【Hadoop学习】下:MapReduce程序编写、Hadoop序列化、框架原理、Yarn组件、设置队列
一、MapReduce概述
1、定义
编程框架,组成分布式运算程序,运行在集群上
2、特点
优点:易于编程、扩展性、容错性(内部完成)、海量数据离线处理
缺点:非实时、不擅长流式计算、不擅长DAG有向图计算
3、原理
编程思想:MapTask-->ReduceTask
三类进程:MrAppMaster(过程调度)、MapTask、ReduceTask(数据处理)
驱动类setjar设置jar包路径
maven打包并执行:右键->Run as->maven install
二、Hadoop序列化
1、概念
对象转换成字节序列
不用java序列化:重量级、序列化的对象附带额外信息
2、过程
定义bean实现序列化接口(Writable)
空参构造
重写序列化和反序列化方法
3、实操:统计手机号的上传下载流量
编写bean方法
编写mapper类
编写reducer类,分别对上行流量和下行流量累加
三、MapReduce框架原理
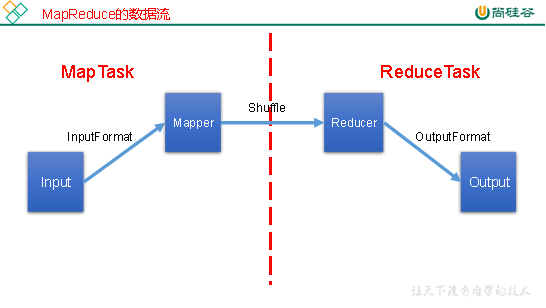
