论文解读(GMIM)《Deep Graph Clustering via Mutual Information Maximization and Mixture Model》
论文信息
论文标题:Deep Graph Clustering via Mutual Information Maximization and Mixture Model
论文作者:Maedeh Ahmadi, Mehran Safayani, Abdolreza Mirzaei
论文来源:2022, arXiv
论文地址:download
论文代码:download
1 Introduction
结合高斯混合模型+对比学习。
2 Method
总体框架
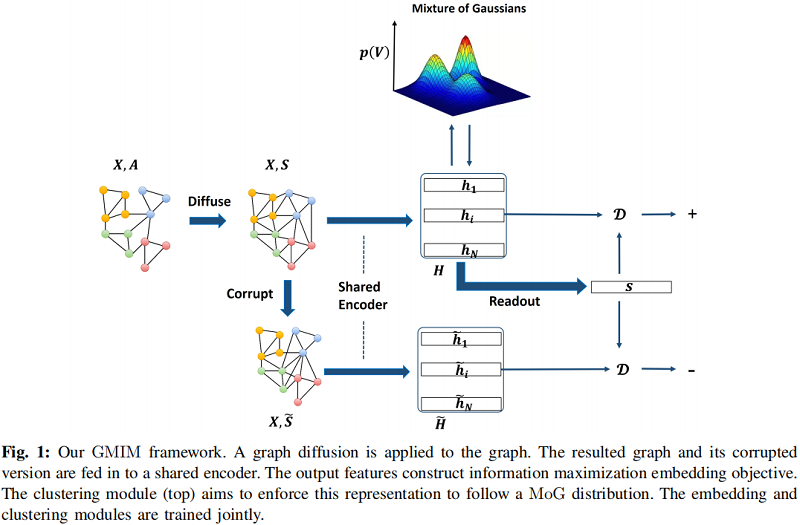
2.1 Node Embedding
Encoder : $\mathcal{E}(X, A)=H=\left\{h_{1}, h_{2}, \ldots, h_{N}\right\} \in \mathbb{R}^{N \times F}$
本文选取的 Encoder 是单层的 GCN:
$\mathcal{E}(X, A)=\operatorname{PReLU}\left(\widehat{D}^{-\frac{1}{2}} \hat{A} \widehat{D}^{-\frac{1}{2}} X \Phi\right) \quad\quad\quad(3)$
通过一个破坏函数 $\tilde{G}=C(G)$ 打乱 $X$ 的行,生成负图 $\tilde{G}$。
Readout function :
获得图级表示:
$s=\mathcal{R}(H)=\sigma\left(1 / N \sum_{i=1}^{N} h_{i}\right)$
鉴别器(discriminator):
$\mathcal{D}(h, s)=\sigma\left(h^{T} W s\right) \quad\quad\quad(1)$
为了使 $h_{i}$ 和和向量 $s$ 之间的互信息最大化,采用最小化下述交叉熵损失:
${\large \mathcal{L}_{M I}=-\frac{1}{2 N}\left(\sum\limits _{i=1}^{N} \mathbb{E}_{(X, A)}\left[\log \mathcal{D}\left(h_{i}, s\right)\right]+\sum\limits _{j=1}^{N} \mathbb{E}_{(\tilde{X}, \tilde{A})}\left[\log \left(1-\mathcal{D}\left(\tilde{h}_{j}, s\right)\right)\right]\right)} \quad\quad\quad(2)$
2.2 Graph Diffusion
消息传递的神经网络在图的直接节点之间传递消息。虽然他们试图在深层聚合来自高阶邻居的消息,但由于过度平滑现象,他们大多数在 $2$ 层网络中达到了最好的性能。只获取一跳的邻居信息是存在局限性的,一些方法试图捕获图中的高阶信息。其中一个成功的方法之一是图扩散卷积(GDC)。它用一个扩散矩阵代替邻接矩阵,并表示为
$S=\sum\limits _{k=0}^{\infty} \Theta_{k} T^{k} \quad\quad\quad(4)$
典型的图扩散 Personalized PageRank (PPR),PPR 扩散的封闭形式的解决方案如下:
$S^{\mathrm{PPR}}=\alpha\left(I_{n}-(1-\alpha) D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\right)^{-1} \quad\quad\quad(5)$
其中,$T=A D^{-1}$ ,$ \Theta_{k}=\alpha(1-\alpha)^{k}$.
