wordcount代码实现详解
1、MapReduce整体流程
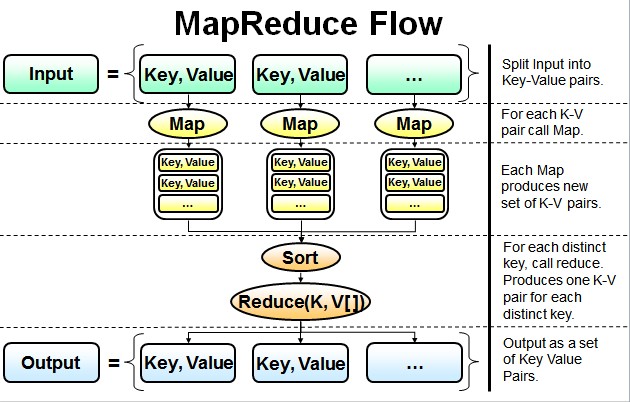
- 并行读取文本中的内容,然后进行MapReduce操作。
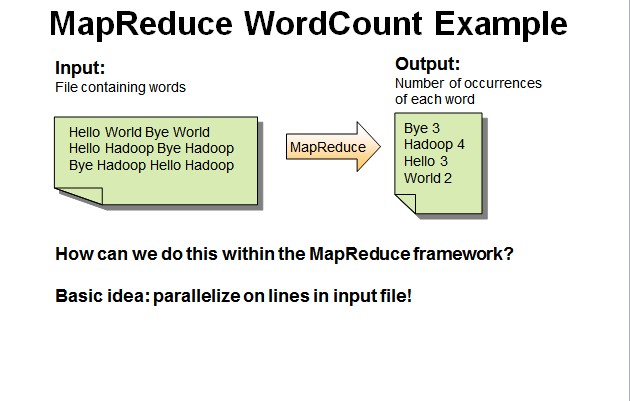
- Map过程:并行读取文本,对读取的单词进行map操作,每个词都以<key,value>形式生成。
我的理解:
一个有三行文本的文件进行MapReduce操作。
读取第一行Hello World Bye World ,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>
读取第二行Hello Hadoop Bye Hadoop ,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
读取第三行Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
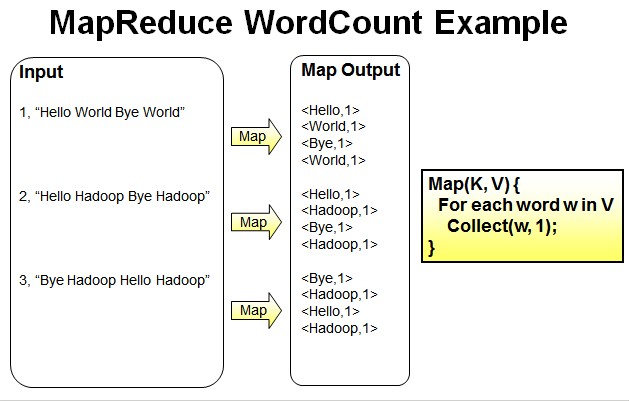
- Reduce操作是对map的结果进行排序,合并,最后得出词频。
我的理解:
经过进一步处理(combiner),将形成的Map根据相同的key组合成value数组。
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>
循环执行Reduce(K,V[]),分别统计每个单词出现的次数。
<Bye,3> <Hadoop,4> <Hello,3> <World,2>
2、WordCount源码

package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
*
* 描述:WordCount explains by York
* @author Hadoop Dev Group
*/
publicclass WordCount {
/**
* 建立Mapper类TokenizerMapper继承自泛型类Mapper
* Mapper类:实现了Map功能基类
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
* Reporter 则可用于报告整个应用的运行进度,本例中未使用。
*
*/
publicstaticclass TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/**
* IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为int,String 的替代品。
* 声明one常量和word用于存放单词的变量
*/
privatefinalstatic IntWritable one =new IntWritable(1);
private Text word =new Text();
/**
* Mapper中的map方法:
* void map(K1 key, V1 value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* Context:收集Mapper输出的<k,v>对。
* Context的write(k, v)方法:增加一个(k,v)对到context
* 程序员主要编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中
* write方法存入(单词,1)这样的二元组到context中
*/
publicvoid map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr =new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} publicstaticclass IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result =new IntWritable();
/**
* Reducer类中的reduce方法:
* void reduce(Text key, Iterable<IntWritable> values, Context context)
* 中k/v来自于map函数中的context,可能经过了进一步处理(combiner),同样通过context输出
*/
publicvoid reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum =0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} publicstaticvoid main(String[] args) throws Exception {
/**
* Configuration:map/reduce的j配置类,向hadoop框架描述map-reduce执行的工作
*/
Configuration conf =new Configuration();
