RabbitMQ消息可靠性、死信交换机、消息堆积问题
消息可靠性
确保消息至少被消费了一次(不丢失)
消息丢失的几种情况:
- 消息在网络传输时丢失,如生产者到交换机,交换机到队列的过程中
- MQ宕机:消息到达Queue了,但在消费者消费之前,MQ就宕机了
- 消费者宕机:消费者接收了消息但是还没处理就宕机了
如何解决? RabbitMQ分别针对生产者, MQ和消费者这三个角色提供了一些解决方法
生产者消息确认
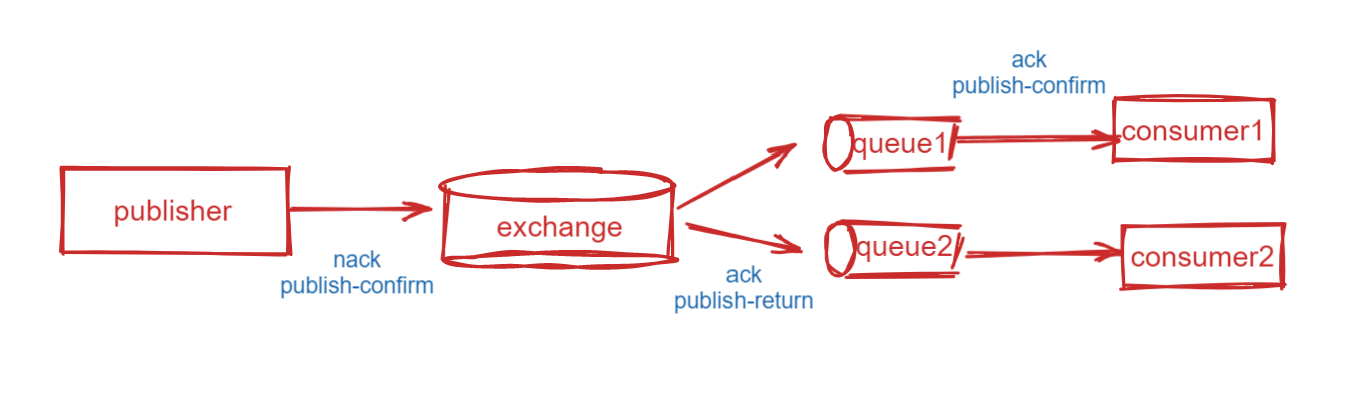
根据下图,消息的传输丢失可能有3种情况:
- 消息可能在从生产者到exchange的时候丢失,即没到达exchange。
- 消息从exchange通过routingKey将消息路由到queue 时丢失,即没到达queue
- 消息成功到达queue后,没有被消费者消费或者消费者获取消息还没经过处理就宕机了
Publisher Confirms
Since AMQP gives few guarantees regarding message persistence/handling, the traditional way to do this is with transactions, which can be unacceptably slow. To remedy this problem, we introduce an extension to AMQP in the form of Lightweight Publisher Confirms. (渣翻:传统的方式是采用事务控制,但这种方法十分地慢,RabbitMQ提供了一种更加轻量级的方式:生产者确认。
- RabbitMq发送到消费者的消息确认
- RabbitMQ到生产者的消息确认 (这种机制是Rabbitmq对Amqp协议的扩展)
以上两种特性都收到了TCP协议的启发
它们对于从发布者到 RabbitMQ 节点以及从 RabbitMQ 节点到消费者的可靠交付都是必不可少的。换句话说,它们对于数据安全至关重要,应用程序与 RabbitMQ 节点一样负责。
示例
Spring-amqp支持 publish confirm and returns 的 RabbitTemplate实现。 我们将使用springboot+rabbitmq来模拟上面三种情况。
RabbitTemplate 是spring-amqp定义的一个模板,它实现了AmqpTemplate接口(此接口定义了涵盖发送和接收消息的一般行为。)
- 新建工程,包含两个模块:consumer和publisher
配置文件:
# publisher的配置文件: (consumer的配置文件差不多)
logging:
pattern:
dateformat: HH:mm:ss:SSS
level:
cn.itcast: debug
spring:
rabbitmq:
host: 192.168.57.100 # rabbitMQ的ip地址
port: 5672 # 端口
username: xxx # 用户名称
password: 1234
virtual-host: /
publisher-confirm-type: correlated # 指定生产者确认的模式,correlated表示异步
publisher-returns: true # 开启生产者返回
template: # rabbitTemplage的设置,也可以通过代码配置
mandatory: true # 如果设置为true,发送失败的消息会被ReturnCallBack方法回调
Publish配置类,通过RabbitTemplate配置ReturnCallback函数用来处理消息没到队列的情况。
根据spring-amqp文档,一个RabbitTemplate只能支持一个ReturnCallback 函数。
@Slf4j
@Configuration
public class CommonConfig implements ApplicationContextAware{
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
// 获取rabbitTemplate对象
RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) ->
log.error("消息发送队列失败:{},响应码:{},失败原因:{},交换机:{},routingKey:{}",
message, replyCode, replyText, exchange, routingKey));
//重发消息...
