python抓取中文网页乱码通用解决方法
注:转载自http://www.cnpythoner.com/
我们经常通过python做采集网页数据的时候,会碰到一些乱码问题,今天给大家分享一个解决网页乱码,尤其是中文网页的通用方法。
首页我们需要安装chardet模块,这个可以通过easy_install 或者pip来安装。
安装完以后我们在控制台上导入模块,如果正常就可以。
比如我们遇到的一些ISO-8859-2也是可以通过下面的方法解决的。
直接上代码吧:
import sys
import chardet
req = urllib2.Request("http://www.163.com/")##这里可以换成http://www.baidu.com,http://www.sohu.com
content = urllib2.urlopen(req).read()
typeEncode = sys.getfilesystemencoding()##系统默认编码
infoencode = chardet.detect(content).get('encoding','utf-8')##通过第3方模块来自动提取网页的编码
html = content.decode(infoencode,'ignore').encode(typeEncode)##先转换成unicode编码,然后转换系统编码输出
print html
通过上面的代码,相信能够解决你采集乱码的问题。
接着开始学习网络爬虫的深入点儿的东东:
以抓取韩寒博客文章目录来加以说明:http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html,下面是截图
我用的是Chrome浏览器(firefox也行),打开上述网页,鼠标右击,选择审查元素,就会出现下面所示
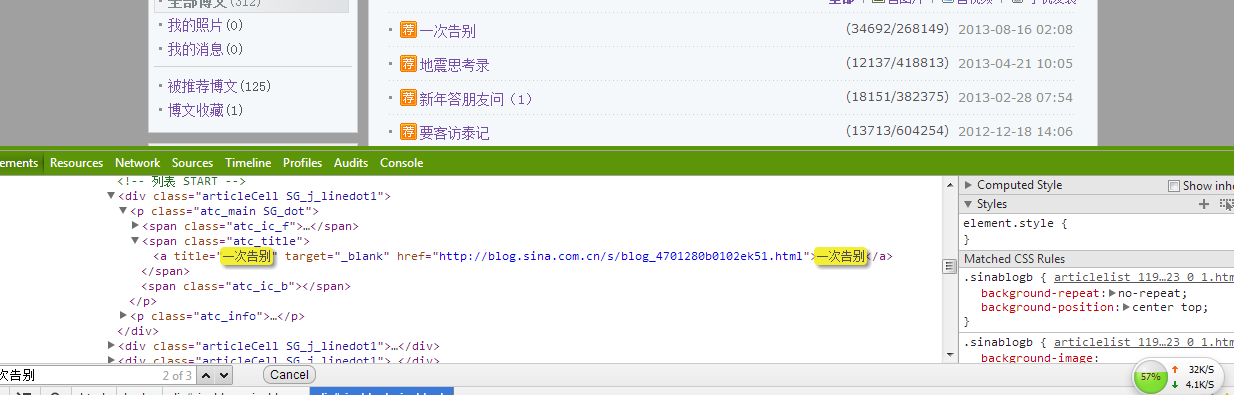
首先我们来实现抓取第一篇文章“一次告别”的page的url
按住ctrl+f就会在上图左下角打开搜索栏,输入”一次告别“,就会自动定位到html源码所在位置,如上高亮显示的地方
接下来我们就是要把对应的url:http://blog.sina.com.cn/s/blog_4701280b0102ek51.html提取出来
详细实现代码如下:
#coding:utf-8
import urllib
str0 = '<a title="一次告别" target="_blank" href="http://blog.sina.com.cn/s/blog_4701280b0102ek51.html">一次告别</a>'
title = str0.find(r'<a title')
print title
href = str0.find(r'href=')
print href
html = str0.find(r'.html')
print html
url = str0[href + 6:html + 5]
print url
content = urllib.urlopen(url).read()
#print content
filename = url[-26:]
print filename
open(filename, 'w').write(content)
catchBlog.py
下面对代码进行解释:
首先利用find函数开始依次匹配查找'<a title','href=','.html',这样就可以找到关键字符所在的索引位置,然后就可以定位到http://blog.sina.com.cn/s/blog_4701280b0102ek51.html的位置[href+6:html+5]
最后利用urllib的相关函数打开并读取网页内容,写到content中
运行程序:
0
40
93
http://blog.sina.com.cn/s/blog_4701280b0102ek51.html
blog_4701280b0102ek51.html
于是在代码所在目录生成html文件blog_4701280b0102ek51.html
至此便抓取到第一篇文章的url及网页内容;上述操作主要学习了以下几个内容:1.分析博客文章列表特征2.提取字符串中的网络连接地址3.下载博文到本地
接下来继续深入:获取博文目录第一页所有文章的链接并将所有文章下载下来
#coding:utf-8
import urllib
import time
url = ['']*50
con = urllib.urlopen('http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html').read()
i = 0
title = con.find(r'<a title=')
href = con.find(r'href=', title)
html = con.find(r'.html', href) while title != -1 and href != -1 and html != -1 and i < 50:
url[i] = con[href+6:html+5]
print url[i]
title = con.find(r'<a title=', html)
href = con.find(r'href=', title)
html = con.find(r'.html', href)
i = i + 1
else:
print "Find end!"
j = 0
while j < 50:
content = urllib.urlopen(url[j]).read()
open(r'hanhan/' + url[j][-26:], 'w+').write(content)
j = j + 1
print 'downloading', url[j]
time.sleep(15)
else:
print 'Download article finish!'