String[] otherArgs =new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length !=2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job =new Job(conf, "word count"); //设置一个用户定义的job名称
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reducer类
job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class); //为job输出设置value类
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为job设置输出路径
System.exit(job.waitForCompletion(true) ?0 : 1); //运行job
}
}
3、WordCount逐行解析
- 对于map函数的方法。
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {…}
这里有三个参数,前面两个Object key, Text value就是输入的key和value,第三个参数Context context这是可以记录输入的key和value,例如:context.write(word, one);此外context还会记录map运算的状态。
- 对于reduce函数的方法。
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {…}
reduce函数的输入也是一个key/value的形式,不过它的value是一个迭代器的形式Iterable<IntWritable> values,也就是说reduce的输入是一个key对应一组的值的value,reduce也有context和map的context作用一致。
至于计算的逻辑则需要程序员编码实现。
- 对于main函数的调用。
首先是:
Configuration conf = new Configuration();
运行MapReduce程序前都要初始化Configuration,该类主要是读取MapReduce系统配置信息,这些信息包括hdfs还有MapReduce,也就是安装hadoop时候的配置文件例如:core-site.xml、hdfs-site.xml和mapred-site.xml等等文件里的信息,有些童鞋不理解为啥要这么做,这个是没有深入思考MapReduce计算框架造成,我们程序员开发MapReduce时候只是在填空,在map函数和reduce函数里编写实际进行的业务逻辑,其它的工作都是交给MapReduce框架自己操作的,但是至少我们要告诉它怎么操作啊,比如hdfs在哪里,MapReduce的jobstracker在哪里,而这些信息就在conf包下的配置文件里。
接下来的代码是:
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
If的语句好理解,就是运行WordCount程序时候一定是两个参数,如果不是就会报错退出。至于第一句里的GenericOptionsParser类,它是用来解释常用hadoop命令,并根据需要为Configuration对象设置相应的值,其实平时开发里我们不太常用它,而是让类实现Tool接口,然后再main函数里使用ToolRunner运行程序,而ToolRunner内部会调用GenericOptionsParser。
接下来的代码是:
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,而具体的map和reduce运算就是task了,这里我们构建一个job,构建时候有两个参数,一个是conf这个就不累述了,一个是这个job的名称。
第二行就是装载程序员编写好的计算程序,例如我们的程序类名就是WordCount了。这里我要做下纠正,虽然我们编写mapreduce程序只需要实现map函数和reduce函数,但是实际开发我们要实现三个类,第三个类是为了配置mapreduce如何运行map和reduce函数,准确的说就是构建一个mapreduce能执行的job了,例如WordCount类。
第三行和第五行就是装载map函数和reduce函数实现类了,这里多了个第四行,这个是装载Combiner类,这个类和mapreduce运行机制有关,其实本例去掉第四行也没有关系,但是使用了第四行理论上运行效率会更好。
接下来的代码:
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
这个是定义输出的key/value的类型,也就是最终存储在hdfs上结果文件的key/value的类型。
最后的代码是:
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
第一行就是构建输入的数据文件,第二行是构建输出的数据文件,最后一行如果job运行成功了,我们的程序就会正常退出。
wordcount代码实现详解的更多相关文章
- 【iOS 使用github上传代码】详解
[iOS 使用github上传代码]详解 一.github创建新工程 二.直接添加文件 三.通过https 和 SSH 操作两种方式上传工程 3.1https 和 SSH 的区别: 3.1.1.前者可 ...
