深入解读SQL的聚集函数
摘要:本文从基本聚集操作入手,介绍常用的SQL语法,以及一些扩展的聚集功能,同时会讲到在GaussDB(DWS)里聚集相关的一些优化思路。
本文分享自华为云社区《GaussDB(DWS) SQL进阶之SQL操作之聚集函数》,作者:两杯咖啡。
聚集操作是SQL语言中除扫描、投影、连接外的另一个常用基本操作,主要用于对海量数据进行分组,然后在组内进行统计计算的场景。在AP场景下,经常面临海量数据处理的场景,而最终用户希望通过海量数据获取汇总信息,聚集操作的使用将更加广泛。本文从基本聚集操作入手,介绍常用的SQL语法,以及一些扩展的聚集功能,同时会讲到在GaussDB(DWS)里聚集相关的一些优化思路。
一.典型语法
SQL的聚集操作的典型语法是:
SELECT <column1>, <column2>, Agg_func() FROM t GROUP BY 1, 2 HAVING <filter>;
其中基本元素及概念如下:
- 聚集操作子句
在SQL中,聚集操作子句通过GROUP BY实现,后面紧接聚集分组列,可以是列名,或者本层输出列的顺序号,从1开始。
- 聚集分组列
聚集分组列表明本聚集操作是以哪些列的值进行分组的,聚集分组列值均相等的元组会被划分到同一组。聚集分组列可以是一个,也可以是多个。
- 聚集函数
聚集函数即进行分组后,每组进行统计计算的函数,分为简单的和复杂的聚集函数。其中常用简单聚集函数包括以下五种:
- COUNT():用于进行分组内的计数。对于COUNT (column),计数不包含column为NULL值的元组;对于COUNT (*),计数包含所有元组。
- SUM():用于计算分组内列或表达式的和,计算不包含列为NULL值的元组。
- AVG():用于计算分组内列或表达式的平均值,AVG(col)等价于SUM(col)/ COUNT(col)(分组内存在元组)。
- MIN():用于计算分组内列或表达式的最小值。
- MAX():用于计算分组内列或表达式的最大值。
注:
- 如果缺少GROUP BY且包含聚集函数,则所有元组视为一个分组。
- 聚集函数不能嵌套。
- 聚集分组过滤条件
该条件为进行完聚集操作后,以分组为单位进行过滤的条件。聚集分组过滤条件是HAVING条件,在聚集后进行过滤,而我们通常使用的WHERE条件,需要在分组前进行过滤。
语法要求:
由于聚集操作是对聚集列进行去重分组,并进行聚集函数的分组计算,因为聚集操作的输出列和过滤条件中只能包含聚集列、聚集函数和常量,以及由它们组成的表达式。当出现非聚集列时,查询会报错。
特殊地,GaussDB(DWS)支持在主键列或唯一约束列上进行聚集的操作(尽管该操作为冗余操作),此时可以在输出列和过滤条件中包含任何列。
以TPC-H测试集的lineitem表举例说明,该表记录订单里的每种类型的零件,所属的订单号,零件所属的供应商,在订单中的序号以及价格、发货等信息。
表定义如下:
CREATE TABLE LINEITEM
( L_ORDERKEY BIGINT NOT NULL
, L_PARTKEY BIGINT NOT NULL
, L_SUPPKEY BIGINT NOT NULL
, L_LINENUMBER BIGINT NOT NULL