}
}
这样我们就完成了一种失败处理:消息无法路由到队列。
测试类:
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringAmqpTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSendMessage2SimpleQueue() throws InterruptedException {
String routingKey = "simple.test";
String message = "hello spring-amqp!";
//准备CorrelationData,它包含了一个全局的ID用来标识消息,并且设置了两个函数用于处理其余两种错误
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
correlationData.getFuture().addCallback(confirm -> {
if(confirm.isAck()){
log.debug("消息成功投递到交换机!消息ID:{}",correlationData.getId());
}else{
log.error("消息投递到交换机失败,消息ID:{}",correlationData.getId());
}
}, throwable -> {
//失败,记录日志
log.error("消息发送失败 ",throwable) ;
});
rabbitTemplate.convertAndSend("amq.topic",routingKey,message,correlationData);
}
在测试中:
- 如果我们将routingKey改成MQ中不存在值,则会触发 ReturnCallback回调函数, 因为消息到达交换机后无法路由到任何一个队列
- 同样的,如果我们将交换机
amq.topic设置成MQ中不存在的值,则会得到 nack publish confirm, 因为消息无法投递到交换机。
消费者消息确认
消息几经波折终于到达了消费者这里,结果消费者还没来得及处理就宕机了,或在处理过程中发生了异常,导致消息没有被正确处理。而RabbitMQ认为消费者已经消费了,直接把消息丢掉。那前面的工作都白忙了。
于是,RabbitMQ提供了消费者确认机制。消费者处理消息后向MQ发送ack回执,MQ收到ack才会丢弃消息
Spring-amqp则允许配置三种确认模式:
- manual:手动ack,业务处理完成后,由程序员调用api发送ack
- auto:自动ack,由spring监测listen代码是否出现异常,没有异常则返回ack,抛出异常则返回nack
- none: 关闭ack,MQ假定消费者拿到消息后会成功处理,因此消息投递后会马上删除
示例
consumer配置文件yaml中指定spring-amqp的确认模式,这里以auto来演示,并开启失败重传。
logging:
pattern:
dateformat: HH:mm:ss:SSS
level:
cn.itcast: debug
spring:
rabbitmq:
host: 192.168.57.100 # rabbitMQ的ip地址
port: 5672 # 端口
username: wingdd
password: 1234
virtual-host: /
listener:
simple:
prefetch: 1
acknowledge-mode: auto # 开启自动确认模式
消费者发生异常后,消息会重新入队requeue到队列,再发送给消费者,这会导致mq压力过大。因此,我们需要利用spring的retry机制,消费者异常时进行本地重试,而不是无限制的入队。
增加重传的配置:
retry:
enabled: true # 开启重传
initial-interval: 1000ms # 初始失败等待时长
multiplier: 3 # 下一次等待时长的倍数,下一次等待时长=multiplier * last-interval
max-attempts: 3 # 最大重传次数
stateless: true # 无状态,默认为true。 如果业务中有事务,则要改成false
max-interval: 10000ms # 最大等待时长,约束multiplier和interval
@Slf4j
@Component
public class SpringRabbitListener {
@RabbitListener(queues="simple.queue")
public void ListenSimpleQueue(String msg) {
System.out.println("消费者接收到来自simple.queue的消息:【 " + msg + " 】");
int a= 1/0 ; //将抛出异常
log.info("消费者处理成功") ;
}
}
死信交换机
死信交换机就是指接收死信的交换机。
什么样的消息会称为死信?
