论文解读(GMIM)《Deep Graph Clustering via Mutual Information Maximization and Mixture Model》
论文信息
论文标题:Deep Graph Clustering via Mutual Information Maximization and Mixture Model
论文作者:Maedeh Ahmadi, Mehran Safayani, Abdolreza Mirzaei
论文来源:2022, arXiv
论文地址:download
论文代码:download
1 Introduction
结合高斯混合模型+对比学习。
2 Method
总体框架
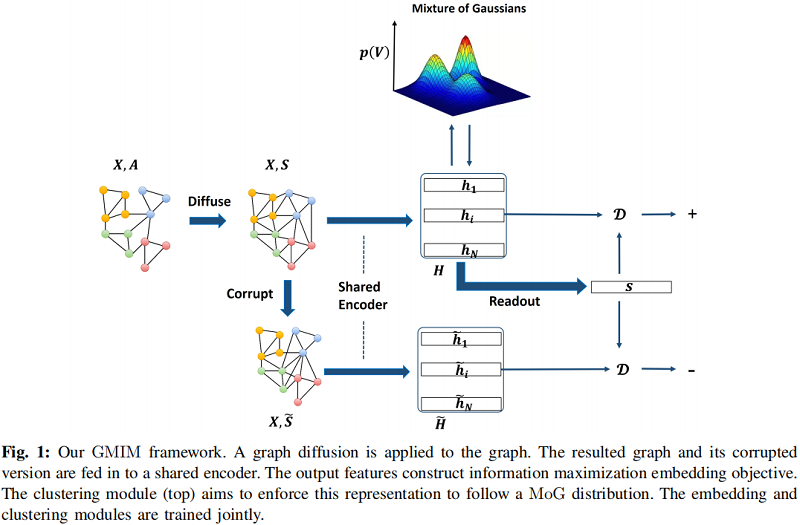
2.1 Node Embedding
Encoder : $\mathcal{E}(X, A)=H=\left\{h_{1}, h_{2}, \ldots, h_{N}\right\} \in \mathbb{R}^{N \times F}$
本文选取的 Encoder 是单层的 GCN:
$\mathcal{E}(X, A)=\operatorname{PReLU}\left(\widehat{D}^{-\frac{1}{2}} \hat{A} \widehat{D}^{-\frac{1}{2}} X \Phi\right) \quad\quad\quad(3)$
通过一个破坏函数 $\tilde{G}=C(G)$ 打乱 $X$ 的行,生成负图 $\tilde{G}$。
Readout function :
获得图级表示:
$s=\mathcal{R}(H)=\sigma\left(1 / N \sum_{i=1}^{N} h_{i}\right)$
鉴别器(discriminator):
$\mathcal{D}(h, s)=\sigma\left(h^{T} W s\right) \quad\quad\quad(1)$
为了使 $h_{i}$ 和和向量 $s$ 之间的互信息最大化,采用最小化下述交叉熵损失:
${\large \mathcal{L}_{M I}=-\frac{1}{2 N}\left(\sum\limits _{i=1}^{N} \mathbb{E}_{(X, A)}\left[\log \mathcal{D}\left(h_{i}, s\right)\right]+\sum\limits _{j=1}^{N} \mathbb{E}_{(\tilde{X}, \tilde{A})}\left[\log \left(1-\mathcal{D}\left(\tilde{h}_{j}, s\right)\right)\right]\right)} \quad\quad\quad(2)$
2.2 Graph Diffusion
消息传递的神经网络在图的直接节点之间传递消息。虽然他们试图在深层聚合来自高阶邻居的消息,但由于过度平滑现象,他们大多数在 $2$ 层网络中达到了最好的性能。只获取一跳的邻居信息是存在局限性的,一些方法试图捕获图中的高阶信息。其中一个成功的方法之一是图扩散卷积(GDC)。它用一个扩散矩阵代替邻接矩阵,并表示为
$S=\sum\limits _{k=0}^{\infty} \Theta_{k} T^{k} \quad\quad\quad(4)$
典型的图扩散 Personalized PageRank (PPR),PPR 扩散的封闭形式的解决方案如下:
$S^{\mathrm{PPR}}=\alpha\left(I_{n}-(1-\alpha) D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\right)^{-1} \quad\quad\quad(5)$
其中,$T=A D^{-1}$ ,$ \Theta_{k}=\alpha(1-\alpha)^{k}$.