1、InputFormat数据输入
MapTask并行度决定机制:数据块和切片大小
2、FileInputFormat切片机制
按照文件长度切片,默认为block大小
缺陷:小文件
3、CombineTextInputFormat切片机制
可以将多个小文件从逻辑上规划到一个切片中
4、TextInputFormat的KV
读取记录,K是偏移量,V是内容
5、MapReduce工作流程
6、shuffle机制
Map方法之后,Reduce方法之前的数据处理过程
7、Partition分区
不同结果输出到不同的区中
实操:按照归属地省份分区到不同的文件中
8、自定义排序WritableComparable排序
实现WritableComparable接口重写compareTo方法
9、实操:全排序(按照总体流量排序)、区内排序(手机流量)
10、Combiner合并
局部汇总,不影响全局逻辑
多个重复的,按照数量汇总去重,计数
11、MapTask工作机制
、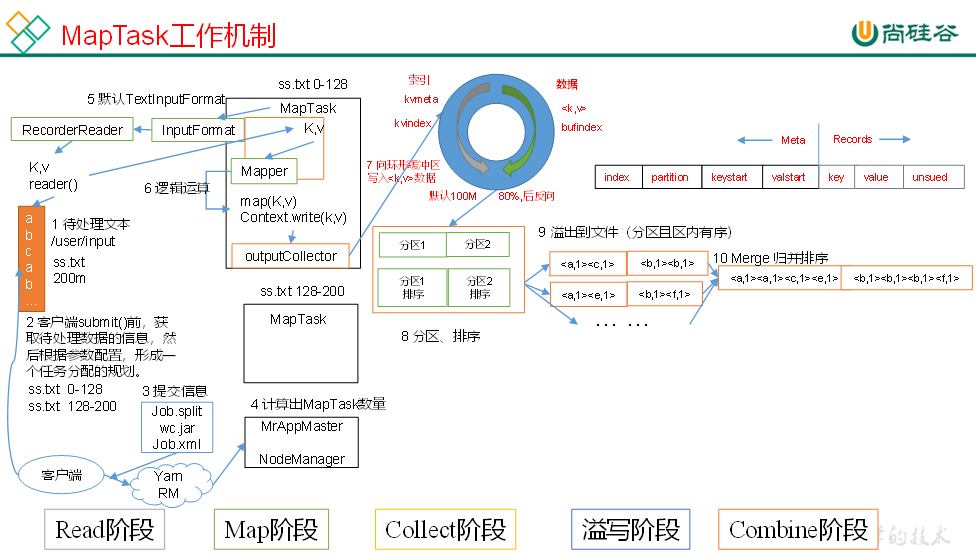
Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。