#print 'con', con
catchBlog1.py
python抓取中文网页乱码通用解决方法的更多相关文章
- 解决Scrapy抓取中文网页保存为json文件时中文不显示而是显示unicode的问题
注意:此方法跟之前保存成json文件的写法有少许不同之处,注意区分 情境再现: 使用scrapy抓取中文网页,得到的数据类型是unicode,在控制台输出的话也是显示unicode,如下所示 {'au ...
- ECSHOP编辑器Fckeditor上传图片中文名称乱码的解决方法
ECSHOP编辑器Fckeditor上传图片中文名称乱码的解决方法 ECSHOP教程/ ecshop教程网(www.ecshop119.com) 2015-02-11 中文名乱码是因为:FCKed ...
- 用c#读取文件内容中文是乱码的解决方法:
用c#读取文件内容中文是乱码的解决方法: //方法1: StreamReader din = new StreamReader(@"C:\1.txt", System.Text.E ...
- URL传参时中文参数乱码的解决方法
URL传参时,中文参数乱码的解决: 今天在工作中遇到了这样的一个问题,在页面之间跳转时,我将中文的参数放入到url中,使用location进行跳转传参,但是发现接收到的参数值是乱码.我的代码是这样写的 ...
- python(27)requests 爬取网页乱码,解决方法
最近遇到爬取网页乱码的情况,找了好久找到了种解决的办法: html = requests.get(url,headers = head) html.apparent_encoding html.enc ...
- SecureCRT中文显示乱码的解决方法
注:本文出自:http://riching.iteye.com/blog/349754 最近开始用SecureCRT登陆linux系统,由于是新手,很多问题不清楚,碰到显示中文乱码的问题,困扰了好几天 ...
- Fiddler - 工具配置及在ios抓取不了https的解决方法
一.首先,官网下载最新版fiddler工具: https://www.telerik.com/fiddler 二.打开fiddler,点击Tools - Options 我电脑上的各项配置如下图(也可 ...
- PLSQL Developer 中文显示乱码的解决方法
PLSQL Developer 中文显示乱码是因为 Oracle 数据库所用的编码和 PLSQL Developer 所用的编码不同所导致的. 解决方法: 1. 先查询 Oracle 所用的编码 se ...
- win使用telnet到ubuntu下vim显示中文为乱码的解决方法~
1.几个路径: ubuntu: /etc/default/locale 相当于 centos:/etc/sysconfig/i18n vimrc的路径:① ~/.vimrc ② /etc/vi ...
随机推荐
- java万物皆对象
我们以Dom对象的形式 可以CRUD xml文件或xml字串(经流把xml文件读出转成字串) 我们以JsonObject对象的形式 可以CRUD json字串 还有正则表达式.ORM都是.
- Java基础之泛型——使用通配符类型参数(TryWildCard)
控制台程序 使用通配符类型参数可以设定方法的参数类型,其中的代码对于泛型类的实际类型参数不能有任何依赖.如果将方法的参数类型设定为Binary<?>,那么方法可以接受BinaryTree& ...
- JAVA的JVM虚拟机工作原理.V.1.0.0
注意:一下内容纯属个人理解,如有错误,欢迎批评指正. (90度弯腰)谢谢. java在JVM上的运行过程: 1,编辑好的java代码(IDE无报错,测试运行无错误): 2,java源代码通过javac ...
- extjs 常见的小问题
今天,小白就来总结下extjs的使用的时候的各种小问题或者说是小技巧.希望能够给各位刚接触extjs的朋友一点帮助. 1.当存在store的各种组件的store的autoload属性为false的时候 ...
- 查看真机的系统版本sdk
1.adb devices 确保连接上了真机 2.adb shell 进入android系统 3.进入system目录下 4.查看build.prop文件 cat build.prop
- malloc心得
使用malloc时,要有一种在内存中随机分配一块内存的思想,然后再把分配好的内存的首地址返回来.
- TP隐藏入口
我们知道,在thinkphp的案例中有一个.htaccess文件,里面配置了URL的一些重写规则,如: <IfModule mod_rewrite.c> RewriteEngine on ...
- java dyn proxy
package dyn; public interface RealService { void buy(); } =================== package dyn; public cl ...
- json和字符串/数组/集合的互相转换の神操作总结
一:前端字符串转JSON的4种方式 1,eval方式解析,恐怕这是最早的解析方式了. function strToJson(str){ var json = eval('(' + str + ')') ...
- 【pyQuery】抓取startup news首页
#! /usr/bin/python # coding: utf-8 from pyquery import PyQuery c=PyQuery('http://news.dbanotes.net/' ...