2.1.3 Gaussian Mixture Modeling for Community Detection
假设通过一个参数为 $\Psi $ 的节点嵌入模型,为图中的每个节点计算了一个节点嵌入 $v_{i}$。本文认为每个节点都是由一个多元高斯分布生成的。然后,图中所有节点的高斯混合模型的似然值:
$p(V)=\prod_{i=1}^{|V|} \sum\limits _{K=1}^{K} p\left(c_{i}=k\right) p\left(v_{i} \mid c_{i}=k ; \Psi, \mu_{k}, \Sigma_{k}\right) \quad\quad\quad(6)$
这里 $c_{i}$ 表示节点 $i$ 的软社区分配,$p\left(c_{i}=k\right)$ 表示节点 $i$ 被分配给社区 $k$ 的概率。$p\left(v_{i} \mid c_{i}=k ; \Psi, \mu_{k}, \Sigma_{k}\right)$ 是一个多元高斯分布如下:
$p\left(v_{i} \mid c_{i}=k ; \Psi, \mu_{k}, \Sigma_{k}\right)=N\left(h_{i} \mid \mu_{k}, \Sigma_{k}\right) \quad\quad\quad(7)$
为方便,将 $p\left(c_{i}=k\right) $ 表示为 $\pi_{i, k}$,其中 $\sum\limits _{k=1}^{K} \pi_{i, k}=1$。对于 $i=1, \ldots,|V|$ 和$k=1, \ldots, K$,高斯混合的参数是 $\Pi=\left\{\pi_{i, k}\right\}, M=\left\{\mu_{k}\right\}$ 和 $\sum\limits =\left\{\Sigma_{k}\right\}$ 。假设协方差矩阵 $\Sigma_{k}$ 是对角矩阵。
2.1.4 Clustering-friendly Node Embedding
我们提出了一个促进聚类的目标,它输出一个适合聚类的潜在空间。我们假设学习到的潜在空间遵循一个MoG分布。我们定义的目标函数有两部分:嵌入和聚类。嵌入部分利用LMI的自学习目标进行节点表示学习,聚类模块试图强制执行这种表示,以遵循 MoG 分布。后一个目标是通过最小化 MoG 分布下的负对数似然(NLL)来实现的:
$L_{N L L}=-\sum\limits _{i=1}^{|V|} \log \sum\limits _{k=1}^{K} \pi_{i, k} \mathcal{N}\left(h_{i} \mid \mu_{k}, \Sigma_{k}\right) \quad\quad\quad(8)$
我们的总损失函数被定义为:
$\mathcal{L}=\omega \mathcal{L}_{M I}+\beta \mathcal{L}_{N L L} \quad\quad\quad(9)$
其中,$\mathcal{L}_{M I}$ 和 $\mathcal{L}_{N L L}$ 分别为互信息损失和负对数似然(NLL)。在优化了我们的目标之后,我们有了一个k-means友好的潜在空间,在这个空间上我们应用k-means算法来得到最终的节点簇。
2.1.5 Inference
总损失函数由两组参数组成:节点嵌入参数( $\Psi$ )和MoG参数($\Pi$、$M$ 和 $\Sigma$)。为了优化这些参数,我们使用了一种迭代的方法,通过固定一个集合和优化另一个集合。我们通过使用 $\text{Eq.2}$ 作为损失函数来训练模型来初始化 $\Psi$ 参数。为了初始化MoG参数,我们对 $\Psi $ 初始化实现的嵌入应用 K-means 算法。我们使用K-means算法的硬分配结果进行初始化( $\Pi$, $M$, $\Sigma$)。这种迭代方法的细节如下所述。