2.1.3 Gaussian Mixture Modeling for Community Detection
假设通过一个参数为 $\Psi $ 的节点嵌入模型,为图中的每个节点计算了一个节点嵌入 $v_{i}$。本文认为每个节点都是由一个多元高斯分布生成的。然后,图中所有节点的高斯混合模型的似然值:
$p(V)=\prod_{i=1}^{|V|} \sum\limits _{K=1}^{K} p\left(c_{i}=k\right) p\left(v_{i} \mid c_{i}=k ; \Psi, \mu_{k}, \Sigma_{k}\right) \quad\quad\quad(6)$
这里 $c_{i}$ 表示节点 $i$ 的软社区分配,$p\left(c_{i}=k\right)$ 表示节点 $i$ 被分配给社区 $k$ 的概率。$p\left(v_{i} \mid c_{i}=k ; \Psi, \mu_{k}, \Sigma_{k}\right)$ 是一个多元高斯分布如下:
$p\left(v_{i} \mid c_{i}=k ; \Psi, \mu_{k}, \Sigma_{k}\right)=N\left(h_{i} \mid \mu_{k}, \Sigma_{k}\right) \quad\quad\quad(7)$
为方便,将 $p\left(c_{i}=k\right) $ 表示为 $\pi_{i, k}$,其中 $\sum\limits _{k=1}^{K} \pi_{i, k}=1$。对于 $i=1, \ldots,|V|$ 和$k=1, \ldots, K$,高斯混合的参数是 $\Pi=\left\{\pi_{i, k}\right\}, M=\left\{\mu_{k}\right\}$ 和 $\sum\limits =\left\{\Sigma_{k}\right\}$ 。假设协方差矩阵 $\Sigma_{k}$ 是对角矩阵。
2.1.4 Clustering-friendly Node Embedding
我们提出了一个促进聚类的目标,它输出一个适合聚类的潜在空间。我们假设学习到的潜在空间遵循一个MoG分布。我们定义的目标函数有两部分:嵌入和聚类。嵌入部分利用LMI的自学习目标进行节点表示学习,聚类模块试图强制执行这种表示,以遵循 MoG 分布。后一个目标是通过最小化 MoG 分布下的负对数似然(NLL)来实现的:
$L_{N L L}=-\sum\limits _{i=1}^{|V|} \log \sum\limits _{k=1}^{K} \pi_{i, k} \mathcal{N}\left(h_{i} \mid \mu_{k}, \Sigma_{k}\right) \quad\quad\quad(8)$
我们的总损失函数被定义为:
$\mathcal{L}=\omega \mathcal{L}_{M I}+\beta \mathcal{L}_{N L L} \quad\quad\quad(9)$
其中,$\mathcal{L}_{M I}$ 和 $\mathcal{L}_{N L L}$ 分别为互信息损失和负对数似然(NLL)。在优化了我们的目标之后,我们有了一个k-means友好的潜在空间,在这个空间上我们应用k-means算法来得到最终的节点簇。
2.1.5 Inference
总损失函数由两组参数组成:节点嵌入参数( $\Psi$ )和MoG参数($\Pi$、$M$ 和 $\Sigma$)。为了优化这些参数,我们使用了一种迭代的方法,通过固定一个集合和优化另一个集合。我们通过使用 $\text{Eq.2}$ 作为损失函数来训练模型来初始化 $\Psi$ 参数。为了初始化MoG参数,我们对 $\Psi $ 初始化实现的嵌入应用 K-means 算法。我们使用K-means算法的硬分配结果进行初始化( $\Pi$, $M$, $\Sigma$)。这种迭代方法的细节如下所述。
