Java 实现《编译原理》简单词法分析功能 - 程序解析
Java 实现《编译原理》简单词法分析功能 - 程序解析
简易词法分析功能
要求及功能
(1)读取一个 txt 程序文件(最后的 # 作为结束标志,不可省去)
{
int a, b;
a = 10;
if(a>=1){
b = a + 20;
}
}
#
(2)词法识别分析表
| 单词类别 | 单词自身值 | 内部编码 |
|---|---|---|
| 关键字 | int、for、while、do、return、break、continue | 1 |
| 标识符 | 除关键字外的以字母开头,后跟字母、数字的字符序列 | 2 |
| 常数 | 无符号整型数 | 3 |
| 运算符 | +、-、*、/、>、<、=、>=、<=、!= | 4 |
| 界限符 | ,、;、{、}、(、) | 5 |
| 换行符 | \n | 6 |
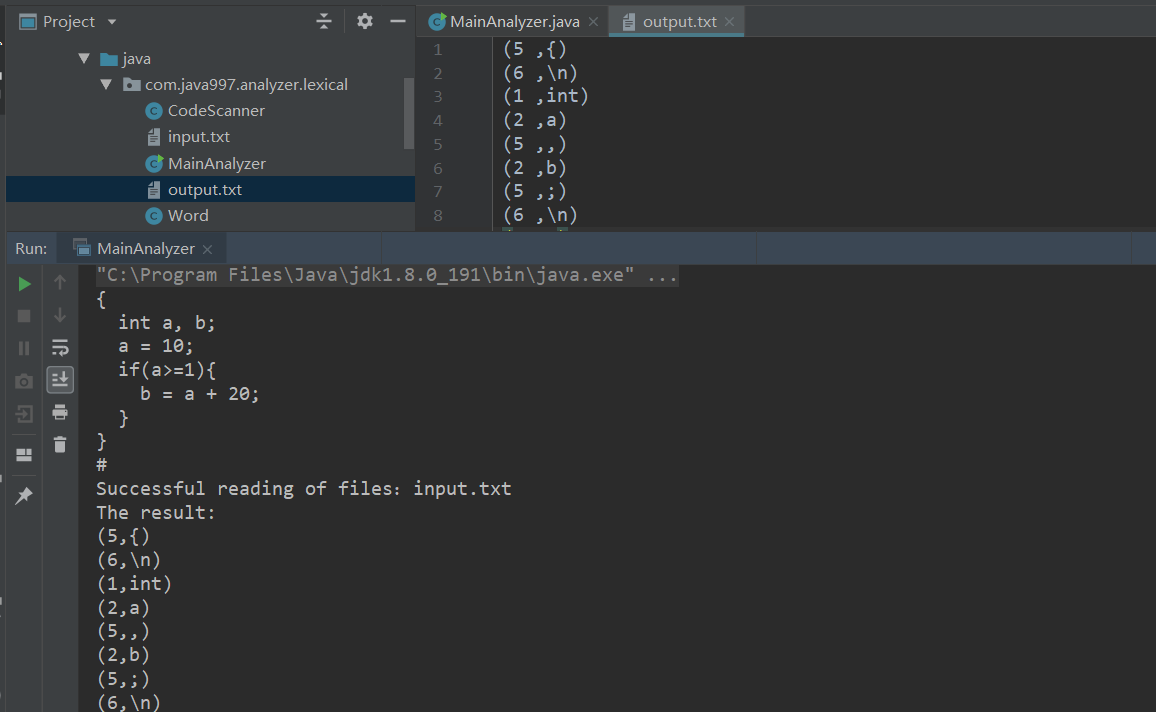
(3)输出结果:
(5,{)
(6,\n)
(1,int)
(2,a)
(5,,)
(2,b)
(5,;)
(6,\n)
(2,a)
(4,=)
(3,10)
(5,;)
(6,\n)
(2,if)
(5,()
(2,a)
(4,>=)
(3,1)
(5,))
(5,{)
(6,\n)
(2,b)
(4,=)
(2,a)
(4,+)
(3,20)
(5,;)
(6,\n)
(5,})
(6,\n)
(5,})
(6,\n)
(0,#)
并保存成新的 txt 文件
编程实现
(1)程序文件目录:
(2)Word.java 文件:
package com.java997.analyzer.lexical;
/**
* <p>
* 表示识别后的词实体类
*
* @author XiaoPengwei
* @since 2019-06-13
*/
public class Word {
/**
* 种别码
*/
private int typeNum;
/**
* 扫描得到的词
*/
private String word;
public int getTypeNum() {
return typeNum;
}
public void setTypeNum(int typeNum) {
this.typeNum = typeNum;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
}
(3)CodeScanner.java 文件:
package com.java997.analyzer.lexical;
/**
* <p>
* 字符扫描
*
* @author XiaoPengwei
* @since 2019-06-13
*/
public class CodeScanner {
private static String _KEY_WORD_END = "end string of string";
private int charNum = 0;
private Word word;
private char[] input = new char[255];
private char[] token = new char[255];
private int p_input = 0;
private int p_token = 0;
private char ch;
/**
* 关键字数组
*/
private String[] rwtab = {"int", "if", "while", "do", "return", "break", "continue", _KEY_WORD_END};
/**
* 逻辑运算数组
*/
private String[] logicTab = {"==",">=","<=","!=", _KEY_WORD_END};
public CodeScanner(char[] input) {
this.input = input;
}
/**
* 取下一个字符
*
* @return
*/
public char m_getch() {
if (p_input < input.length) {
ch = input[p_input];
p_input++;
}
return ch;
}
/**
* 如果是标识符或者空白符就取下一个字符
*/
public void getbc() {
while ((ch == ' ' || ch == '\t') && p_input < input.length) {
ch = input[p_input];
p_input++;
}
}
/**
* 把当前字符和原有字符串连接
*/
public void concat() {
token[p_token] = ch;
p_token++;
token[p_token] = '\0';
}
/**
* 回退一个字符
*/
public void retract() {
p_input--;
}
/**
* 判断是否为字母
*
* @return boolean
* @author XiaoPengwei
*/
public boolean isLetter() {
return ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z';
}
/**
* 判断是否为数字
*
* @return boolean
* @author XiaoPengwei
*/
public boolean isDigit() {
return ch >= '0' && ch <= '9';
