文件和chunk的对应关系、每个chunk副本所存在的地点)来访问对应的文件。重要的元数据变更还会被存储在操作日志中,Master可以通过操作日志来对元数据进行恢复。
选择较大尺寸的chunk(64M),总体来说利大于弊,
1总得chunk块数变得少了,整体的粒度变得比较大,也和GFS的设计背景比较吻合。
2节省了与Master结点进行通信的次数,降低了网络的负载。
当然大chunk也有缺陷,比如存储的小文件可能在一个chunk上,要是对小文件进行连续多次的读写,这里可能变成热点,但显然,结合背景,主要存储的文件都是大文件的,因此这个缺点不是主要考虑的,当然还是不可避免的,为了降低服务器的负载,可以采用其他手段,比如允许从其他主机上读取数据。
Master节点与客户端节点会有周期性的心跳信号进行通信连接(Master传递指令信息chunkserver返回运行状态)。
客户通过文件名+偏移的方式访问文件,客户端的服务会根据chunk的大小将偏移转化成文件的chunk索引,把这个索引发给Master,Master从它具体管理的表中把相关的信息返回(chunk的具体位置以及副本信息)客户端拿着这个索引去对应的chunk服务器中找到对应的文件,直接与chunk服务器进一步联系(会选择一个最近的chunk server),获取文件信息。避免与master结点再次通信,Master结点返回的信息可能会缓存在本地的客户端中,这样可以节省master结点的负担。
2.2一致性模型
一致性模型是比较难理解的部分。
一致性模型大概意义上可以理解为,Master对于namespace的修改具有原子性。Namespace在逻辑上可以理解为一张查找表,可以将路径名元员数据相映射起来。
大致上感觉还是并发执行的时候的同步与互斥的问题,比如两个用户同时写入同一个文件区域,或者一个用户读文件的时候另一个用户写入相同的文件区域,一致性就就是要保证在这种情况下避免数据读写错误。
当一个数据修改成功,所有的副本上都有一致的信息,这个修改就是defined类型的,表示修改成功,若客户端在副本上读出不同的信息,这个修改就是undefined类型的。
GFS用以下手段保证一致性的实现:
1对chunk的所有副本的修改操作顺序一致(lease租约)
2使用chunk版本号来检测chunk服务器是否因为宕机而错过了修改,已经失效的副本不会再进行任何方式的修改,master不会再给信息到这个副本,它们会被垃圾回收机制回收。(Master对版本号的控制在后面有具体介绍)
因为客户端要缓存chunk的位置信息,可能返回的是一个失效的chunk, 在缓存的超时时间和文件下一次被打开的时间之间存在一个时间窗(时间间隔),文件再次被打开后会清除缓存中与该文件有关的所有Chunk位置信息。
GFS通过Master服务器和所有Chunk服务器的定期“握手” 来找到失效的Chunk服务器,并且使用Checksum机制来校验数据是否损坏。一旦发现问题,数据要尽快利用有效的副本进行恢复。
从程序实现的角度来说使用以下机制可以更好地实现一致性:
1 采用追加写入而不是覆盖的方式
2 checkingpoint机制(每条数据追加写入的时候都包含一些额外的检验信息)
3 写时自检验自表示记录等等方式
3系统交互
系统交互部分需要考虑的一个主要原则就是最小化Master结点的管理负担。
3.1租约(lease)以及数据更改(mutation)
Mutation指的是实际内容或者元数据的改变,包括追加操作或者改写操作。
Lease是某个更改的序列
由于所有的副本要保持同样的信息,因此每个内容变化的mutation要在所有的副本上进行。先由master选择一个chunkserver作为主服务器primary server,之后在这个主服务器上记录着一个更新的序列(即使租约lease)。
Primary server与master之间通过心跳信号传递信息,这个的主要目的是为了简化master的负担,只要通过primary server就可以继续更新其他的server。即使master与primary的连接中断,还可以再选在一个chunk server作为新的primary server。
3.2主要流程以及数据流
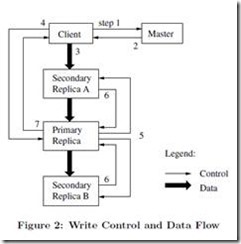
以写入操作为例:
1客户端问master 当前的primary server是哪一台(持有租约的那个)。
2 Master将primary server以及其他chunkserver的位置信息一并返回,客户端可能将这些信息缓存,减少未来对于master的访问量。
3 客户端将需要写入的信息以任意的顺序由推送给所有的服务器
4 一旦所有的服务器都确认收到了信息,客户端向primaryserver发出写命令,命令可以区别出先前推送给所有副本的信息。因为可能有多个客户端同时发出写命令,主服务器必须用连续的序号来区别它们。
5主服务器将所有的请求提交给其他服务器。