Fixing $\Psi$ Parameters and Optimizing $(\Pi, M, \Sigma)$
固定深度网络参数,我们使用期望最大化算法进行优化$(\Pi, M, \Sigma)$。使用以下方程迭代更新这些参数:
$\pi_{i, k}=\frac{N_{k}}{|V|} \quad\quad\quad(10)$
$\mu_{k}=\frac{1}{N_{k}} \sum\limits _{i=1}^{|V|} \mathcal{V}_{i k} h_{i} \quad\quad\quad(11)$
$\Sigma_{k}=\frac{1}{N_{k}} \sum\limits _{i=1}^{|V|} \mathcal{V}_{i k}\left(h_{i}-\mu_{k}\right)\left(h_{i}-\mu_{k}\right)^{T} \quad\quad\quad(12)$
其中
$\mathcal{V}_{i k}=\frac{\pi_{i, k} \mathcal{N}\left(h_{i} \mid \mu_{k}, \Sigma_{k}\right)}{\sum\limits _{k^{\prime}=1}^{K} \pi_{i, k^{\prime}} \mathcal{N}\left(h_{i} \mid \mu_{k^{\prime}}, \Sigma_{k^{\prime}}\right)} \quad\quad\quad(13)$
$\mathcal{N}_{k}=\sum\limits _{i=1}^{|V|} \mathcal{V}_{i} k \quad 1 \leq k \leq K \quad\quad\quad(14)$
Fixing $(\Pi, M, \Sigma)$ and Updating $\Psi$ Parameters
在固定 MoG 参数后,我们使用随机梯度下降(SGD)优化了相对于 $\Psi$ 参数的总损失函数 $\text{Eq.6}$。$\Psi$由的可学习评分矩阵$W$、编码器参数 $\Phi $ 和的PReLU参数组成。Algorithm 1 总结了我们提出的方法。

3 Experiment
数据集
在我们的实验中,我们使用了两个广泛使用的标准网络数据集(Cora和Pubmed)来进行属性图社区检测。
在Cora数据集上的聚类结果

在 Pubmed 数据集上的可视化结果

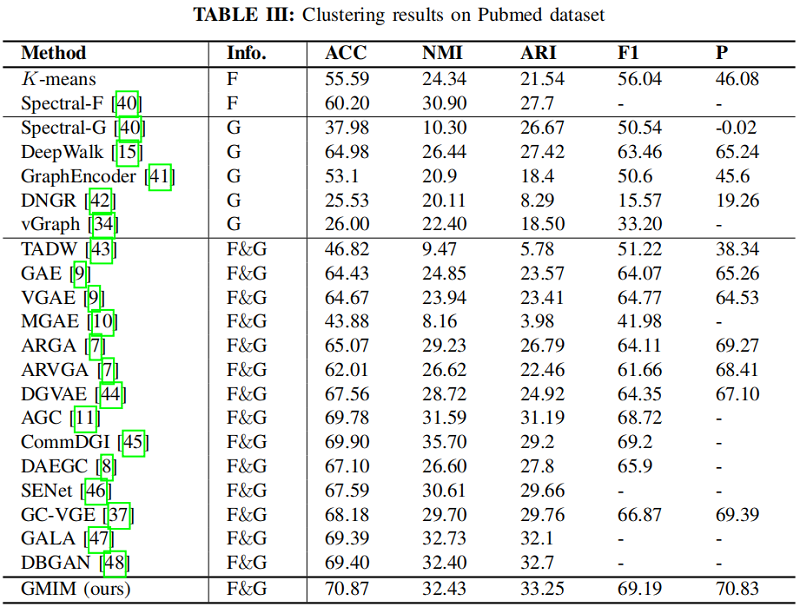
在 Pubmed 数据集上的聚类结果
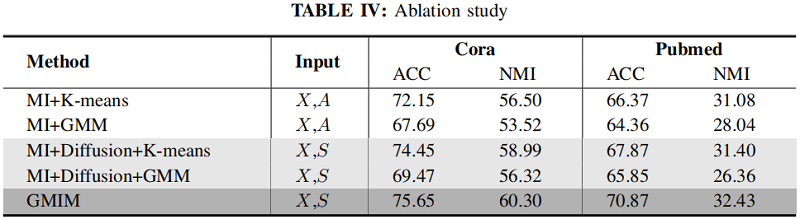
消融实验
4 Conclusion
本文介绍了一个用于节点嵌入的聚类促进目标。我们提出的方法利用对比学习来产生一个聚类友好的潜在空间,假设学习到的表示遵循一个高斯分布的混合。嵌入和聚类目标在一个统一的框架中进行优化,以相互受益。实验表明,结合聚类定向目标函数可以提高图对比学习的聚类能力。我们在真实数据集上评估了该方法的有效性,以证明其有效性,经验结果证明了我们的方法具有良好的性能。
论文解读(GMIM)《Deep Graph Clustering via Mutual Information Maximization and Mixture Model》的更多相关文章
- 论文解读( N2N)《Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization》
论文信息 论文标题:Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximiz ...