}
/**
* 查看 token 中的字符串是否是关键字,是的话返回关键字种别编码,否则返回 2
*
* @return
*/
public int isKey() {
int i = 0;
while (rwtab[i].compareTo(_KEY_WORD_END) != 0) {
if (rwtab[i].compareTo(new String(token).trim()) == 0) {
return i + 1;
}
i++;
}
return 2;
}
/**
* 可能是逻辑预算字符
*
* @return
*/
public Boolean isLogicChar() {
return ch == '>' || ch == '<'|| ch == '='|| ch == '!';
}
/**
* 查看 token 中的字符串是否是逻辑运算符,是的话返回关键字种别编码,否则返回 2
*
* @return
*/
public int isLogicTab() {
int i = 0;
while (logicTab[i].compareTo(_KEY_WORD_END) != 0) {
if (logicTab[i].compareTo(new String(token).trim()) == 0) {
return i + 1;
}
i++;
}
return 4;
}
/**
* 能够识别换行,单行注释和多行注释的
* 换行的种别码设置成30
* 多行注释的种别码设置成31
*
* @return
*/
public Word scan() {
token = new char[255];
Word myWord = new Word();
myWord.setTypeNum(10);
myWord.setWord("");
p_token = 0;
m_getch();
getbc();
if (isLetter()) {
while (isLetter() || isDigit()) {
concat();
m_getch();
}
retract();
myWord.setTypeNum(isKey());
myWord.setWord(new String(token).trim());
return myWord;
} else if (isLogicChar()) {
while (isLogicChar()) {
concat();
m_getch();
}
retract();
myWord.setTypeNum(4);
myWord.setWord(new String(token).trim());
return myWord;
} else if (isDigit()) {
while (isDigit()) {
concat();
m_getch();
}
retract();
myWord.setTypeNum(3);
myWord.setWord(new String(token).trim());
return myWord;
} else {
switch (ch) {
//5
case ',':
myWord.setTypeNum(5);
myWord.setWord(",");
return myWord;
case ';':
myWord.setTypeNum(5);
myWord.setWord(";");
return myWord;
case '{':
myWord.setTypeNum(5);
myWord.setWord("{");
return myWord;
case '}':
myWord.setTypeNum(5);
myWord.setWord("}");
return myWord;
case '(':
myWord.setTypeNum(5);
myWord.setWord("(");
return myWord;
case ')':
myWord.setTypeNum(5);
myWord.setWord(")");
return myWord;
//4
case '=':
myWord.setTypeNum(4);
myWord.setWord("=");
return myWord;
case '+':
myWord.setTypeNum(4);
myWord.setWord("+");
return myWord;
case '-':
myWord.setTypeNum(4);
myWord.setWord("-");
return myWord;
case '*':
myWord.setTypeNum(4);
myWord.setWord("*");
return myWord;
case '/':
myWord.setTypeNum(4);
myWord.setWord("/");
return myWord;
case '\n':
myWord.setTypeNum(6);
myWord.setWord("\\n");
return myWord;
case '#':
myWord.setTypeNum(0);
myWord.setWord("#");
return myWord;
default:
concat();
myWord.setTypeNum(-1);
myWord.setWord("ERROR INFO: WORD = \"" + new String(token).trim() + "\"");
return myWord;
}
}
}
}
(4)MainAnalyzer.java 文件:
package com.java997.analyzer.lexical;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.ArrayList;
import java.util.Scanner;
/**
* <p>
* 执行主程序
*
* @author XiaoPengwei
* @since 2019-06-13
*/
public class MainAnalyzer {
private File inputFile;
private File outputFile;
private String fileContent;
private ArrayList<Word> list = new ArrayList<>();
/**
* 构造方法
*
* @param input
* @param output
* @author XiaoPengwei
*/
public MainAnalyzer(String input, String output) {
//实例化输入文件
inputFile = new File(input);
//实例化输出文件
outputFile = new File(output);
}
/**
* 从指定的 txt 文件中读取源程序文件内容
*
* @return java.lang.String
*/
public String getContent() {
StringBuilder stringBuilder = new StringBuilder();
try (Scanner reader = new Scanner(inputFile)) {
while (reader.hasNextLine()) {
String line = reader.nextLine();
stringBuilder.append(line + "\n");
System.out.println(line);
}
System.out.println("Successful reading of files:" + inputFile.getName());
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return fileContent = stringBuilder.toString();
}
/**
* 然后扫描程序,在程序结束前将扫描到的词添加到 list 中
* 最后把扫描结果保存到指定的文件中
*
* @param fileContent
* @return void
*/
public void analyze(String fileContent) {
int over = 1;
Word word = new Word();
//调用扫描程序
CodeScanner scanner = new CodeScanner(fileContent.toCharArray());
System.out.println("The result:");
while (over != 0) {
word = scanner.scan();
System.out.println("(" + word.getTypeNum() + "," + word.getWord() + ")");
list.add(word);
over = word.getTypeNum();
}
saveResult();
}
/**
* 将结果写入到到指定文件中
* 如果文件不存在,则创建一个新的文件
* 用一个 foreach 循环将 list 中的项变成字符串写入到文件中
*/
public void saveResult() {
//创建文件
if (!outputFile.exists()) {
try {
outputFile.createNewFile();
} catch (IOException e1) {
e1.printStackTrace();
}
}
//写入文件
try (Writer writer = new FileWriter(outputFile)) {
for (Word word : list) {
writer.write("(" + word.getTypeNum() + " ," + word.getWord() + ")\n");
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
//注意输入文件路径/名称必须对, 输出文件可以由程序创建
MainAnalyzer analyzer = new MainAnalyzer("D:\\analyzer\\src\\main\\java\\com\\java997\\analyzer\\lexical\\input.txt", "D:\\analyzer\\src\\main\\java\\com\\java997\\analyzer\\lexical\\output.txt");
analyzer.analyze(analyzer.getContent());
}
}
(5)input.txt 文件:
{
int a, b;
a = 10;
if(a>=1){
b = a + 20;
}
}
#
执行测试
Java 实现《编译原理》简单词法分析功能 - 程序解析的更多相关文章
- Java的编译原理
概述 java语言的"编译期"分为前端编译和后端编译两个阶段.前端编译是指把*.java文件转变成*.class文件的过程; 后端编译(JIT, Just In Time Comp ...