- 被消费者使用basic.reject或者basic.nack返回,并且
requeue参数是false的消息。 - TTL过期未被消费的消息
- 队列满了导致被丢弃了的消息
TTL,Time-To-Live,如果一个队列的消息TTL结束仍未消费,则会变成死信,ttl超时分为两种情况:1. 消息所在的队列设置了存活时间 2.消息本身设置了存活时间。( 如果两者都有设置,选短的那个)
使用死信交换机和TTL,可以实现消费者延迟接收消息的效果,这种消息模式乘坐延迟队列(Delay Queue)模式
延迟队列的使用场景包括:
- 延迟发送短信
- 用户下单后15分钟未支付则自动取消
- 预约工作会议,20分钟后自动通知参会人员。
例子
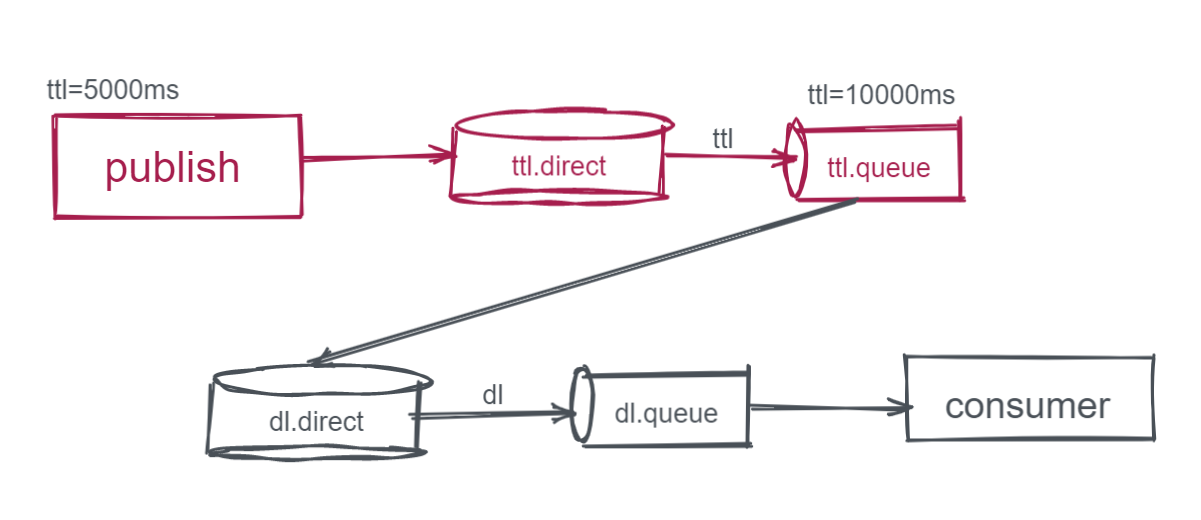
如图,我们将实现这样的场景,publish将消息发送到ttl交换机再到ttl Queue后,消息超时将被投递到死信交换机和队列,此时consumer再消费消息,这就达到了延迟消息的效果
①、在consumer中添加 监听dl.queue
@RabbitListener(bindings= @QueueBinding(
value=@Queue(name="dl.queue",durable = "true"),
exchange=@Exchange(name="dl.direct"),
key="dl"
))
public void listenDlQueue(String msg){
log.info("消费者接收到了dl.queue的消息 【"+msg+"】");
}
②、comsuer增加配置类用于创建ttl.queue和ttl交换机,并绑定。
package cn.itcast.mq.config;
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class TTLConfiguration {
@Bean
public DirectExchange ttlExchange(){
return new DirectExchange("ttl.direct") ;
}
@Bean
public Queue ttlQueue(){
return QueueBuilder.durable("ttl.queue").
ttl(6000).
deadLetterExchange("dl.direct").
deadLetterRoutingKey("dl").
