Spark RDD简介与运行机制概述
RDD工作原理:
主要分为三部分:创建RDD对象,DAG调度器创建执行计划,Task调度器分配任务并调度Worker开始运行。
SparkContext(RDD相关操作)→通过(提交作业)→(遍历RDD拆分stage→生成作业)DAGScheduler→通过(提交任务集)→任务调度管理(TaskScheduler)→通过(按照资源获取任务)→任务调度管理(TaskSetManager)

举例:以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的。
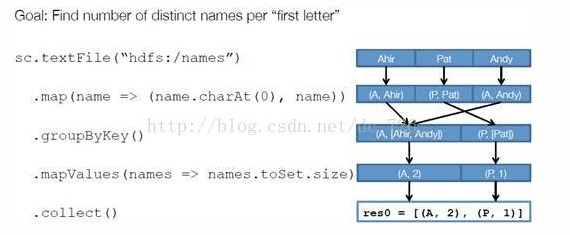
步骤 1 :创建 RDD 。 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 ) 。
步骤 2 :创建执行计划。 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划。
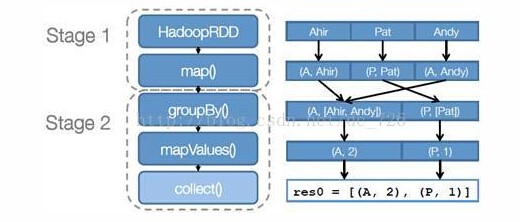
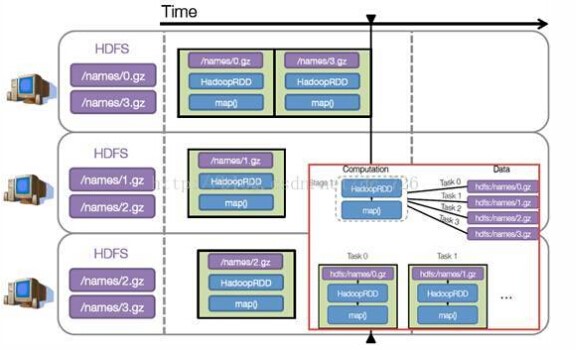
步骤 3 :调度任务。 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
假设本例中的 hdfs://names 下有四个文件块,那么 HadoopRDD 中 partitions 就会有四个分区对应这四个块数据,同时 preferedLocations 会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。
Task管理和序列化:
Task的运行要解决的问题不外乎就是如何以正确的顺序,有效地管理和分派任务,如何将Task及运行所需相关数据有效地发送到远端,以及收集运行结果
Task的派发源起于DAGScheduler调用TaskScheduler.submitTasks将一个Stage相关的一组Task一起提交调度。
在TaskSchedulerImpl中,这一组Task被交给一个新的TaskSetManager实例进行管理,所有的TaskSetManager经由SchedulableBuilder根据特定的调度策略进行排序,TaskSchedulerImpl的resourceOffers函数中,当前被选择的TaskSetManager的ResourceOffer函数被调用并返回包含了序列化任务数据的TaskDescription,最后这些TaskDescription再由SchedulerBackend派发到ExecutorBackend去执行
系列化的过程中,上一节中所述App依赖文件相关属性URL等通过DataOutPutStream写出,而Task本身通过可配置的Serializer来序列化,当前可配制的Serializer包括如JavaSerializer ,KryoSerializer等
Task的运行结果在Executor端被序列化并发送回SchedulerBackend,由于受到Akka Frame Size尺寸的限制,如果运行结果数据过大,结果会存储到BlockManager中,这时候发送到SchedulerBackend的是对应数据的BlockID,TaskScheduler最终会调用TaskResultGetter在线程池中以异步的方式读取结果,TaskSetManager再根据运行结果更新任务状态(比如失败重试等)并汇报给DAGScheduler等
Spark RDD简介与运行机制概述的更多相关文章
- SSL/TLS 协议运行机制概述(二)
SSL/TLS 协议运行机制概述(二) 在SSL/TLS 协议运行机制概述(一)中介绍了TLS 1.2 的运行机制,现在我们来看年 TLS 1.3 的运行机制.会涉及到SSL/TLS 协议运行机制概述 ...