, L_QUANTITY DECIMAL(15,2) NOT NULL
, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL
, L_DISCOUNT DECIMAL(15,2) NOT NULL
, L_TAX DECIMAL(15,2) NOT NULL
, L_RETURNFLAG CHAR(1) NOT NULL
, L_LINESTATUS CHAR(1) NOT NULL
, L_SHIPDATE DATE NOT NULL
, L_COMMITDATE DATE NOT NULL
, L_RECEIPTDATE DATE NOT NULL
, L_SHIPINSTRUCT CHAR(25) NOT NULL
, L_SHIPMODE CHAR(10) NOT NULL
, L_COMMENT VARCHAR(44) NOT NULL
)
with (orientation = column)
distribute by hash(L_ORDERKEY);
SELECT MAX(l_receiptdate) FROM lineitem; -- 正确,获得所有零件的最后收货时间 SELECT SUM(l_quantity) FROM lineitem where l_orderkey=100000; -- 正确,获得订单号为100000的零件总数 SELECT l_orderkey, MAX(l_shipdate), MIN(l_shipdate) FROM lineitem GROUP BY l_orderkey; -- 正确,求每个订单的最早发货日期和最晚发货日期 SELECT l_orderkey, MAX(l_shipdate), MIN(l_shipdate) FROM lineitem GROUP BY 1; -- 正确,等价于上一条语句 SELECT l_orderkey, MAX(l_shipdate), MIN(l_shipdate) FROM lineitem GROUP BY 1 HAVING MIN(l_shipdate) < ‘1999-01-01’; -- 正确,求零件最早发货日期在1999-01-01之前的,每个订单的最早和最晚的发货日期(每个零件可能单独发货) SELECT l_orderkey || ‘_’ || SUM(l_quantity), SUM(L_EXTENDEDPRICE) FROM lineitem GROUP BY l_orderkey; -- 正确,求每个订单的组合标识(订单号+零件个数),以及总价格 SELECT l_orderkey, l_partkey, AVG(l_discount) FROM lineitem GROUP BY 1; -- 错误,l_partkey不是聚集列,但出现在输出列中
二.GaussDB(DWS)聚集执行及调优
在GaussDB(DWS)中,由于是分布式系统,数据计算应该尽量在各个DN上并行计算以得到最优的性能。因此,支持以下聚集操作计算方式:
- 如果分布键是GROUP BY列的子集,此时在各个DN上分别计算,结果汇总即可。
例如:lineitem表以l_orderkey作为分布键,则聚集列包含l_orderkey的均可以在各DN执行后汇总。
