说说 HeapSort 堆排序思想,以及个人优化方案。(老物)
听说你要排上亿个数据之 HeapSort ?
前言 : 来来来,今天我们来说说一个用来排大量数据所用的基础比较排序吧~
注:阅读本文学习新技能的前置要求为:了解什么是二叉树及其数组性质,如果未达到要求的同学请直接看完图默默点右上角的×就好=- =~
在那之前我们先来看一个图
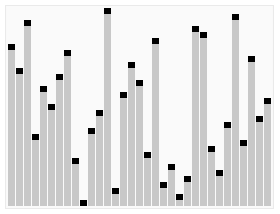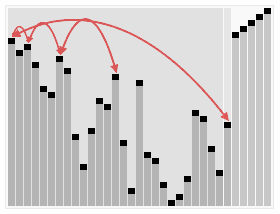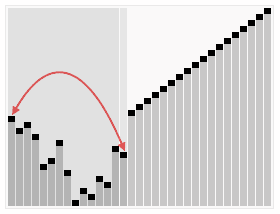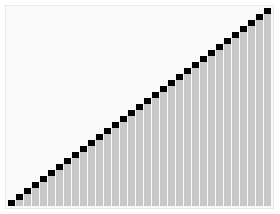
嗯,是不是很好玩?这玩意就是所谓的 HeapSort (堆排序)
而我们今天就来说说怎么像图例所示那样来进行我们的排序操作吧~
所谓的 HeapSort 呢,就是在一直做一件事,这件事用高雅点的名词就叫: HeapAdjust (调整最大堆)
在说明最大堆之前先提问,什么是堆呢?
沙堆,土堆,石堆,这些事物的特点是什么呢?
就好比金字塔,内容物是从底下到顶逐渐减少的.而我所说的最大堆,就是在说这样的一种堆
并且其最大堆的内容物(沙土石头或称 Key )呈现出其堆顶的价值(数值)最大,然后向下逐级递减.
那么,怎么产生这样的最大堆呢?
下面我贴一段来自于百度百科的代码吧~
百度百科 - 堆排序
// array 是待调整的堆数组, i 是待调整的数组元素的位置, length 是数组的长度
// 本函数功能是:根据数组 array 构建大根堆
void HeapAdjust(int array[], int i, int length)
{
for(int Child, Temp; 2 * i + 1 < length; i = Child)
{
//子结点的位置 = 2 *(父结点位置)+ 1
Child = 2 * i + 1;
//得到子结点中较大的结点
if(Child + 1 < length && array[Child + 1] > array[Child]) ++Child;
//如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点
if(array[i] < array[Child]) Temp = array[i], array[i] = array[Child], array[Child] = Temp;
//否则退出循环
else break;
}
}
//堆排序算法
void HeapSort(int array[], int length)
{
int i;
// 调整序列的前半部分元素,调整完之后第一个元素是序列的最大的元素
// length / 2 - 1 是最后一个非叶节点,此处"/"为整除
for(i = length / 2 - 1; i >= 0; --i) HeapAdjust(array, i, length);
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for(i = length - 1; i > 0; --i)
{
// 把第一个元素和当前的最后一个元素交换,保证当前的最后一个位置的元素都是在现在的这个序列之中最大的
array[i] ^= array[0], array[0] ^= array[i], array[i] ^= array[0];
// 不断缩小调整heap的范围,每一次调整完毕保证第一个元素是当前序列的最大值
HeapAdjust(array, 0, i);
}
}
所有要做的工作就在这里面,看上去是挺精简的了我觉得=- =.
那我们来说说它是怎么工作的吧~
首先 HeapSort 这个函数要做第一次预处理工作,这个工作的目的就是要把这个数组调整为最大堆
即倒序执行 HeapAdjust
但是并不是倒数第一个开始执行,而是倒数第二层中存在子节点的树结点开始(length / 2 - 1)。
这是什么意思呢?
这是因为HeapAdjust操作原理为:
首先选出其左右结点中较大的结点,然后将其与其父结点相比较,若大于则Swap之(此时构建最大堆).
然后对当前子结点执行上面的重复操作.