- 论文解读(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》
论文信息 论文标题:Deep Graph Clustering via Dual Correlation Reduction论文作者:Yue Liu, Wenxuan Tu, Sihang Zhou, ...
- 论文解读《Deep Attention-guided Graph Clustering with Dual Self-supervision》
论文信息 论文标题:Deep Attention-guided Graph Clustering with Dual Self-supervision论文作者:Zhihao Peng, Hui Liu ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》2
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读《Bilinear Graph Neural Network with Neighbor Interactions》
论文信息 论文标题:Bilinear Graph Neural Network with Neighbor Interactions论文作者:Hongmin Zhu, Fuli Feng, Xiang ...
- 论文解读《Deep Resdual Learning for Image Recognition》
总的来说这篇论文提出了ResNet架构,让训练非常深的神经网络(NN)成为了可能. 什么是残差? "残差在数理统计中是指实际观察值与估计值(拟合值)之间的差."如果回归模型正确的话 ...
- 论文解读《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernel》
Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels: 一旦退化模型被定义,下一步就是使用公式表示能量函数(energy fun ...
- 论文解读《Cauchy Graph Embedding》
Paper Information Title:Cauchy Graph EmbeddingAuthors:Dijun Luo, C. Ding, F. Nie, Heng HuangSources: ...
随机推荐
- 顺利通过EMC实验(19)
- Asp.Net Core之Identity应用(下篇)
一.前言 在上篇中简单介绍了 Asp.Net Core 自带的 Identity,一个负责对用户的身份进行认证的框架,当我们按需选择这个框架作为管理和存储我们应用中的用户账号数据的时候,就会添加到自己 ...
- CSS: 给表格的第一列和最后一列不同的样式
table td:first-child { width:160px; height:20px; border:solid 1px Black; padding:5px; text-align:cen ...
- 居中的css:完全指南(翻译)
这里主要参考的是CHRIS COYIER写的一篇的文章(点击查看),主要讲了关于css水平.垂直居中的一些方法,每个方法后面都有一个demo,可以在线查看效果. 1 水平 水平居中有行内元素和块元素, ...
- 微信小程序自定义tab,多层tab嵌套实现
小程序最近是越来越火了-- 做小程序有一段时间了,总结一下项目中遇到的问题及解决办法吧. 项目中有个多 tab 嵌套的需求,进入程序主界面下面有两个 tab,进入A模块后,A模块最底下又有多个tab, ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- Unknown host mirrors.opencas.cn You may need to adjust the proxy settings in Gradle 报错及解决办法
亲测Unknown host mirrors.opencas.cn You may need to adjust the proxy settings in Gradle 解决办法 - 程序员大本营 ...
- 解决 Tomcat 控制台输出乱码(Tomcat Localhost Log / Tomcat Catalina Log 乱码)
1. 按下图修改 先找到你的 Tomcat 安装目录,然后进入conf文件夹,找到 logging.properties,并打开它,然后把所有 UTF-8 格式的编码改成 GBK即可,具体操作如下图
- 使用element UI el-upload组件实现视频文件上传及上传进度显示方法总结
实现效果: 上传中: 上传完成: 代码: <el-form-item label="视频上传" prop="Video"> <!-- acti ...
- selenium打开指定Chrome账号
selenium打开指定Chrome账号 获取User Data路径 打开目标Chrome,在搜索栏输入chrome://version,找到"个人资料路径". 这里获取到的路径为 ...