- 对于不满足(1)的场景,各DN分别执行后,DN间仍然可能存在聚集列相等的数据,需要二次聚集,此时GaussDB(DWS)支持三种计算方式。
示例语句(TPC-H Q1,输出列部分省略):
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval '90' day (3)
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
<1> 各DN上进行一次聚集,将结果汇总到CN上进行二次聚集。
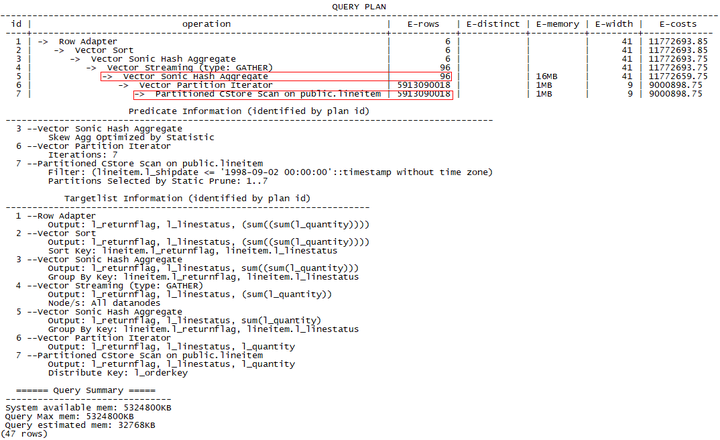
lineitem总共行数为59亿行。该方法中,经过DN一次聚集后,各DN输出4行数据(全局96行),这些数据汇总到CN上,由CN进行96行数据的二次聚集,最终输出6行数据。(数据信息均为估算值)
<2> 选择聚集列的子集列进行重分布,回退到(1)的情况后,各DN分别聚集后进行结果汇总。
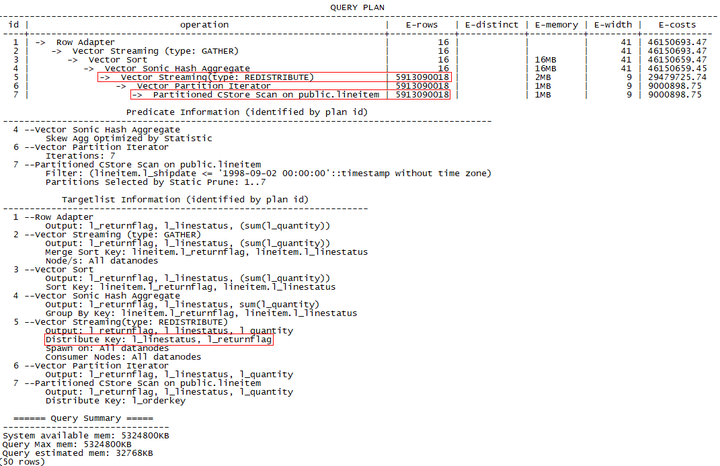
该方法中,首先按聚集的两列进行重分布,重分布数据量为59亿,然后各DN完成聚集,并将结果返回CN。
<3> 各DN上进行一次聚集,然后选择聚集列的子集列进行重分布,各DN上进行二次聚集后结果汇总。
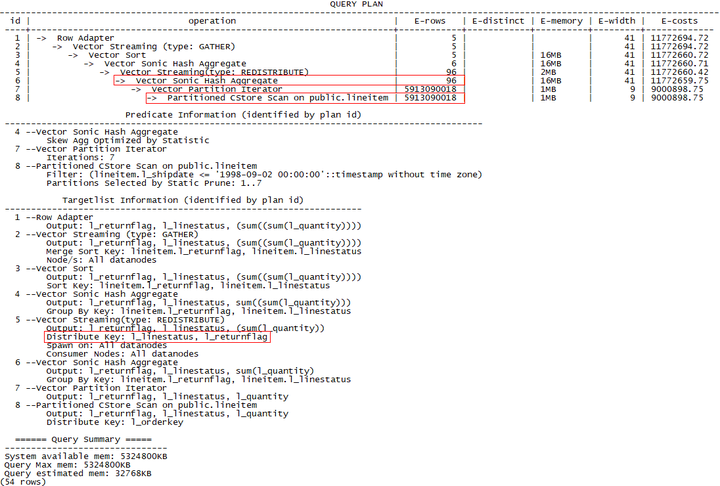
该方法中,各DN进行一次聚集,行数由59亿减少到4行,然后按聚集的两列进行重分布,各DN进行二次聚集。
可以看出,该查询适合用<1>和<3>的方式进行执行,因为聚集后的行数比较少,在CN上执行或重分布的数据量都不大,所以开销较小。而<2>的方式要对59亿行数据进行网络重分布,网络占用较大。可以总结出三种方法的适用场景:
<1> 该方法适合于一次聚集后行数较少且DN数较少的场景,这样汇聚到CN的行数较少,不会导致CN成为计算的瓶颈。
<2> 相较于<3>方法,该方法适合于DN一次聚集后行数缩减不明显的场景,这时可以以所有数据重分布的代价,省略DN的一次聚集操作。
<3> 与<2>相反,该方法适合于DN一次聚集后行数缩减明显的场景,例如上面的示例。
在GaussDB(DWS)中,以上三种方法的选择是根据代价来自动选择的,也可以通过参数best_agg_plan来强制控制选择某种方法进行执行。best_agg_plan=1, 2, 3分别对应于上述三种方法,0为默认值,表示由产品自动选择最优计划。
在单DN上执行时,GaussDB(DWS)支持以下三种算法:
<1> Plain Agg:最终仅输出一行数据,适合于无聚集列的场景。
<2> HashAgg:使用Hash表来进行元组的去重,首先计算聚集列的hash值,hash值相同的再进行列值的比较,避免与所有数据比较后进行去重。去重时进行聚集函数的计算。适合于聚集后行数缩减较多的场景。
<3> Sort + GroupAgg:首先对数据按照聚集列进行排序,这样聚集列相等的元组均相邻,通过遍历一遍排序后的数据,即可完成元组的去重和聚集函数的计算。相较于<2>,适合于聚集后行数缩减较少的场景。