12、 ReduceTask工作机制
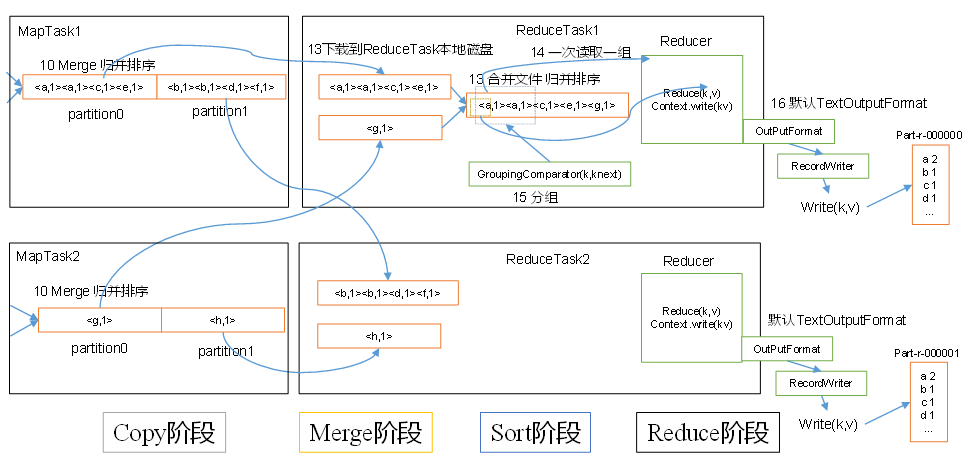
13、OutputFormat数据输出
控制文本输出路径和格式
可以使用自定义OutputFormat
14、Join多种应用
区别不同来源的记录
Reduce Join(reduce阶段完成,压力大)
Map Join(一张表大,一张表小)
15、计数器应用
数据清洗(ETL):去除小于11的日志



四、Yarn资源调度器
1、架构组成
ResourceManager、NodeManager、ApplicationMaster和Container
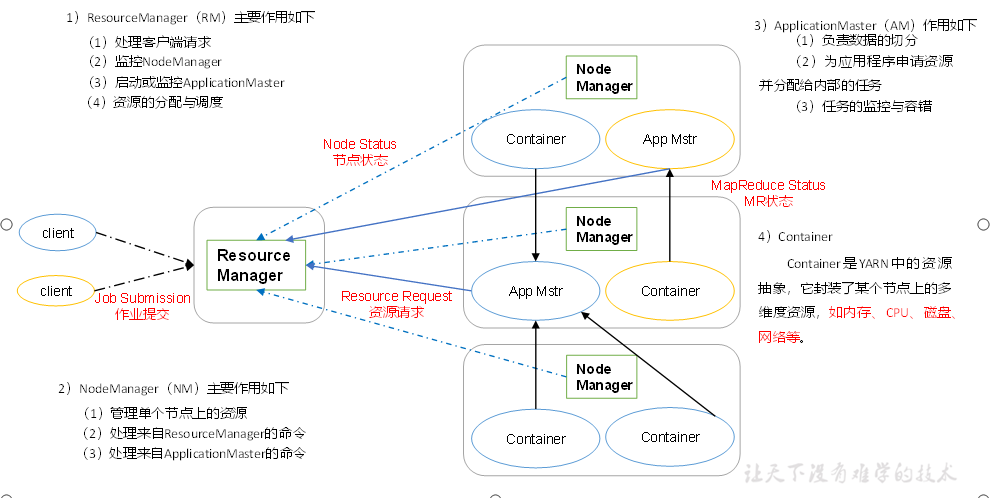
2、工作机制
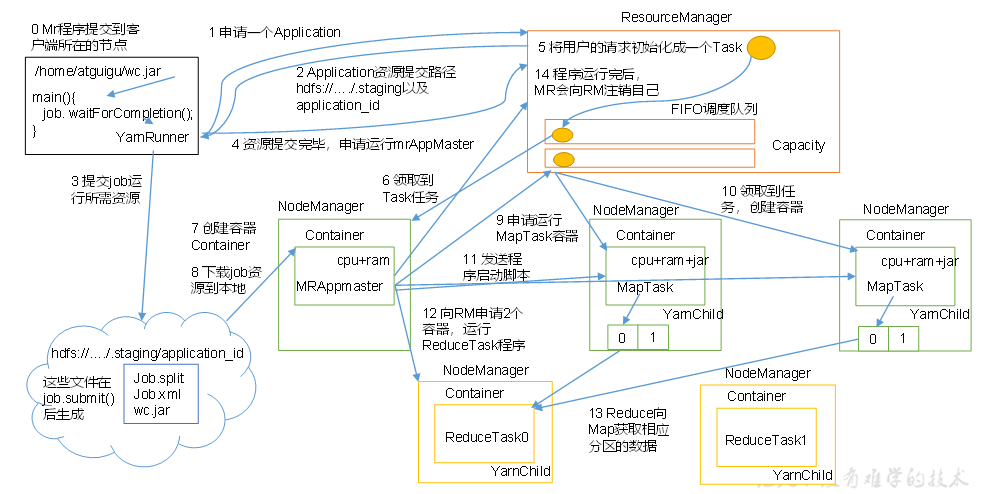
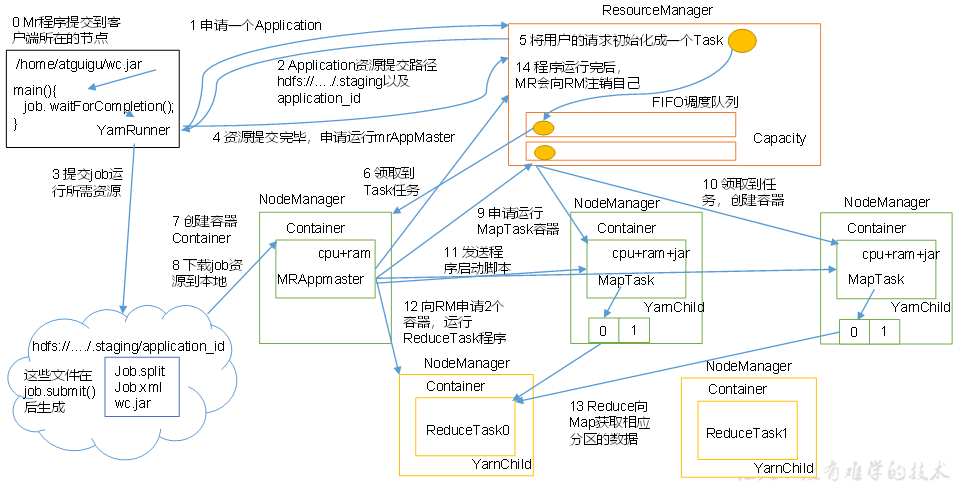
3、作业提交全过程
4、资源调度器
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler
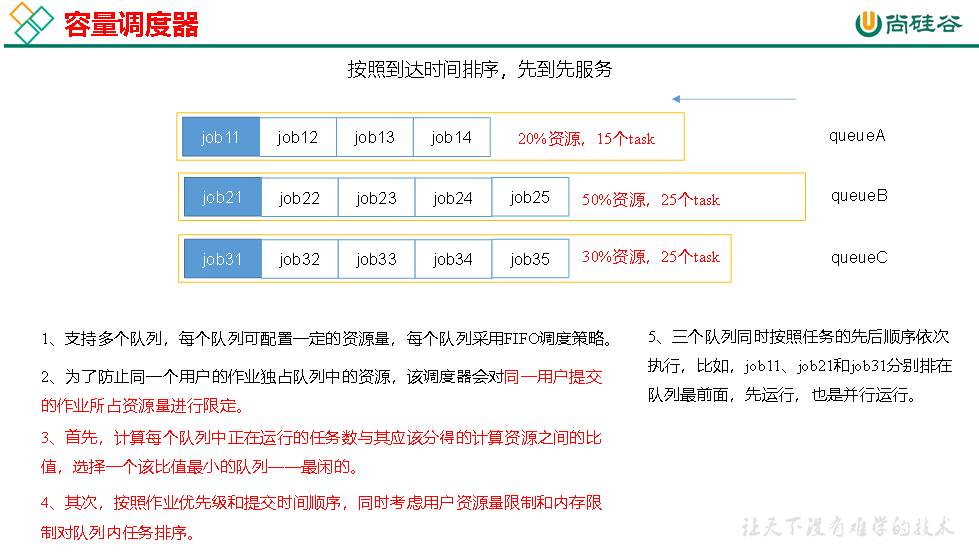