好的,当倒序到0的时候,就成功将这个最大堆建立起来了,现在需要做什么呢?
现在已知的条件是,顶端为这个堆的最大值,那么,这个最大值与数组最后一个元素交换(边界减一),
但此时这个最大堆又需要重新维护了,接着怎么做呢?
这时候就要立刻请出 HeapAdjust 大人,你要告诉它,你要调整的元素位置和它的边界。
让它把当前这个元素重新再调整为最大值,嗯,至此,感谢万能的 HeapAdjust 大人。
好吧,这就是堆排序的所有操作思想了.
至此,该篇已经结束,下面的是我个人的隐藏内容(/w \)(真有人会看到这里?没在开我玩笑吧~)
能看到这里的同学基本都是深爱着计算机的同学了,既然能看到这里,就让我来说点细节的问题吧~
其实,百度百科提供的代码很LOW的,下面就放出我的代码吧~
void HeapAdjust(int arr[], int pos, int len)
{
int keypos = (pos << 1) + 1, KeyElement = arr[pos];//keypos 为其左子节点位置, KeyElement 为当前需要调整位置的元素.
while(keypos < len)//检查左子结点是否越界.
{
if (keypos + 1 < len && arr[keypos] < arr[keypos + 1]) keypos++;//若右结点存在且比左结点更大则替换
if (KeyElement > arr[keypos]) break;//若不存在比KeyElement更大的的子结点则中断调整位置
arr[pos] = arr[keypos], pos = keypos, keypos = (pos << 1) + 1;//将当前节点覆盖其父节点,同时更新当前结点为其子节点
}
arr[pos] = KeyElement;//最后确定位置后归位
}
到这里就是我的改进版,接着,还有牺牲空间 N 的进一步优化。
while (true)
{
//因数组数据特殊性,当树结点单枝时一定存在左结点(pos + 1 >= max),则pos不变动
if(arr[pos] < arr[pos + 1] && pos + 1 < max) pos++;//若右结点存在且大于则替换为右结点
//将进一步移动到其子节点
arr[pos - 1 >> 1] = arr[pos], pos = (pos << 1) + 1;
//left and right node all is zero to break;
if (pos > max || (!arr[pos] && !arr[pos + 1]))
{
//assume zero is side element
arr[pos - 1 >> 1] = 0;
break;
}
}
目前还没发现有人和我做一样的改进诶嘿嘿,改进的原理为:
将堆顶元素抽走,接着下面的左右子结点较大的元素将被提上来,最后到了底(边界)时,将其赋值为0,在这之后,但凡两子节点为 0 (side element) 时将中断进一步对其子节点调整的操作。
理论上分析,这种牺牲空间N的做法比传统的(大量重复的 HeapAdjust )更为节省操作,代价就只需要浪费 N 的空间来存放数据.
这里小小提及一下现在C++的 STL sort()
它采用的是 QuickSort、 HeapSort 、 InsertionSort 的结合
总称 Introsort (内省排序)。
本文最后真挚地感谢 LYC 小队的 Y 同学日夜陪我研究和折腾,还有修改,表示没有他一同参与我感觉会很乏味的说,至于 L 同学则跑去打机了,先前 Astar 把他玩坏了,还是给他自由玩耍的空间好了= -=~
本想把改进的代码发布到 wiki 的,但现在想想还是留在这个没人关注的空间等到某天用上了再让它面世吧 =- = ~
两年后,嗯,当年的我学的都是些啥玩意!
说说 HeapSort 堆排序思想,以及个人优化方案。(老物)的更多相关文章
- Heapsort 堆排序算法详解(Java实现)
Heapsort (堆排序)是最经典的排序算法之一,在google或者百度中搜一下可以搜到很多非常详细的解析.同样好的排序算法还有quicksort(快速排序)和merge sort(归并排序),选择 ...
- Adapter优化方案的探索
概要:使用Adapter的注意事项与优化方案本文的例子都可以在结尾处的示例代码连接中看到并下载,如果喜欢请star,如果觉得有纰漏请提交issue,如果你有更好的点子可以提交pull request. ...