build();
}
// 将ttl交换机和ttlQueue绑定起来
@Bean
public Binding dlbinding(){
return BindingBuilder.bind(ttlQueue()).to(ttlExchange()).with("ttl");
}
}
③、在publisher模块中向ttl.queue发送消息
@Test
public void TTLTest() {
Message message = MessageBuilder.withBody("hello TTL Queue Or Dead Queue!".getBytes(StandardCharsets.UTF_8))
.build();
rabbitTemplate.convertAndSend("ttl.direct", "ttl",message) ;
log.info("消息发送成功了!");
}
结果:消费者最终接收到了dl.queue的消息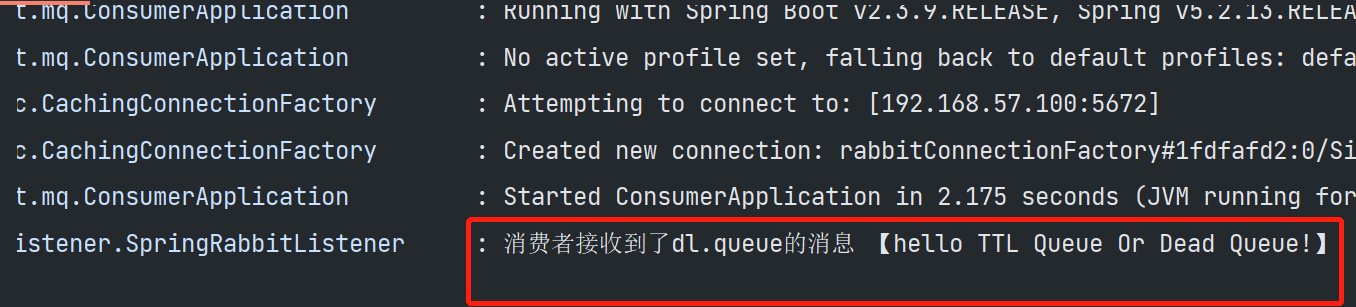
高可用问题
从单点MQ到集群MQ
消息堆积问题
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限,此时
最早接收到的消息就会变成死信,被丢弃。 这就是消息堆积问题
解决消息堆积的思路:
- 增加更多的消费者,提高消费速度
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限
惰性队列
RabbitMQ从3.6.0版本开始就增加了Lazy Queues的概念,惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
参考
代码:根据Bilibili黑马教程编写
https://www.cnblogs.com/binghe001/p/14443360.html
https://docs.spring.io/spring-amqp/docs/1.6.3.RELEASE/reference/html/_reference.html
RabbitMQ消息可靠性、死信交换机、消息堆积问题的更多相关文章
- SpringBoot整合RabbitMQ实战附加死信交换机
前言 使用springboot,实现以下功能,有两个队列1.2,往里面发送消息,如果处理失败发生异常,可以重试3次,重试3次均失败,那么就将消息发送到死信队列进行统一处理,例如记录数据库.报警等 环境 ...
- Rabbitmq消费失败死信队列
Rabbitmq 重消费处理 一 处理流程图: 业务交换机:正常接收发送者,发送过来的消息,交换机类型topic AE交换机: 当业务交换机无法根据指定的routingkey去路由到队列的时候,会全部 ...
- 2.RabbitMQ 的可靠性消息的发送
本篇包含 1. RabbitMQ 的可靠性消息的发送 2. RabbitMQ 集群的原理与高可用架构的搭建 3. RabbitMQ 的实践经验 上篇包含 1.MQ 的本质,MQ 的作用 2.R ...
- rabbitmq如何保证消息可靠性不丢失
目录 生产者丢失消息 代码模拟 事务 confirm模式确实 数据退回监听 MQ事务相关软文推荐 MQ丢失信息 消费者丢失信息 之前我们简单介绍了rabbitmq的功能.他的作用就是方便我们的消息解耦 ...
- RabbitMQ消息可靠性传输
消息的可靠性投递是使用消息中间件不可避免的问题,不管是使用kafka.rocketMQ或者rabbitMQ,那么在RabbitMQ中如何保证消息的可靠性投递呢? 先再看一下RabbitMQ消息传递的流 ...