Fixing $\Psi$ Parameters and Optimizing $(\Pi, M, \Sigma)$
固定深度网络参数,我们使用期望最大化算法进行优化$(\Pi, M, \Sigma)$。使用以下方程迭代更新这些参数:
$\pi_{i, k}=\frac{N_{k}}{|V|} \quad\quad\quad(10)$
$\mu_{k}=\frac{1}{N_{k}} \sum\limits _{i=1}^{|V|} \mathcal{V}_{i k} h_{i} \quad\quad\quad(11)$
$\Sigma_{k}=\frac{1}{N_{k}} \sum\limits _{i=1}^{|V|} \mathcal{V}_{i k}\left(h_{i}-\mu_{k}\right)\left(h_{i}-\mu_{k}\right)^{T} \quad\quad\quad(12)$
其中
$\mathcal{V}_{i k}=\frac{\pi_{i, k} \mathcal{N}\left(h_{i} \mid \mu_{k}, \Sigma_{k}\right)}{\sum\limits _{k^{\prime}=1}^{K} \pi_{i, k^{\prime}} \mathcal{N}\left(h_{i} \mid \mu_{k^{\prime}}, \Sigma_{k^{\prime}}\right)} \quad\quad\quad(13)$
$\mathcal{N}_{k}=\sum\limits _{i=1}^{|V|} \mathcal{V}_{i} k \quad 1 \leq k \leq K \quad\quad\quad(14)$
Fixing $(\Pi, M, \Sigma)$ and Updating $\Psi$ Parameters
在固定 MoG 参数后,我们使用随机梯度下降(SGD)优化了相对于 $\Psi$ 参数的总损失函数 $\text{Eq.6}$。$\Psi$由的可学习评分矩阵$W$、编码器参数 $\Phi $ 和的PReLU参数组成。Algorithm 1 总结了我们提出的方法。

3 Experiment
数据集
在我们的实验中,我们使用了两个广泛使用的标准网络数据集(Cora和Pubmed)来进行属性图社区检测。
在Cora数据集上的聚类结果

在 Pubmed 数据集上的可视化结果

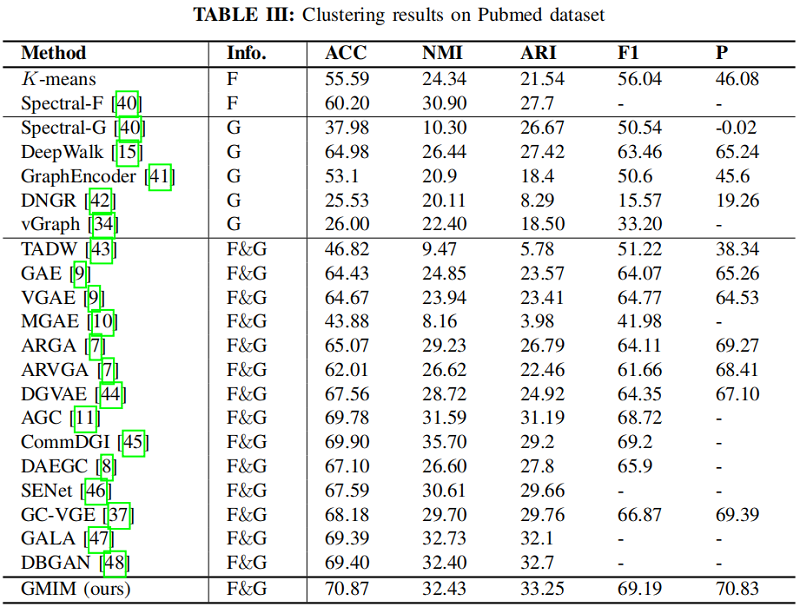
在 Pubmed 数据集上的聚类结果
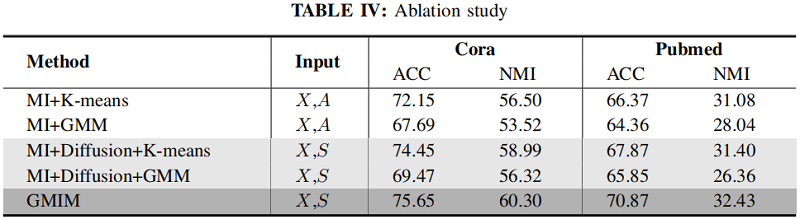
消融实验
4 Conclusion
本文介绍了一个用于节点嵌入的聚类促进目标。我们提出的方法利用对比学习来产生一个聚类友好的潜在空间,假设学习到的表示遵循一个高斯分布的混合。嵌入和聚类目标在一个统一的框架中进行优化,以相互受益。实验表明,结合聚类定向目标函数可以提高图对比学习的聚类能力。我们在真实数据集上评估了该方法的有效性,以证明其有效性,经验结果证明了我们的方法具有良好的性能。
论文解读(GMIM)《Deep Graph Clustering via Mutual Information Maximization and Mixture Model》的更多相关文章
- 论文解读( N2N)《Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization》
论文信息 论文标题:Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximiz ...