6其他服务器完成操作后,向主服务器发送确认。
7主服务器通知master结点,确认完成,或者发送错误某个结点没有写成功的错误信息。
基本上主服务器在这个过程中成了Master的一个代理,替Master完成了对所有副本进行数据修改的工作。
根据图中的标出容易看出,数据流与控制流进行了解耦,这样可以更大程度上利用带宽。
数据流沿着某个固定的链在服务器之间传递,并不是使用拓扑的方式同时向多个服务器传送,并且每次都找离自己最近的一个chunk服务器传送信息,并且采用了TCP连接的、管道式的数据推送方式来最小化时延。
3.3原子记录追加以及快照
这个部分基本上是借鉴了LINUX操作系统中的一些好的设计思路。
原子记录追加操作的核心思想是LINUX的O_Append方式。每次数据追加都在末尾进行,保证数据作为整体单元至少写入一次,只要保证二级chunk服务器与主chunk服务器每次写入的位置一样就可以了,但在字节层面不保证所有的chunk服务器中的内容完全一致。
所谓快照(snapshot)就是以很短的时间对原来目录树或者是其他的资源进行一个复制,实际上这里并不是物理意义上的复制,整个过程类似于LINUX中的copy-on-write策略,大致理解上,就是仅仅给相应的部分添加一个引用,等到真正需要修改的时候,才对需要修改的某个区域进行真正的复制,再去修改,即是说把真正的复制过程推迟到了具体修改的时候,若是仅仅是读操作的话,并不进行物理上的复制。
4 master结点的相关操作
Master结点似乎像一个总管一样,执行一些全局性的操作:
1执行所有的命名空间操作
2在整个系统的范围内安排chunk server,决定他它们的位置,创建新的chunk来保存副本,保持每个chunk都有副本存在,平衡整个系统的负载。
3回收不被使用的存储空间
命名空间在逻辑上被描述成一张查找表,将路径名与元数据进行相互映射。为了提高master的效率,有些修改操作要并行,为了防止冲突,利用命名空间的区域锁机制,在修改过程中在不同的目录级别上创建读写锁,来保证在某些点的串行,避免修改发生冲突。
Chunk副本位置选择的策略服务两大目标:最大化数据可靠性和可用性,最大化网络带宽利用率,为了实现这两个目标,副本不仅要跨服务器存储,还要跨机架存储。
当遇到以下情况时,chunk副本会被创建:新创建一个chunk、重新复制chunk、以及系统负载均衡。在每一种情况下的创建操作都要遵循一些原则。
新创建chunk的时候,希望将副本放在一个硬盘利用率低于平均水平的服务器中,在某一段时间内,限制在一个服务器中chunk创建的数目,最好能跨机架,这些也都是出于负载均衡和稳定性的考虑。
可能由于一些原因,会导致副本丢失,要是同时有好多数据的副本丢失,要重新创建哪一个?这其中涉及到一些优先级设置的规则,比如两个副本都丢失的比一个副本丢失的优先级要更高。
Master结点还会周期性地进行负载均衡,检查当前所有副本的分布状况,并进行移动,更好地利用硬盘的空间。
当文件被删除之后,GFS采用懒惰的回收策略,并没有立即回收对应的硬盘空间,而是将对应的删除操作记录下来,放在一个隐藏区域。在master对chunk结点的定期扫描中,会将相关过期在隐藏区的元数据删除,这样就相当于切断了master结点与对应要删除信息之间的联系。这样相对应的chunk就变成了“孤儿结点”,在定期的与master的信号交互中,所有不能被master识别的chunk都会被视为垃圾进行回收。
Master结点用版本号来判断一个chunk是否过期,每签订一个新的租约,所有chunk副本的版本号就更新一次,Master结点在定期的检测中也会对失效的副本进行移除。
5.高可用性的相关机制
GFS的一个设计前提就认为组件失效是经常发生的。
高可用性的基本策略是快速恢复和复制。不论是正常终止还是异常终止,Master结点和chunk服务器都被设计成在几秒之内就能重新启动。无论是chunk服务器还是Master结点,都有自己的复制策略。
由于并非所有的额chunk服务器在字节层面都是一致的,每个chuk服务器必须要独立保持自身数据的完整性,有一些对应的检错机制,比如设置对应的检验字段。
GFS还需要记录较详细的诊断日志,帮助我们更好地进对问题进行分析。
6.其他
论文在最后,在两个实际的集群上进行了小规模的基准测试,对论文中提到的一些原则进行性了验证,讨论了集群实际表现出的性能和理论性能之间的差异。
参考:
1 http://www.open-open.com/lib/view/open1328763454608.html
2 http://www.importnew.com/3491.html
3 Ghemawat S, Gobioff H, Leung S T. The Google file system[C]//ACM SIGOPS Operating Systems Review. ACM, 2003, 37(5): 29-43.