- RabbitMQ的消息可靠性(五)
一.可靠性问题分析 消息的可靠性投递是使用消息中间件不可避免的问题,不管是使用哪种MQ都存在这种问题,接下来要说的就是在RabbitMQ中如何解决可靠性问题:在前面 在前面说过消息的传递过程中有三个对 ...
- [转载]RabbitMQ消息可靠性分析
有很多人问过我这么一类问题:RabbitMQ如何确保消息可靠?很多时候,笔者的回答都是:说来话长的事情何来长话短说.的确,要确保消息可靠不只是单单几句就能够叙述明白的,包括Kafka也是如此.可靠并不 ...
- RabbitMQ消息可靠性分析
消息中间件的可靠性是指对消息不丢失的保障程度:而消息中间件的可用性是指无故障运行的时间百分比,通常用几个 9 来衡量.不存在绝对的可靠性只能尽量趋向完美.并且通常可靠性也意味着影响性能和付出更大的成本 ...
- RabbitMQ消息可靠性分析 - 简书
原文:RabbitMQ消息可靠性分析 - 简书 有很多人问过我这么一类问题:RabbitMQ如何确保消息可靠?很多时候,笔者的回答都是:说来话长的事情何来长话短说.的确,要确保消息可靠不只是单单几句就 ...
随机推荐
- js和原生应用常用的数据交互方式
场景1 在原生app中经常会使用到H5页面,比如说电商中的活动页,一些电商中的详情页,等等...这些页面都有一个特点,那就是在未来修改的可能性,和一次性的几率特别的大.所以用H5的页面是最睿智的一种选 ...
- java静态方法和实例方法的区别
静态方法(方法前冠以static)和实例方法(前面未冠以static)的区别 调用静态方法或说类方法时,可以使用类名做前缀,也可以使用某一个具体的对象名:通常使用类名.static方法只能处理sta ...
- FastAPI(七十)实战开发《在线课程学习系统》接口开发--留言功能开发
在之前的文章:FastAPI(六十九)实战开发<在线课程学习系统>接口开发--修改密码,这次分享留言功能开发 我们能梳理下对应的逻辑 1.校验用户是否登录 2.校验留言的用户是否存在 3. ...
- Qt QPropertyAnimation+QTimer实现自制悬浮窗
目录 Qt下的悬浮窗 QPropertyAnimation QTimer 事件过滤 图标变换 自适应窗口大小 使用方法 Qt下的悬浮窗 最近项目需要一个类似于360悬浮球类似的悬浮窗,当鼠标放入停留一 ...
- LC-283
题目链接:https://leetcode-cn.com/problems/move-zeroes/ 首先想到了快排(简易思想),0为中间点, 把不等于0(注意题目没说不能有负数)的放到中间点的左边, ...
- Metaspaloit漏洞利用
Metaspaloit介绍Metaspaloit介绍 Metasploit是一款开源的安全漏洞检测工具,可以帮助安全和IT专业人士识别安全性问题,验证漏洞的缓解措施,并管理专家驱动的安全性进行评估,提 ...
- Java语言学习day17--7月23日
1.面向对象思想2.类与对象的关系3.局部变量和成员变量的关系4.封装思想5.private,this关键字6.随机点名器 ###01面向对象和面向过程的思想 * A: 面向过程与面向对象都是我们编程 ...
- 关于Swagger优化
背景 尽管.net6已经发布很久了,但是公司的项目由于种种原因依旧基于.net Framework.伴随着版本迭代,后端的api接口不断增多,每次在联调的时候,前端开发叫苦不迭:"小胖,你们 ...
- Vite2+Vue3+ts的eslint设置踩坑
目录 新项目了 Vite搭建 eslint 先安装eslint 创建.eslintrc.js 引入规则 Airbnb 配合prettier 对ts的支持 .eslintrc.js 在页面上查看esli ...
- Halo 开源项目学习(三):注册与登录
基本介绍 首次启动 Halo 项目时需要安装博客并注册用户信息,当博客安装完成后用户就可以根据注册的信息登录到管理员界面,下面我们分析一下整个过程中代码是如何执行的. 博客安装 项目启动成功后,我们可 ...