- c#并行任务多种优化方案分享(异步委托)
遇到一个多线程任务优化的问题,现在解决了,分享如下. 假设有四个任务: 任务1:登陆验证(CheckUser) 任务2:验证成功后从Web服务获取数据(GetDataFromWeb) 任务3:验证成功 ...
- 五个Taurus垃圾回收compactor优化方案,减少系统资源占用
简介 TaurusDB是一种基于MySQL的计算与存储分离架构的云原生数据库,一个集群中包含多个存储几点,每个存储节点包含多块磁盘,每块磁盘对应一个或者多个slicestore的内存逻辑结构来管理. ...
- C++高并发场景下读多写少的优化方案
概述 一谈到高并发的优化方案,往往能想到模块水平拆分.数据库读写分离.分库分表,加缓存.加mq等,这些都是从系统架构上解决.单模块作为系统的组成单元,其性能好坏也能很大的影响整体性能,本文从单模块下读 ...
- Tomcat 配置详解/优化方案
转自:http://blog.csdn.net/cicada688/article/details/14451541 Service.xml Server.xml配置文件用于对整个容器进行相关的配置 ...
- 一个网站完整详细的SEO优化方案
根据自己的个人经验完成了这篇文章,希望对SEOer有点帮助,高手直接跳过,请勿喷水... 一个完整的SEO优化方案主要由四个小组组成: 一.前端/页编人员 二.内容编辑人员 三.推广人员 四.数据分析 ...
- mysql 性能优化方案
网 上有不少MySQL 性能优化方案,不过,mysql的优化同sql server相比,更为麻烦与复杂,同样的设置,在不同的环境下 ,由于内存,访问量,读写频率,数据差异等等情况,可能会出现不同的结果 ...
- iOS界面跳转的一些优化方案
原文地址: http://blog.startry.com/2016/02/14/Think-Of-UIViewController-Switch/ iOS界面跳转的一些优化方案 App应用程序开发, ...
随机推荐
- sqli-labs(32)
0x1查看源代码 (1)代码关键点 很明显,代码中利用正则匹配将 [ /,'," ]这些三个符号都过滤掉了 preg_replace 0x2 宽字符注入 (1)前言 在mysql中,用于转义 ...
- html初体验#1
html的一些自见解 html 5 自带语义化,就是让标签带上感情色彩,方便人或浏览器区分 <b></b>与<strong></strong>的区别 & ...
- Yii2.0简单隐藏index.php文件和模块配置和layout布局配置禁用和日志写入配置
隐藏index.php文件 目的:想去掉浏览器地址栏中的 index.php?r= 这一块. 在/config/web.php中 ’components'=>[] 中添加如下代码: 'u ...
- 地图服务 纬度、经度对应坐标轴x,y
记下,供自己参考,中国地区的经纬度,经度大,纬度小 如上海经纬度为:(经度, 纬度)(y, x)(lon, lat) 121.48 31.22 纬度---lat----x轴 经度---lon---y轴
- mysql学生成绩排名,分组取前 N 条记录
转载 https://blog.csdn.net/jslcylcy/article/details/72627762 score表: CREATE TABLE `score` ( `student_ ...
- word文档每章的页眉页脚设置
1. 每章后面插入分隔符,下一页. 2. 编辑页眉,取消选中链接的上一页,然后编辑页眉即可.
- rosbag 那些事
..bag文件转.txt 将file_name.bag文件中topic_name话题的消息转换到Txt_name.txt文件中: rostopic echo -b file_name.bag -p / ...
- idea中@data不生效
idea中@data不生效,原因是idea中没有安装插件,记得重启
- Unity—Compoent类
官方API->Componment 新引入成员 作用 字段 gameobject 该组件所在的游戏对象 tag 游戏对象的标签 Transform 添加在游戏对象上的transform组件 ...
- delphi将程序最小化至右下角
程序新手,如果有不恰当的地方,请大家帮忙改正! 1.下载并安装Raize.v5.5控件,delphi版本为:delphi 7.0. 2.添加RzTrayIcon控件.PopupMenu控件至窗体上. ...