4 O_Append无锁文件的追加方式http://tomyz0223.iteye.com/blog/724820
5 copy on write:
http://www.cnblogs.com/chenglei/archive/2009/08/06/1540175.html
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/20/2601655.html
Google File System 论文阅读笔记的更多相关文章
- The Google File System论文拜读
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google∗ 摘要 我们设计并实现了谷歌文件系统 ...
- The Google File System——论文详解(转)
“Google文件存储系统(GFS)是构建在廉价服务器之上的大型分布式系统.它将服务器故障视为正常现象,通过软件方式自动容错,在保证系统可用性和可靠性同时,大大降低系统成本. GFS是Google整个 ...
- Google file system
读完了Google file system论文的中文版,记录一下总结,懒得打字,直接上草图:
- 《The Google File System》论文阅读笔记——GFS设计原理
一.设计预期 设计预期往往针对系统的应用场景,是系统在不同选择间做balance的重要依据,对于理解GFS在系统设计时为何做出现有的决策至关重要.所以我们应重点关注: 失效是常态 主要针对大文件 读操 ...
- 经典论文翻译导读之《Google File System》(转)
[译者预读] GFS这三个字母无需过多修饰,<Google File System>的论文也早有译版.但是这不妨碍我们加点批注.重温经典,并结合上篇Haystack的文章,将GFS.TFS ...
- 《The Google File System》论文研读
GFS 论文总结 说明:本文为论文 <The Google File System> 的个人总结,难免有理解不到位之处,欢迎交流与指正 . 论文地址:GFS Paper 阅读此论文的过程中 ...
- 《The Google File System》 笔记
<The Google File System> 笔记 一.Introduction 错误是不可避免的,应当看做正常的部分而不是异常.因此需要设计持续监控,错误检查,容错,自动恢复的系统. ...
- 大数据理论篇HDFS的基石——Google File System
Google File System 但凡是要开始讲大数据的,都绕不开最初的Google三驾马车:Google File System(GFS), MapReduce,BigTable. 为这一切的基 ...
- 谷歌三大核心技术(一)The Google File System中文版
谷歌三大核心技术(一)The Google File System中文版 The Google File System中文版 译者:alex 摘要 我们设计并实现了Google GFS文件系统,一个 ...
随机推荐
- python 更快地判断数字的奇数还是偶数
使用 按位与运算符(&) 将能更加快速地判断一个整数是奇数还是偶数 使用举例如下: def check_number(n): if n & 1: return '奇数' else: r ...
- JavaScript之基础语法
第一章 javascript语法 一, js代码的引入 方式一:在html页写js代码 <script> alert('hello,world') </script> 方式二: ...
- Python 中三大框架各自的应用场景??
django:主要是用来搞快速开发的,他的亮点就是快速开发,节约成本,正常的并发量不过 10000,如果要实现高并发的话,就要对 django 进行二次开发,比如把整个笨重的框架给拆掉,自己写 soc ...
- 如何在CentOS 7上安装Yarn
Yarn是与npm兼容的JavaScript软件包管理器,可帮助自动化安装,更新,配置和删除npm软件包的过程. 它的创建是为了解决npm的一系列问题,例如通过并行化操作并减少与网络连接有关的错误来加 ...
- overflow的量两种模式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 前端开发HTML&css入门——CSS的文本格式化
长度单位 像素 px 百分比 % em - 像素是我们在网页中使用的最多的一个单位, * 一个像素就相当于我们屏幕中的一个小点, * 我们的屏幕实际上就是由这些像素点构成的 * 但是这些像素点,是不能 ...
- vue.js(16)--vue的组件
注册一个全局组件 <div id="app"> <test></test> </div> <script> // 注册全 ...
- 深入JavaScript之获取cookie以及删除cookie
cookie存在哪? 存在document.cookie中 ookie长啥样? cookie是一个字符串,长下面这样:“name=xxx; age=22;” 注意:分号后面有个空格,记住这一点,下面的 ...
- linux下挂载U盘方法
1.使用 cat /proc/partitions 查看系统现在有哪些分区:[root@localhost ~]# cat /proc/partitions major minor #blocks ...
- Manjaro美化 配置教程
Manjaro Linux的美化 切换源 sudo vi /etc/pacman.conf 加入arch源 [archlinuxcn] SigLevel = Optional TrustedOnly ...