- 深入分析Java的编译原理
在<Java代码的编译与反编译>中,有过关于Java语言的编译和反编译的介绍.我们可以通过javac命令将Java程序的源代码编译成Java字节码,即我们常说的class文件.这是我们通常 ...
- 编译原理简单语法分析器(first,follow,分析表)源码下载
编译原理(简单语法分析器下载) http://files.cnblogs.com/files/hujunzheng/%E5%8A%A0%E5%85%A5%E5%90%8C%E6%AD%A5%E7%AC ...
- .Net编译原理简单介绍
首先简单说一下计算机软件运行.所谓软件运行,就是一步一步做一些事情.计算机只认识0和1.给计算机下命令,只能是0与1的方式,确切的说,其实是CPU只认识0和1,因为软件运行是CPU控制的.人直接操作0 ...
- Java网络编程以及简单的聊天程序
网络编程技术是互联网技术中的主流编程技术之一,懂的一些基本的操作是非常必要的.这章主要讲解网络编程,UDP和Socket编程,以及使用Socket做一个简单的聊天软件. 全部代码下载:链接 1.网络编 ...
- Net编译原理简单
转载:http://blog.csdn.net/sundacheng1989/article/details/20941893 首先简单说一下计算机软件运行.所谓软件运行,就是一步一步做一些事情.计算 ...
- Java continue break 制作简单聊天室程序,屏蔽不文明语言,显示每句话聊天时间 for(;;) SimpleDateFormat("yyyy-MM-dd hh:mm:ss") equalsIgnoreCase
package com.swift; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Scanne ...
- Java注解及其原理以及分析spring注解解析源码
注解的定义 注解是那些插入到源代码中,使用其他工具可以对其进行处理的标签. 注解不会改变程序的编译方式:Java编译器对于包含注解和不包含注解的代码会生成相同的虚拟机指令. 在Java中,注解是被当做 ...
- Java中JSON的简单使用与前端解析
http://www.blogjava.net/qileilove/archive/2014/06/13/414694.html 一.JSON JSON(JavaScript Object Notat ...
随机推荐
- MFC中png格式图片贴图的实现
MFC中png格式图片贴图的实现(2011-07-14 19:10:29) ___转载自新浪 初学vc,正在做五子棋,五子棋中的图片格式都是bmp格式的,所以贴图用CBitmap可以很简单的实现.刚 ...
- 【ABAP系列】SAP ABAP 带有参数的AMDP的创建
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP ABAP 带有参数的AM ...
- webdriervAPI(常用的js方法)
from selenium import webdriver driver = webdriver.Chorme() driver.get("http://www.baidu.co ...
- 【转贴】Windows常用命令实例
Windows常用命令实例 https://www.cnblogs.com/linyfeng/p/6261629.html 熟练使用DOS常用命令有助于提高工作效率. 1.windows+R:打开运行 ...
- 【案例分享】在 React 框架中使用 SpreadJS 纯前端表格控件
[案例分享]在 React 框架中使用 SpreadJS 纯前端表格控件 本期葡萄城公开课,将由国电联合动力技术有限公司,资深前端开发工程师——李林慧女士,与大家在线分享“在 React 框架中使用 ...
- 【转】在C#中使用Json.Net进行序列化和反序列化及定制化
作者:Minotauros 原文地址:在C#中使用Json.Net进行序列化和反序列化及定制化 序列化(Serialize)是将对象转换成字节流,并将其用于存储或传输的过程,主要用途是保存对象的状态, ...
- spark教程(15)-Streaming
Spark Streaming 是一个分布式数据流处理框架,它可以近乎实时的处理流数据,它易编程,可以处理大量数据,并且能把实时数据与历史数据结合起来处理. Streaming 使得 spark 具有 ...
- The minimal unique substring CodeForces - 1159D (构造)
核心观察是形如01,001,0001,...的串循环时, $n$每增长1, $k$就增长1. #include <iostream> #include <sstream> #i ...
- js制作秒表
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- 第二章 单表查询 T-SQL语言基础(3)
单表查询(3) 2.6 处理字符数据 字符数据的查询处理,内容包括:类型,排序规则,运算符和函数,以及模式匹配. 2.6.1 数据类型 SQL Server支持两种字符数据类型----普通字符和Uni ...