spark运行时出现Neither spark.yarn.jars nor spark.yarn.archive is set错误的解决办法(图文详解)
不多说,直接上干货!
福利 => 每天都推送
问题详情
每次提交spark任务到yarn的时候,总会出现uploading resource(打包spark jars并上传)到hdfs上。恶劣情况下,会在这里卡住很久。
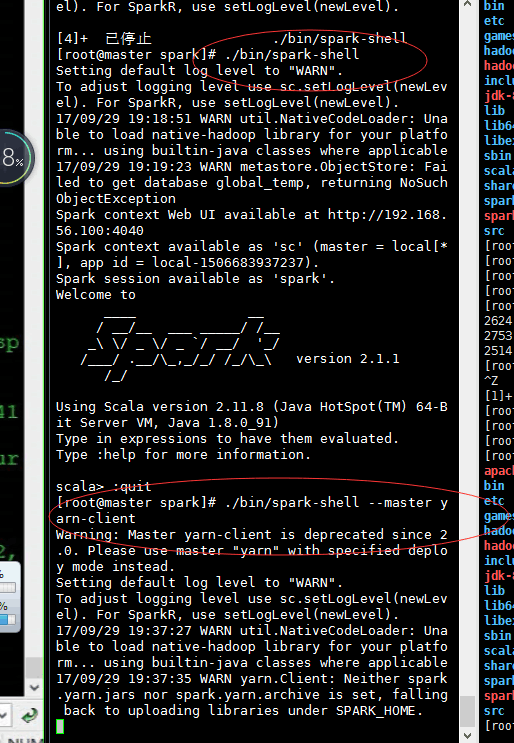
// :: INFO Client: Preparing resources for our AM container
// :: WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploadi
ng libraries under SPARK_HOME.
// :: INFO Client: Uploading resource file:/tmp/spark-28ebde0d-c77a-4be3--a6d3bcccc253/__spar
k_libs__7542776655448713545.zip -> hdfs://dipperCluster/user/hadoop/.sparkStaging/application_1484215273436_0
/__spark_libs__7542776655448713545.zip
// :: INFO Client: Uploading resource file:/tmp/spark-28ebde0d-c77a-4be3--a6d3bcccc253/__spar
k_conf__8972755978315292177.zip -> hdfs://dipperCluster/user/hadoop/.sparkStaging/application_1484215273436_0
/__spark_conf__.zip
其实可以发现,上图中,已经有提示了,说被弃用了。
解决办法1
在hdfs上创建目录:
hdfs dfs -mkdir /home/hadoop/spark_jars
上传spark的jars(spark1.6 只需要上传spark-assembly-1.6.0-SNAPSHOT-hadoop2.6.0.jar)
hdfs dfs -put /opt/spark/jars/* /home/hadoop/spark_jars/
在spark的conf的spark-default.conf ,添加如下的配置
spark.yarn.jars=hdfs://master:9000/opt/spark/jars/* /home/hadoop/spark_jars/
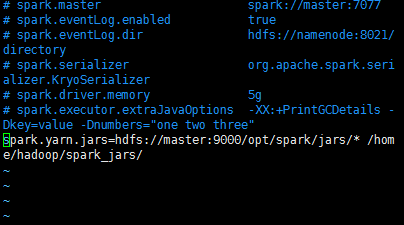
即可解决。不会出现这个问题。
当,再次启动时,则
Source and destination file systems are the same. Not copying hdfs://master:9000/home/hadoop/spark_jars/zookeeper-3.4.6.jar
之后快速开始提交任务,启动任务。
解决办法2
其实啊,说白了,就是spark2.1.0或spark2.2.0以上的版本的命令有所变化。所以压根可以需改动解决办法1所示的配置,直接用官网这样的命令来操作就可以了。
http://spark.apache.org/docs/latest/running-on-yarn.html

同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()




打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯
spark运行时出现Neither spark.yarn.jars nor spark.yarn.archive is set错误的解决办法(图文详解)的更多相关文章
- Spark Mllib里决策树回归分析如何对numClasses无控制和将部分参数设置为variance(图文详解)
不多说,直接上干货! 在决策树二元或决策树多元分类参数设置中: 使用DecisionTree.trainClassifier 见 Spark Mllib里如何对决策树二元分类和决策树多元分类的分类 ...
