数据处理之pandas库
1. Series对象
由于series对象很简单,跟数组类似,但多了一些额外的功能,偷个懒,用思维导图表示

2. DaraFrame对象
DataFrame将Series的使用场景由一维扩展到多维,数据结构跟Excel工作表极为相似,说白了就是矩阵
1. 定义DataFrame对象
DataFrame对象的构造分三部分:数据data,行标签index和列标签columns,下面给出三种构造方法
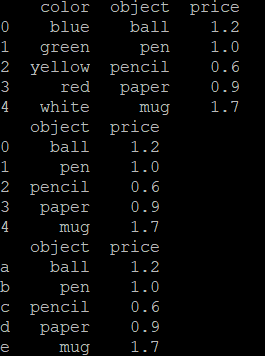
data = {'color':['blue','green','yellow','red','white'],
'object':['ball','pen','pencil','paper','mug'],
'price':[1.2,1.0,0.6,0.9,1.7]}
#构造DataFrame方法1
frame1 = pd.DataFrame(data)
print(frame1)
#构造DataFrame方法2
frame2 = pd.DataFrame(data,columns=['object','price'])
print(frame2)
#构造DataFrame方法3
frame3 = pd.DataFrame(data,columns=['object','price'],index=['a','b','c','d','e'])
print(frame3)
上面代码中的data可以为字典,ndarray和matrix对象
2. 选取元素
(1)获取行标(index)--->frame.index
(2)获取列标(columns)--->frame.columns
(3)获取数据结构中的所有元素 --->frame.values
(4)获取每一列的元素 --->frame['price']或frame.price
(5)获取dataframe中的行信息,可以使用ix方法的索引和数组方式或frame的切片方法
frame.ix[2] --->获取第3行的信息
frame.ix[[2,4]] --->获取第3行和第5行的信息
frame[1:3] --->获取索引为1和2的行信息
(6)获取指定cell元素 --->frame['price'][3]
(7)根据元素值进行筛选,比如:--->frame[frame < 12]
3. 赋值
通过选取元素同样的逻辑就能增加和修改元素
(1)修改指定元素的值 --->frame['price'][3] = 8.6
(2)增加新列new,指定每行的值都为12 --->frame['new'] = 12
(3)更新指定列的内容 --->frame['new'] = [1,2,3,4,5]
同样也可以使用Series对象为列赋值
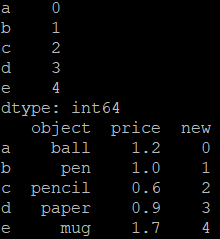
array = np.arange(5)
series = pd.Series(array,index=['a','b','c','d','e'])
print(series)
frame3['new'] = series
print(frame3)
输出:
4. 删除指定行和列
删除指定行和指定列都使用drop函数
例:
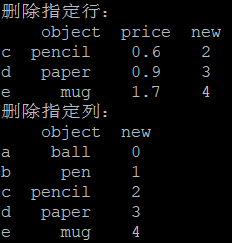
#删除标签为'a'和'b'的行
frame4 = frame3.drop(['a','b'],axis=0,inplace=False)
print('删除指定行:\n',frame4)
#删除标签为'price'的列
frame5 = frame3.drop(['price'],axis=1,inplace=False)
print('删除指定列:\n',frame5)
输出:
3. 统计函数
和:sum():
均值:mean()
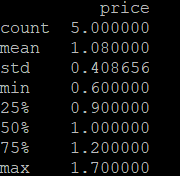
计算多个统计量:describe()
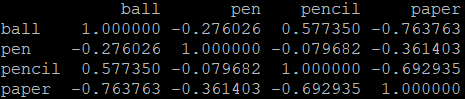
相关性:corr()
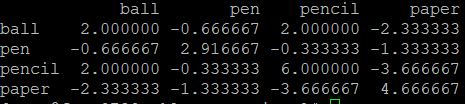
协方差:cov()
array = np.array([[1,4,3,6],[4,5,6,1],[3,3,1,5],[4,1,6,4]])
index = ['red','blue','yellow','white']
columns = ['ball','pen','pencil','paper']
frame = pd.DataFrame(array,index=index,columns=columns)
print(frame)
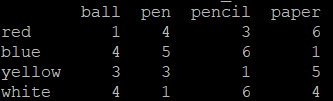
print(frame.corr())
print(frame.cov())
4. 数据筛选
a b c
(1)单条件筛选
df[df['a']>]
# 如果想筛选a列的取值大于30的记录,但是之显示满足条件的b,c列的值可以这么写
df[['b','c']][df['a']>]
# 使用isin函数根据特定值筛选记录。筛选a值等于30或者54的记录
df[df.a.isin([, ])]
(2)多条件筛选