- SSL/TLS 协议运行机制概述(一)
SSL/TLS 协议运行机制概述(一) SSL/TLS 发展史 1994年,NetScape 设计了SSL协议(Secure Sockets Layer) 1.0,未正式发布 1995年,NetSca ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- 通过WordCount解析Spark RDD内部源码机制
一.Spark WordCount动手实践 我们通过Spark WordCount动手实践,编写单词计数代码:在wordcount.scala的基础上,从数据流动的视角深入分析Spark RDD的数据 ...
- Spark standalone简介与运行wordcount(master、slave1和slave2)
前期博客 Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master.slave1和slave2) Spark运行模式概述 1. Stan ...
- 01_日志采集框架Flume简介及其运行机制
离线辅助系统概览: 1.概述: 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出. 任务调度等不可或缺的辅助系统,而这些辅助 ...
- MapReduce的核心运行机制
MapReduce的核心运行机制概述: 一个完整的 MapReduce 程序在分布式运行时有两类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.Yarnchild:负责 ...
- Spark 中 RDD的运行机制
1. RDD 的设计与运行原理 Spark 的核心是建立在统一的抽象 RDD 之上,基于 RDD 的转换和行动操作使得 Spark 的各个组件可以无缝进行集成,从而在同一个应用程序中完成大数据计算任务 ...
- Spark运行模式概述
Spark编程模型的回顾 spark编程模型几大要素 RDD的五大特征 Application program的组成 运行流程概述 具体流程(以standalone模式为例) 任务调度 DAGSche ...
随机推荐
- jquery 按回城 等于提交按钮
$(document).keydown(function(e){ if(e.keyCode==13){ $('.bu ...
- HDU-5781 ATM Mechine(概率DP)
题目大意:某个未知整数x等概率的分布在[0,k]中.每次你都可以从这个整数中减去一个任意整数y,如果x>=y,那么x=x-y,操作次数累计加1:否则,将会受到一次错误提示.当错误提示超过w次,将 ...
- POJ-2486 Apple Tree (树形DP)
题目大意:一棵点带权有根树,根节点为1.从根节点出发,走k步,求能收集的最大权值和. 题目分析:从一个点向其某棵子树出发有三种可能的情况: 1.停留在那棵子树上: 2.再回到这个点: 3.经过这个点走 ...
- 黑马程序员——JAVA基础之多态与Object
------- android培训.java培训.期待与您交流! ---------- 多态 : 多态定义: 某一类事物的多种存在形态. 多态的体现: 父类的引用指向了自己的子类对象. ...
- 如果将彩色图像和灰度图像一起放进 CNN 中去,会是什么结果?
如果将彩色图像和灰度图像一起放进 CNN 中去,会是什么结果? 今天,坑爹的实验,我处理 SUN397 的时候,忘记去掉灰度图了,结果,利用微调后的 model 提取 feature,悲剧的发现,无论 ...
- jfinal对象封装Record原理
/*DbPro.class*/ public transient Record findFirst(String sql, Object paras[]{ List result = find(sql ...
- CUDA Thread Indexing
1D grid of 1D blocks __device__ int getGlobalIdx_1D_1D() { return blockIdx.x *blockDim.x + threadIdx ...
- Oracle升级前备份和失败回退
一.升级前备份 1.软件备份[root@localhost backup]# su - oracle [oracle@localhost ~]$ cd $ORACLE_HOME[oracle@loca ...
- C# Regex.IsMatch (正则表达式验证:数字、小数点、邮件、计算表达式)
public bool isInt(string str) { //^([+-]?)表示加减号只能出现在字符串开头且只有一位 ///d*表示后面可以有多个或一个十进制数 //$表示字符串结尾 retu ...
- [Asp.net]说说密码框和只读框
作者:Wolfy出处:http://www.cnblogs.com/wolf-sun/ 引言 最近负责了一个公司的小项目,从前台到后代,都是自己搞的,为一个客户弄一个信息管理的小系统,虽然对界面什么的 ...