【Python3 爬虫】06_robots.txt查看网站爬取限制情况
大多数网站都会定义robots.txt文件来限制爬虫爬去信息,我们在爬去网站之前可以使用robots.txt来查看的相关限制信息
例如:
我们以【CSDN博客】的限制信息为例子
在浏览器输入:https://blog.csdn.net/robots.txt
获取到信息如下:
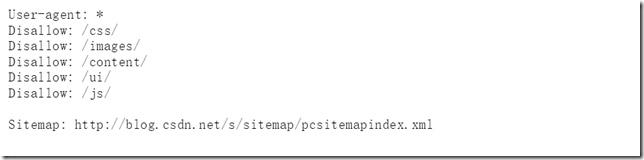
从上图我们可以看出:
①该网站无论用户使用哪种代理都允许爬取
②但是当爬取/css,/images…等链接的时候是禁止的
③我们可以看到还存在一个网址Sitemap,j具体解析如下:
网站提供的Sitemap文件(即网站地图)可以帮助网站定位最新的内容,则无须爬取每一个网页,虽然Sitemap文件提供了一种爬取网站的有效方式,但是我们仍然需要对其谨慎处理,因为该文件经常存在缺失,过期和不完整。
【Python3 爬虫】06_robots.txt查看网站爬取限制情况的更多相关文章
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- 5分钟掌握智联招聘网站爬取并保存到MongoDB数据库
前言 本次主题分两篇文章来介绍: 一.数据采集 二.数据分析 第一篇先来介绍数据采集,即用python爬取网站数据. 1 运行环境和python库 先说下运行环境: python3.5 windows ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
随机推荐
- hdu 1316(大整数)
How Many Fibs? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)To ...
- 微信小程序保存图片的方法
1.xhtml代码 长按保存: <view class="img" catchlongpress='baocun'></view> 2.Js代码 baocu ...
- crontab自动备份MySQL数据库并删除5天前备份
1.创建备份文件夹 //备份数据库文件夹 mkdir /data/backmysql //crontab日志 mkdir /data/logs 2.创建脚本文件 db_user="xxx ...
- logging 日志两种使用方法(转)
下面我们使用代码logging的代码来说明: 使用baseConfig()函数对 logging进行 简单的 配置: import logging; # 使用baseConfig()函数,可选参数有f ...
- [centos] 需要 libmpc.so.2 提供下载
http://pan.baidu.com/s/1kTmmthH yum update 的时候需要libmpc.so.2, 于是下载了一个 rpm -ivh filename.rpm 安装上就好了
- 【分块】bzoj1798 [Ahoi2009]Seq 维护序列seq
分块,打标记,维护两个标记:乘的 和 加的. 每次 区间乘的时候,对 乘标记 和 加标记 都 乘上那个值. 每次 区间加的时候 对 加标记 加上那个值. (ax+b)*v=axv+bv.开 long ...
- 语言基础之description方法
1.description方法的一般用处 1: // 指针变量的地址 2: NSLog(@"%p", &p); 3: // 对象的地址 4: NSLog(@"%p ...
- 大湿教我写程序(2)之走向AV之路
一.大摆庆功宴 上一篇博文<大湿教我写程序(1)之菜单导航篇>中讲到了我撸码到晚上两点多,整出了一个还算是高端大气上档次的demo.半夜回到家里打算着可以好好睡上一个懒觉,到时候直接到客户 ...
- 启用多处理器编译--加快VS2013编译
依次打开项目“属性“==>”配置属性“==>”C/C++(或其它语言)“==>”常规“,最后一项,多处理器编译选择是. 官方解释如下: /MP 选项在命令行上以减少总时间编译源文件. ...
- 12、Django简易框架
安装: tar -zxvf Django-1.5.1.tar.gz cd Django-1.5.1 [root@likun Django-1.5.1]# ls [root@likun Djang ...