可以使用&(并)与| (或)操作符或者特定的函数实现多条件筛选
# 使用&筛选a列的取值大于30,b列的取值大于40的记录
df[(df['a'] > ) & (df['b'] > )]
(3)索引筛选
a. 切片操作
df[行索引,列索引]或df[[列名1,列名2]]
#使用切片操作选择特定的行
df[:]
#传入列名选择特定的列
df[['a','c']]
b. loc函数
当每列已有column name时,用 df [ ‘a’ ] 就能选取出一整列数据。如果你知道column names 和index,且两者都很好输入,可以选择 .loc同时进行行列选择。
In []: df.loc[,'c']
Out[]: In []: df.loc[:,['a','c']]
Out[]:
a c In []: df.loc[[,,],['a','c']]
Out[]:
a c
c. iloc函数
如果column name太长,输入不方便,或者index是一列时间序列,更不好输入,那就可以选择 .iloc了,该方法接受列名的index,iloc 使得我们可以对column使用slice(切片)的方法对数据进行选取。这边的 i 我觉得代表index,比较好记点。
In []: df.iloc[,]
Out[]: In []: df.iloc[:,[,]]
Out[]:
a c In []: df.iloc[[,,],[,]]
Out[]:
a c In []: df.iloc[[,,],:]
Out[]:
a b
d. ix函数
ix的功能更加强大,参数既可以是索引,也可以是名称,相当于,loc和iloc的合体。需要注意的是在使用的时候需要统一,在行选择时同时出现索引和名称, 同样在同行选择时同时出现索引和名称。
df.ix[:,['a','b']]
Out[]:
a b In []: df.ix[[,,],['a','b']]
Out[]:
a b In []: df.ix[[,,],[,]]
Out[]:
a c
e. at函数
根据指定行index及列label,快速定位DataFrame的元素,选择列时仅支持列名。
In []: df.at[,'a']
Out[]:
f. iat函数
与at的功能相同,只使用索引参数
In []: df.iat[,]
Out[]:
5. csv操作
csv文件内容
Supplier Name,Invoice Number,Part Number,Cost,Purchase Date
Supplier X,-,,$500.00 ,//
Supplier X,-,,$500.00 ,//
Supplier X,-,,$750.00 ,//
Supplier X,-,,$750.00 ,//
Supplier Y,-,,$250.00 ,//
Supplier Y,-,,$250.00 ,//
Supplier Y,-,,$125.00 ,//
Supplier Y,-,,$125.00 ,//
Supplier Z,-,,$615.00 ,//
Supplier Z,-,,$615.00 ,//
Supplier Z,-,,$615.00 ,//
Supplier Z,-,,$615.00 ,//
(1)csv文件读写
关于read_csv函数中的参数说明参考博客:https://blog.csdn.net/liuweiyuxiang/article/details/78471036
import pandas as pd # 读写csv文件
df = pd.read_csv("supplier_data.csv")
df.to_csv("supplier_data_write.csv",index=None)
(2)筛选特定的行
#Supplier Nmae列中姓名包含'Z',或者Cost列中的值大于600
print(df[df["Supplier Name"].str.contains('Z')])
print(df[df['Cost'].str.strip('$').astype(float) > ])
print(df.loc[(df["Supplier Name"].str.contains('Z'))|(df['Cost'].str.strip('$').astype(float) > 600.0),:]) #行中的值属于某个集合
li = [,]
print(df[df['Part Number'].isin(li)])
print(df.loc[df['Part Number'].astype(int).isin(li),:]) #行中的值匹配某个模式
print(df[df['Invoice Number'].str.startswith("001-")])
(3)选取特定的列
#选取特定的列
#列索引值,打印1,3列
print(df.iloc[:,::])
#列标题打印
print(df.loc[:,["Invoice Number", "Part Number"]])
#选取连续的行
print(df.loc[:,:])
数据处理之pandas库的更多相关文章
- Python之Pandas库常用函数大全(含注释)
前言:本博文摘抄自中国慕课大学上的课程<Python数据分析与展示>,推荐刚入门的同学去学习,这是非常好的入门视频. 继续一个新的库,Pandas库.Pandas库围绕Series类型和D ...