选择比值最小的队列
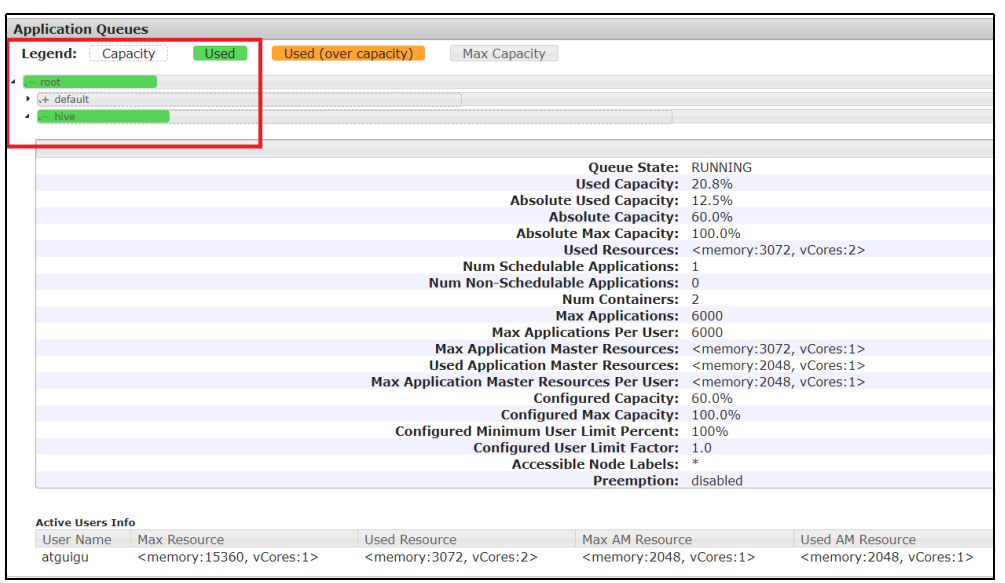
5、分业务限制集群使用率。这就需要我们按照业务种类配置多条任务队列。
capacity-scheduler.xml中可以配置多条队列
重启yarn就可以进行查看
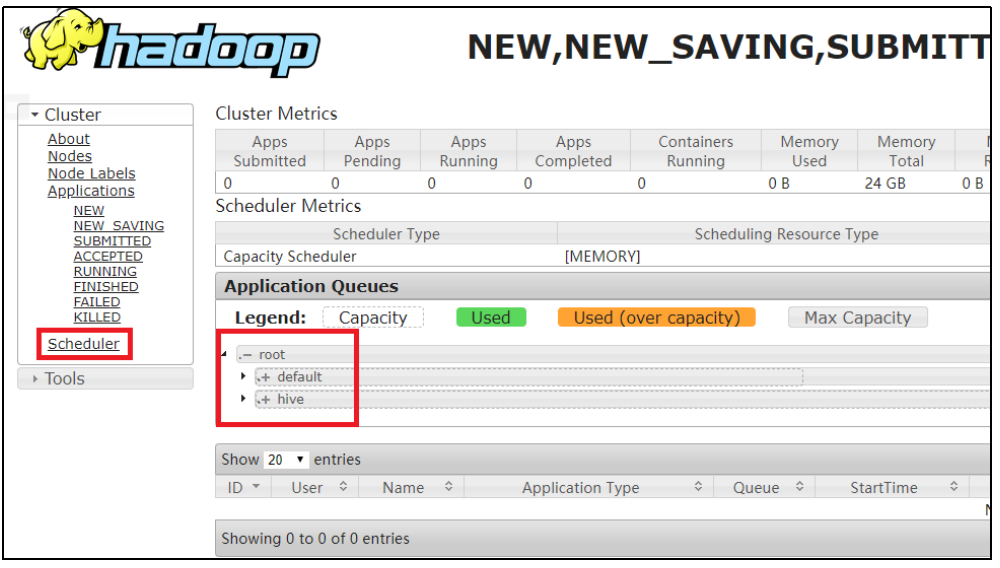
向hive队列提交任务
Driver中声明
configuration.set("mapred.job.queue.name", "hive");
【Hadoop学习】下:MapReduce程序编写、Hadoop序列化、框架原理、Yarn组件、设置队列的更多相关文章
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- Hadoop学习(3)-mapreduce快速入门加yarn的安装
mapreduce是一个运算框架,让多台机器进行并行进行运算, 他把所有的计算都分为两个阶段,一个是map阶段,一个是reduce阶段 map阶段:读取hdfs中的文件,分给多个机器上的maptask ...