以上<2>和<3>的方法可以通过参数enable_sort和enable_hashagg来控制(默认均为on)。当enable_hashagg=on且enable_sort=off时,优先选择<2>;当enable_sort=on且enable_hashagg=off时,优先选择<3>。大数据量场景,通常HashAgg可以获得较好的性能,所以GaussDB(DWS)对HashAgg进行了较深入的优化。对于个别场景选择<3>的方法导致性能问题,可以通过关闭enable_sort来进行调优。
三.DISTINCT表达式
聚集函数中,均可以通过关键字DISTINCT对聚集列进行去重后进行计算,例如:COUNT(DISTINCT col)表示分组内col值不同的值的个数。
SELECT COUNT(DISTINCT(l_partkey)) FROM lineitem GROUP BY l_returnflag, l_linestatus; -- 计算每种发货状态下的不同零件数量
在分布式环境下,为了避免l_partkey相同的值在不同的DN上导致无法去重,GaussDB(DWS)对DISTINCT类操作进行了转换,上面语句等价于:
SELECT COUNT(l_partkey) FROM (select l_returnflag, l_linestatus, l_partkey FROM lineitem GROUP BY l_returnflag, l_linestatus, l_partkey) GROUP BY l_returnflag, l_linestatus;
这样,在GaussDB(DWS)中实际上使用两次Agg来计算DISTINCT表达式的值,计划如下:
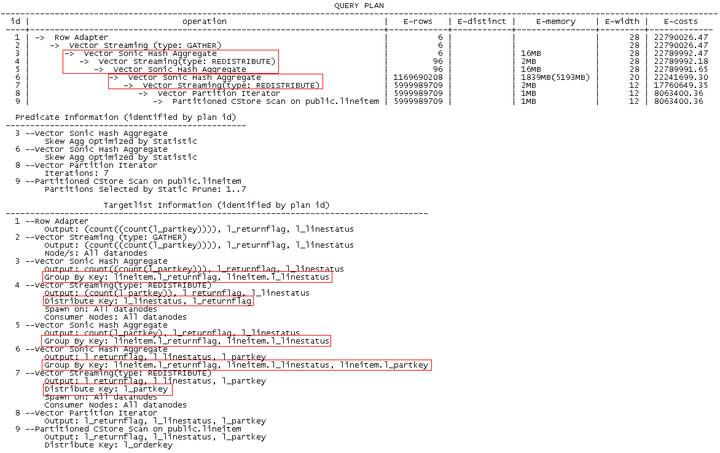
通过计划可以看出,第8-9层为lineitem基表扫描,上面有两次Agg处理COUNT(DISTINCT)算子。第6-7行为第一次Agg,聚集列为:l_returnflag, l_linestatus, l_partkey,选择Hashagg的方法二;第3-5行为第二次Agg,聚集列为:l_returnflag, l_linestatus,选择Hashagg的方法三。
注:目前SQL标准仅支持聚集函数中出现一列,对于要求多列的COUNT(DISTINCT),例如:COUNT(DISTINCT l_partkey, l_suppkey),实际可以通过手动使用上述改写方式进行求解:
SELECT COUNT(1) FROM (select l_returnflag, l_linestatus, l_partkey, l_suppkey FROM lineitem GROUP BY l_returnflag, l_linestatus, l_partkey, l_suppkey) GROUP BY l_returnflag, l_linestatus;
四.聚集扩展功能
在SQL 1999标准中,对聚集函数进行了扩展,新增了OLAP函数ROLLUP(), CUBE(), GROUPING SETS(),用于更灵活的多维数据分组统计功能。其实,这三个函数都可以使用简单的GROUP BY的集合合并操作(UNION ALL)来实现,本文中使用UNION ALL(GROUP BY x)来替代,例如:
GROUP BY a UNION ALL GROUP BY b的表达式中,x包括:(a), (b)。本文下面的讨论着重针对x进行。
- ROLLUP()是聚集列前缀的聚集结果的合并实现的,例如:
ROLLUP(a, b, c)中,x包括:(a,b,c), (a,b), (a), ()。(其中GROUP BY()表示所有行聚集到一组的无GROUP BY语义),对于n个聚集列,x中包含n+1个聚集组合。
ROLLUP()中的元素可以是列的集合,例如:
ROLLUP((a, b), (b, c)),x包括:(a,b,b,c)(等价于(a,b,c)), (a,b), ()。
- CUBE()是聚集列组合的枚举的聚集结果合并实现的,例如:
CUBE(a, b, c)中,x包括:(a,b,c), (a,b), (a,c), (b,c), (a), (b), (c), (),对于n个聚集列,x中包含2^n个聚集组合。
- GROUPING SETS()是聚集列的枚举的聚集结果合并实现的,例如:
GROUPING SETS(a, b, c, d)中,x包括:(a), (b), (c), (d),对于n个聚集列,x中包含n个聚集组合。
由于OLAP函数中,并不是聚集列均出现在每一个聚集结果中,所以增加GROUPING函数来标识参数列是否参与每一行聚集结果的运算,例如:对于CUBE(a, b, c),其中x包括:(a,b,c), (a,b), (a,c), (b,c), (a), (b), (c), ()时,对于x为(a,b,c), (a,b), (a,c), (a)的聚集结果行,GROUPING(a)的值为0,其它为1。
对于包含OLAP函数的如下语句:
select l_returnflag, l_linestatus, l_shipmode, sum(l_extendedprice), grouping(l_returnflag) from lineitem group by cube(1,2,3) order by 1,2,3;
GaussDB(DWS)的计划如下:
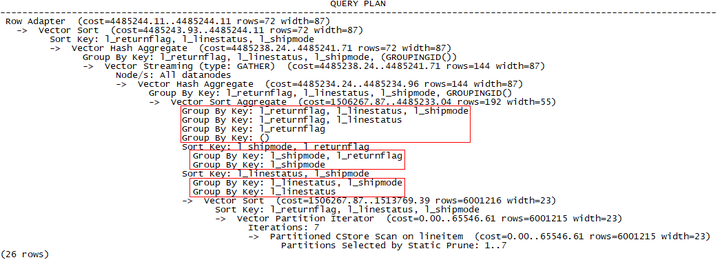
目前GaussDB(DWS)中使用Sort+GroupAgg来实现OLAP函数,后续版本会支持HashAgg进行执行,提高性能。
五.总结
聚集操作是SQL语言中的基本操作,只有深入了解聚集操作的语法、语义和支持的功能范围,才能更灵活地驾驭灵活的SQL语言进行开发,为学习更高阶的SQL语言打下良好的基础。
想了解GuassDB(DWS)更多信息,欢迎微信搜索“GaussDB DWS”关注微信公众号,和您分享最新最全的PB级数仓黑科技,后台还可获取众多学习资料哦~
深入解读SQL的聚集函数的更多相关文章
- SQL中的5种聚集函数
作为一个刚毕业进入这行的菜鸟,婶婶的觉的那种大神.大牛到底是怎样炼成的啊,我这小菜鸟感觉这TMD要学的东西这多啊,然后就给自己定了许多许多要学习的东西,可是有人又不停地给你灌输:东西不在多而要精通!我 ...
- SQL 聚集函数使用
SQL 聚集函数使用 (2009-04-14 15:50:36) 转载▼ 总结: 在SQL语句中同时包含where子句,groupby子句,having子句及聚集函数时的执行顺序: 1.按WHER ...