- Python Pandas库的学习(三)
今天我们来继续讲解Python中的Pandas库的基本用法 那么我们如何使用pandas对数据进行排序操作呢? food.sort_values("Sodium_(mg)",inp ...
- Python Pandas库的学习(一)
今天我们来学习一下Pandas库,前面我们讲了Numpy库的学习 接下来我们学习一下比较重要的库Pandas库,这个库比Numpy库还重要 Pandas库是在Numpy库上进行了封装,相当于高级Num ...
- python 数据处理学习pandas之DataFrame
请原谅没有一次写完,本文是自己学习过程中的记录,完善pandas的学习知识,对于现有网上资料的缺少和利用python进行数据分析这本书部分知识的过时,只好以记录的形势来写这篇文章.最如果后续工作定下来 ...
- pandas库学习笔记(二)DataFrame入门学习
Pandas基本介绍——DataFrame入门学习 前篇文章中,小生初步介绍pandas库中的Series结构的创建与运算,今天小生继续“死磕自己”为大家介绍pandas库的另一种最为常见的数据结构D ...
- 第三周 数据分析之概要 Pandas库入门
Pandas库介绍: Pandas库引用:Pandas是Python第三方库,提供高性能易用数据类型和分析工具 import pandas as pd Pandas基于NumPy实现,常与NumPy和 ...
- Python之使用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写.首先我们需要了解点ORM方面的知识. ORM技术 对象关系映射技术,即ORM(Object-Relational ...
- Pandas库中的DataFrame
1 简介 DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表. 或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matla ...
- Python Pyinstaller打包含pandas库的py文件遇到的坑
今天的主角依然是pyinstaller打包工具,为了让pyinstaller打包后exe文件不至过大,我们的py脚本文件引用库时尽可能只引用需要的部分,不要引用整个库,多使用“from *** imp ...
随机推荐
- pyhton3 configparser模块
1 #!/usr/bin/env python 2 # coding=utf-8 3 __author__ = 'Luzhuo' 4 __date__ = '2017/5/26' 5 # config ...
- 【leetcode刷题笔记】Single Number II
Given an array of integers, every element appears three times except for one. Find that single one. ...
- PHP操作MongoDB数据库的示例
http://www.jquerycn.cn/a_8137 本节内容:PHP操作MongoDB数据库的简单示例. Mongodb的常用操作参看手册,php官方的http://us2.php.net/m ...
- Python编程-多态、封装、特性
一.多态与多态性 1.多态 (1)什么是多态 多态指的是一类事物有多种形态,(一个抽象类有多个子类,因而多态的概念依赖于继承) 序列类型有多种形态:字符串,列表,元组. 动物有多种形态:人,狗,猪 文 ...
- Shell编程之变量进阶
一.变量知识进阶 1.特殊的位置参数变量 实例1:测试$n(n为1...15) [root@codis-178 ~]# cat p.sh echo $1 [root@codis-178 ~]# sh ...
- 主攻ASP.NET.4.5.1 MVC5.0之重生:系统角色与权限(一)
数据结构 权限分配 1.在项目中新建文件夹Helpers 2.在HR.Helpers文件夹下添加EnumMoudle.Cs namespace HR.Helpers { public enum Enu ...
- Ubuntu 12.04下安装OpenCV 2.4.2
http://sourceforge.net/projects/opencvlibrary/files/ Ubuntu 12.04下安装OpenCV 2.4.2 http://blog.csdn.ne ...
- WINDOWS下好用的MongoDB 3.0以上客户端工具: NoSql Manager
WINDOWS下好用的MongoDB 3.0以上客户端工具: NoSql Manager https://www.mongodbmanager.com/download
- jupyter && ipython notebook简介
2017-08-19 最近用了一下 ipython notebook 也就是 jupyter,这里有一个介绍还不错: http://www.cnblogs.com/howiewang/p/jupyte ...
- Spring之rmi实例演示
环境介绍:本文中服务端客户端使用的都是ssm框架,配置文件分为spring_servlet.xml,spring_service.xml,mybatis.xml 在spring里面使用rmi完成远程调 ...