- Spark Mllib里决策树回归分析使用.rootMeanSquaredError方法计算出以RMSE来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型 ...
- ClouderManger搭建大数据集群时ERROR 2003 (HY000): Can't connect to MySQL server on 'ubuntucmbigdata1' (111)的问题解决(图文详解)
问题详情 相关问题的场景,是在我下面的这篇博客里 Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubun ...
- Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 协调过滤算法,是一种基于群体用户或者物品的典型推荐算法,也是目前常用的推荐 ...
- Spark Mllib里如何对决策树二元分类和决策树多元分类的分类数目numClasses控制(图文详解)
不多说,直接上干货! 决策树二元分类的分类数目numClasses控制 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类Stumble ...
- Spark Mllib里如何记录开始训练时间、完成训练时间、所需训练时间(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第16章 朴素贝叶斯二元分类算法来预测分类StumbleUpon数据集
- Spark Mllib里如何将trainDara训练数据文件里提取第M到第N字段(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类StumbleUpon数据集
- Spark Mllib里如何将数据集按比例随机地分成trainData、testData和validationData数据集(图文详解)
不多说,直接上干货! 具体详情见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第11章 电影推荐引擎
- Android SDK Manager检查更新时遇到Failed to fetch URL xxxxxxx reason: Connection to xxxxxx的错误的解决办法!
首先说明的是这个问题并不是每个人都存在,但是我和我的一个同学都有这种情况,所以我同学百度了一下,找出了解决办法. 问题描述: 使用Android SDK Manager检查在线更新,提示以下错误: & ...
随机推荐
- 异步串行通信的XON与XOFF
在单片机的异步串行通信中,putchar函数中的实现中反复用到了XON和XOFF,定义原型如下: #define XON 0x11#define XOFF 0x13 查找ASCII码表,这两个对应的是 ...
- mxnet 线性模型
mxnet 线性模型 li {list-style-type:decimal;}ol.wiz-list-level2 > li {list-style-type:lower-latin;}ol. ...
- oracle 中 创建序列sequence
drop sequence SEQ_YCXWP_CGD; create sequence SEQ_YCXWP_CGD increment start nomaxvalue;
- HackNine 避免在EditText中验证日期
1.概要: 为什么不直接为EditTText设置一个点击监听器,而非要使用Button呢? 答案是:使用Button更安全,因为用户无法修改Button的文本内容.如果使用EditTex ...
- cocos学习
第一章 JavaScript 快速入门 1.1 变量 在 JavaScript 中,我们像这样声明一个变量: var a; 保留字 var 之后紧跟着的,就是一个变量名,接下来我们可以为变量赋值: v ...
- 百度地图离线API及地图数据下载工具
全面介绍,请看下列介绍地址,改写目前最新版本的百度V2.0地图,已全面实现离线操作,能到达在线功能的95%以上 http://api.jjszd.com:8081/apituiguang/gistg. ...
- Qt中QBitmap 的使用 --QBitmap的作用
特别注意:如果想把做一个先把图画在内存中,在显示到页面,不要使用bitmap,这个只有单色: 一般情况下QBitmap只作为图片掩码使用,比如做不规则窗口. QBitmap表示一种只有黑白的单色图片, ...
- weblogic启动一闪而过
点击startWebLogic.cmd的时候,一闪而过 我的原因:JAVA_HOME中的路径是不能带有空格:我的电脑是64位的,jdk(32位)安装路径默认带有空格还有括号,所以重新装jdk,装在没有 ...
- 【Thread】线程工厂-ThreadFactory
ThreadFactory---线程工厂 在apollo源码中有这么一段代码 ExecutorService m_longPollingService = Executors.newSingleThr ...
- VS2019和net core 3.0(整理不全,但是孰能生巧)
更新 net core 3.0 只能配合vs2019 net core 3.0 新特性 详情 IntelliCode 智能插件 live share ctrl+. 快速重构 调试中的数据断点(很棒) ...