- SQL学习之汇总数据之聚集函数
一. 1.我们经常需要汇总数据而不用把他们实际检索出来,为此SQL提供了专门的函数,以便于分析数据和报表生成,这些函数的功能有: (1)确定表中行数(或者满足单个条件或多个条件或包含某个特定值的行数) ...
- SQL必知必会 -------- 聚集函数、分组排序
聚集函数 1.AVG()函数 输入:SELECT AVG(prod_price) AS avg_price FROM Products 输出: 警告:只用于单个列AVG()只能用来确定特定数值列的平均 ...
- SQL分组查询及聚集函数的使用
今天要做一个查询统计功能,一开始有点犯难,上午尝试大半天才写出统计sql语句,才发现自己sql分组查询及聚集函数没学好:其实就是group by子句和几个聚集函数,熟练使用统计功能很简单.在此总结下今 ...
- SQL中的5种常用的聚集函数
首先你要知道 where->group by->having->order by/limit ,这个就是写sql语句时的顺序 常用的5个聚集函数: Max ...
- 8.聚集函数 ---SQL
一.AVG()函数 A VG()通过对表中行数计数并计算其列值之和,求得该列的平均值.A VG()可用来返回所有列的平均值,也可以用来返回特定列或行的平均值. 警告:只用于单个列 AVG()只能用来确 ...
- SQL Server 聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值 ...
- HQL查询——聚集函数
HQL查询--聚集函数 HQL也支持在选出的属性上使用聚集函数.HQL支持的聚集函数与SQL的完全相同: (1)avg:计算属性平均值: (2)count:统计选择对象的数量: (3)max:统计属性 ...
随机推荐
- html5与css交互 API 《一》classList
用过jquery的朋友都知道,jquery提供的方法中(3个)可以很方便的为指定的节点添加.删除类选择器,即addClass.removeClass.toggleClass.具体的用法我这里就不谈了, ...
- mpvue小程序加载不出图片 Failed to load local image resource
我的GitHub博客,很多内容可以看,喜欢的给星星哦 https://github.com/liangfengbo/frontend 第一道:图片引入本地静态文件失效? mpvue开发小程序时候,要添 ...
- js随手笔记-------理解JavaScript碰撞检测算法核心简单实现原理
碰撞检测在前端游戏,设计拖拽的实用业务等领域的应用场景非常广泛,今天我们就在这里对于前端JavaScript如何实现碰撞检测算法进行一个原理上的探讨,让大家能够明白如何实现碰撞以及碰撞的理念是什么:1 ...
- 百度图像识别SDK实验
软件构造实验作业 实验名称:百度图像识别SDK实验 班级:信1905-1 学号:20194171 姓名:常金悦 一. 实验要求 每个步骤必须截图并说明 二.实验步 ...
- MySQL中MyISAM和InnoDB引擎的区别
区别: 1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事 ...
- 中小学数学卷子自动生成程序--对G同学的代码分析
前几天,在课程要求下完成了个人项目的项目工程编写,即一个中小学数学卷子自动生成程序. 程序主要功能是用户预设账户登录后可以选择等级进行对应的小中高的数学卷子对应出题生成txt文本. 本文针对partn ...
- .NET如何快速比较两个byte数组是否相等
目录 前言 评测方案 几种不同的方案 For循环 Memcmp 64字长优化 SIMD Sse Avx2 SequenceCompare 总结 参考文献 前言 之前在群里面有群友问过一个这样的问题,在 ...
- python---用顺序表实现栈
class Stack(object): """栈, 存放数据的一种容器, 后进先出""" def __init__(self): self ...
- vue--vuex 中 Modules 详解
前言 在Vue中State使用是单一状态树结构,应该的所有的状态都放在state里面,如果项目比较复杂,那state是一个很大的对象,store对象也将对变得非常大,难于管理.于是Vuex中就存在了另 ...
- js 轮播图 (原生)
注 : 此处内容较多, 只显示代码, 具体讲解看注释. 具体参考 "黑马 pink老师" https://www.bilibili.com/video/BV1Sy4y1C7h ...