- Scala 深入浅出实战经典 第64讲:Scala中隐式对象代码实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第63讲:Scala中隐式类代码实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- PHP扩展代码结构详解
PHP扩展代码结构详解: 这个是继:使用ext_skel和phpize构建php5扩展 内容 (拆分出来) Zend_API:深入_PHP_内核:http://cn2.php.net/manual/ ...
- Netty学习——服务器端代码和客户端代码 原理详解
服务器端代码和客户端代码 原理详解:(用到的API) 0.Socket 连接服务器端的套接字 1.TcompactProtocol 协议层2.TFrameTransport 传输层3.THsh ...
- HTML滚动字幕代码参数详解及Js间隔滚动代码
html文字滚动代码 <marquee style="WIDTH: 388px; HEIGHT: 200px" scrollamount="2" dire ...
- 算术编码Arithmetic Coding-高质量代码实现详解
关于算术编码的具体讲解我不多细说,本文按照下述三个部分构成. 两个例子分别说明怎么用算数编码进行编码以及解码(来源:ARITHMETIC CODING FOR DATA COIUPRESSION): ...
- 详解C#泛型(二) 获取C#中方法的执行时间及其代码注入 详解C#泛型(一) 详解C#委托和事件(二) 详解C#特性和反射(四) 记一次.net core调用SOAP接口遇到的问题 C# WebRequest.Create 锚点“#”字符问题 根据内容来产生一个二维码
详解C#泛型(二) 一.自定义泛型方法(Generic Method),将类型参数用作参数列表或返回值的类型: void MyFunc<T>() //声明具有一个类型参数的泛型方法 { ...
- sift代码实现详解
1.创建高斯金字塔第-1组 1.1.将源图片转成灰度图 void ConvertToGray(const Mat& src, Mat& dst) { cv::Size size = s ...
随机推荐
- 本地搭建SVN局域网服务器【转】
转自:http://blog.csdn.net/sunbaigui/article/details/8466310 参考链接:http://tortoisesvn.net/docs/nightly/T ...
- 【bzoj3289】mato的文件管理
首先允许离线,一眼莫队…… 然后考虑对于每次移动,这不就是让你求逆序对嘛(QAQ) 考虑怎么移动? 每次在最后添加一个数,比这个数大的数都会与其形成一个逆序对 每次在最后移除一个数,比这个数大的数都会 ...
- JavaScript的字符串详解
#转载请留言联系 字符串合并 + var str1="chi"; var str2="chung"; console.log(str1+str2) 输出:chi ...
- k8s资源应用的自由伸缩Scale(up/down)
伸缩(Scale Up/Down)是指在线增加或减少 Pod 的副本数. 1.增加副本 Deployment nginx-deployment初始是两个副本. [root@k8s-master k ...
- Scanner类的个人分析
Scanner类读取键盘输入(java中Scanner类nextLine()和next()的区别和使用方法&&java 中的Scanner(非常详细不看后悔)): 2017/3/18 ...
- Delphi:对TNotifyEvent的理解
type TNotifyEvent = procedure (Sender: TObject) of object; 在Delphi中事件也是一个类,类型就是事件类型,不同的事件属于不同的类.TNot ...
- yii2中判断值是否存在二维数组中
//在yii2中,在类里面的函数,可以不加action $arr = array( array('a', 'b'), array('c', 'd') ); in_array('a', $arr); / ...
- hdu5739
以前从来没写过求点双连通分量,现在写一下…… 这题还用到了一个叫做block forest data structure,第一次见过…… ——对于每一个点双联通分量S, 新建一个节点s, 向S中每个节 ...
- hdu6158(圆的反演)
hdu6158 题意 初始有两个圆,按照标号去放圆,问放完 \(n\) 个圆后的总面积. 分析 圆的反演的应用. 参考blog 设反演圆心为 \(O\) 和反演半径 \(R\) 圆的反演的定义: 已知 ...
- c++基础学习之函数与参数
1.传值参数 //传值参数 int Abc(int a,int b,int c) { ; } a,b和c是函数Abc 的形式参数formal parameter,类型均为整型.如果在如下语句中调用函数 ...