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- Hadoop学习(4)-mapreduce的一些注意事项
关于mapreduce的一些注意细节 如果把mapreduce程序打包放到了liux下去运行, 命令java –cp xxx.jar 主类名 如果报错了,说明是缺少相关的依赖jar包 用命令had ...
- hadoop 第一个 mapreduce 程序(对MapReduce的几种固定代码的理解)
1.2MapReduce 和 HDFS 是如何工作的 MapReduce 其实是两部分,先是 Map 过程,然后是 Reduce 过程.从词频计算来说,假设某个文件块里的一行文字是”Thisis a ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- Eclipse导入Hadoop源码项目及编写Hadoop程序
一 Eclipse导入Hadoop源码项目 基本步骤: 1)在Eclipse新建一个java项目[hadoop-1.2.1] 2)将Hadoop压缩包解压目录src下的core,hdfs,mapred ...
- hadoop学习day3 mapreduce笔记
1.对于要处理的文件集合会根据设定大小将文件分块,每个文件分成多块,不是把所有文件合并再根据大小分块,每个文件的最后一块都可能比设定的大小要小 块大小128m a.txt 120m 1个块 b.txt ...
- Hadoop_05_运行 Hadoop 自带 MapReduce程序
1. MapReduce使用 MapReduce是Hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现 一个强大的海量数据并发处理程序 2. 运行Hadoop自 ...
随机推荐
- 如何在Elasticsearch中使用pipeline API来对事件进行处理
一个processor就像是Logstash里的一个filter pipeline是一组processor
- PAT (Basic Level) Practice 1019 数字黑洞 分数 20
给定任一个各位数字不完全相同的 4 位正整数,如果我们先把 4 个数字按非递增排序,再按非递减排序,然后用第 1 个数字减第 2 个数字,将得到一个新的数字.一直重复这样做,我们很快会停在有" ...
- Go设计模式学习准备——下载bilibili合集视频
需求 前段时间面试,被问到设计模式.说实话虽然了解面向对象.多态,但突然被问到设计模式,还要说清解决什么问题,自己是有些懵的,毕竟实习主要工作是在原项目基础进行CRUD,自己还是没有深度思考,所以只能 ...
- 前端程序员学习 Golang gin 框架实战笔记之一开始玩 gin
原文链接 我是一名五六年经验的前端程序员,现在准备学习一下 Golang 的后端框架 gin. 以下是我的学习实战经验,记录下来,供大家参考. https://github.com/gin-gonic ...
- springmvc 上传文件时的错误
使用springmvc上传文件一直失败,文件参数一直为null, 原来是配置文件没写成功. <bean id="multipartResolver" class=" ...
- ASP.NET Core :缓存系列(四):内存缓存 MemoryCache
System.Runtime.Caching/MemoryCache ICacheEntry 接口中的属性:具体设置过期时间 可以参考:微软文档ICacheEntry 接口 缓存基本使用 (一) 绝对 ...
- 记一个深层的bug
1. 业务场景 产品需要每隔几天进行一次组件的更新,在自动化测试中,每隔30s检测一次更新源上的某个文件MD5值是否与本地一致,不一致代表有更新的版本,开始更新. 2. 问题出现 一个再平常不过的繁忙 ...
- 齐博x1where 标签动态变量查询/where 实现条件筛选与数据关联
大家可能对union参数不太习惯的话,也可以用where语句加入动态变量查询,比如 where="fid=$fid&uid=$info[uid]&pid>=$info. ...
- 利用inotify和rsync服务实现数据实时同步
文件定时同步的实现: 利用rsync结合cron计划任务实现: rsync -av --delete /data/ 10.0.0.12:/back -a:保留文件属性 -v:显示过程 -delete: ...
- 优化if、elif过多
优化if ,elif过多的场景 字典的成员运算,是判断字典的key 思路:把函数的内存地址存到字典当中 def login(): pass def scan(): pass def transf ...