- 论文解读(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》
论文信息 论文标题:Deep Graph Clustering via Dual Correlation Reduction论文作者:Yue Liu, Wenxuan Tu, Sihang Zhou, ...
- 论文解读《Deep Attention-guided Graph Clustering with Dual Self-supervision》
论文信息 论文标题:Deep Attention-guided Graph Clustering with Dual Self-supervision论文作者:Zhihao Peng, Hui Liu ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》2
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读《Bilinear Graph Neural Network with Neighbor Interactions》
论文信息 论文标题:Bilinear Graph Neural Network with Neighbor Interactions论文作者:Hongmin Zhu, Fuli Feng, Xiang ...
- 论文解读《Deep Resdual Learning for Image Recognition》
总的来说这篇论文提出了ResNet架构,让训练非常深的神经网络(NN)成为了可能. 什么是残差? "残差在数理统计中是指实际观察值与估计值(拟合值)之间的差."如果回归模型正确的话 ...
- 论文解读《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernel》
Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels: 一旦退化模型被定义,下一步就是使用公式表示能量函数(energy fun ...
- 论文解读《Cauchy Graph Embedding》
Paper Information Title:Cauchy Graph EmbeddingAuthors:Dijun Luo, C. Ding, F. Nie, Heng HuangSources: ...
随机推荐
- Volcano:在离线作业混部管理平台,实现智能资源管理和作业调度
摘要:本文结合华为CCE团队在混合部署方面的研究和实战,介绍了混合部署的背景.概念.混部技术的设计方案和实际落地情况,以及对未来的计划和展望. 现代互联网数据中心的规模随着应用服务需求的快速增长而不断 ...
- STM32 标准库
CMSIS 标准及库层次关系 因为基于Cortex 系列芯片采用的内核都是相同的,区别主要为核外的片上外设的差异,这些差异却导致软件在同内核,不同外设的芯片上移植困难.为了解决不同的芯片厂商生产的Co ...
- 我的python学习记04
列表,元组,字典的使用一.列表列表的格式:list[元素1,元素2,--]列表也是一个有序集合,下标索引从0开始与字符串类似1.在列表中添加数据append:list.append(添加元素) (在最 ...
- java中异常(Exception)的定义,意义和用法。举例
1.异常(Exception)的定义,意义和用法 我们先给出一个例子,看看异常有什么用? 例:1.1- public class Test { public static void main(S ...
- java中时间的规范是按美国,SimpleDateFormat怎么处理
题目3.2: 如果时间的规范是按美国,怎么处理? import java.text.ParseException;import java.text.SimpleDateFormat;import ja ...
- 利用es6解构赋值快速提取JSON数据;
直接上代码 { let JSONData = { title:'abc', test:[ { nums:5, name:'jobs' }, { nums:11, name:'bill' } ] } l ...
- 引入css的方式
---恢复内容开始--- 引入css的样式及link和@import的区别 有3种引入方式 1.内部样式(写在标签内) 2.内联样式 3.外部样式(link @import) 区别: 1.本质区别:l ...
- FastAPI(六十八)实战开发《在线课程学习系统》接口开发--用户 个人信息接口开发
在之前的文章:FastAPI(六十七)实战开发<在线课程学习系统>接口开发--用户登陆接口开发,今天实战:用户 个人信息接口开发. 在开发个人信息接口的时候,我们要注意了,因为我们不一样的 ...
- caioj 1002: [视频]实数运算2[水题]
题意:输入三个数,计算并输出它们的平均值以及三个数的乘积,结果保留2位小数. 题解:简单题不写题解了-- 代码: #include <cstdio> double a, b, c; int ...
- Java报错:Failed to execute goal org.eclipse.jetty:jetty-maven-plugin:9.4.26.v20200117:run (default-cli) on project ssm-mybatis-plus: Failure
修改一下端口就好了,不要用80端口. <plugin> <groupId>org.eclipse.jetty</groupId> <!--嵌入式Jetty的M ...