Hadoop YARN与MapReduce
YARN架构
ResourceManager
负责整体资源的管理 (Scheduler and ApplicationsManager)
NodeManager
向ResourceManager通过心跳汇报自己的资源情况
container容器
资源申请的基本单位(包含指定cpu, memory, disk, network资源)
NodeManager内有线程监控container资源情况,超额,NM 直接kill掉
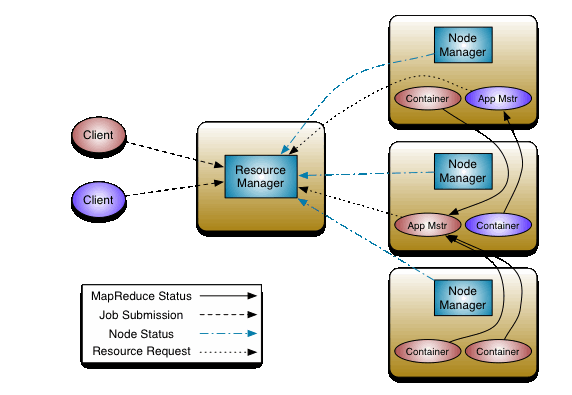
计算向数据移动实现流程:
1,MR-Client将计算的切片清单/配置/jar/上传到HDFS存储, 通知ResourceManager
2,RM收到请求选择一台不忙的节点通知NM启动一个Container,在里面反射产生一个AppMaster
3,启动AppMaster后从hdfs下载切片清单,向RM申请计算所需的资源
4,RM根据自己掌握的资源情况得到一个确定清单,通知NM来启动container
5,container启动后会反向注册到已经启动的AppMaster进程(可供AppMaster使用的资源需要注册)
6,AppMaster(起到任务调度角色)最终将任务Task发送给container(消息)
7,container收到消息,到hdfs下载client上传的jar文件到本地,反射相应的Task类为对象,调用方法执行,其结果就是我们的业务逻辑代码的执行
8,计算框架都有Task失败重试的机制(有最大失败次数限制)
注:1,每个client任务唯一对应一个AppMaster即每个任务有独立任务调度器,互相不影响(减轻单点压力,单点故障问题)
2,如果nodeManager挂掉会导致分布在该节点的任务执行失败,RM心跳会监控到任务失败,重新在其它节点分配资源重新执行
MapReduce (数据批量计算的一种方式)
计算模型:
map阶段
单条记录加工处理,一条数据记录经过map方法映射成key,value,partition 相同的key为一组
reduc阶段
按组,多条记录统计处理,一组数据调用一次reduce方法,在方法内进行迭代计算
注:map和reduce是一种阻塞关系
架构图
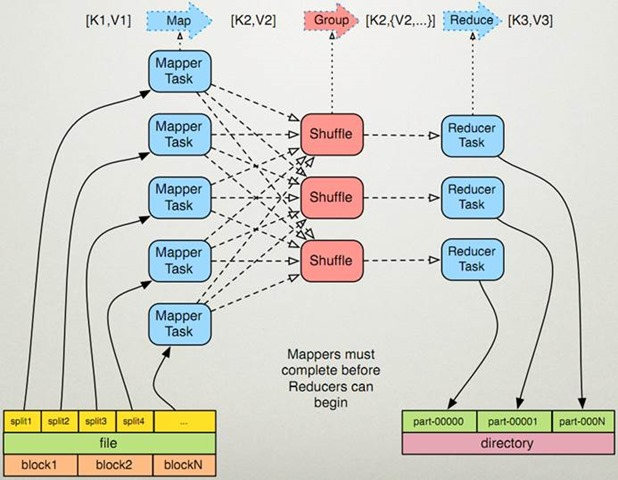
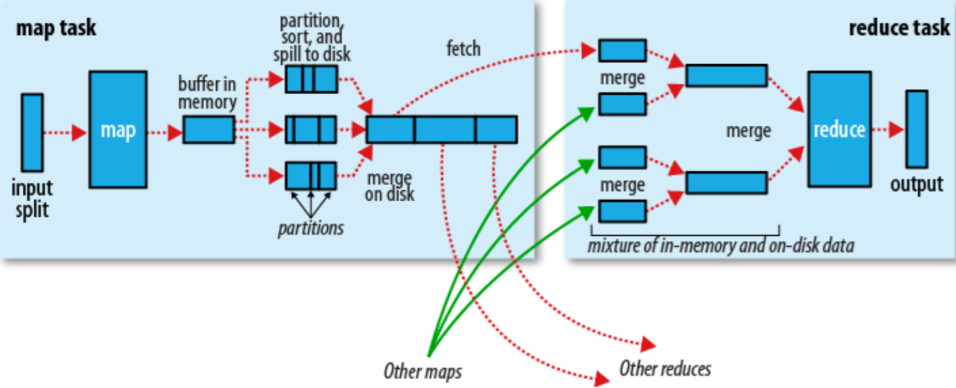
实现流程:
1,split对应map处理读取数据源,控制并行度,split是逻辑的,解耦与原数据源的关联
2,map的输出映射成K,V,K,V会参与分区计算,根据key算出Partition -> K,V,P
3,一个Map对应一个maptask进程,map输出会写入文件,写入时中间会有100M的buffer缓存,缓存区满后,先按partion排序,然后再对key进行排序,二次排序处理后写入临时文件
4,map输出的多个临时文件最终合并为一个大文件
注:进行partition排序和key排序为了同分区的同一组key会排在一起,减少reduce端的IO复杂度
数据读取
通过InputFormat决定读取的数据的类型,然后拆分成一个个InputSplit,每个InputSplit对应一个Map处理,InputSplit是逻辑分片,没有存储数据,提供了数据分片方法(getLength,getLocations)。RecordReader读取InputSplit的内容,拆分成key,value给Map处理
实现类:
TextInputFormat: 输入文件中的每一行就是一个记录,Key是这一行的byte offset,而value是这一行的内容
KeyValueTextInputFormat: 输入文件中每一行就是一个记录,第一个分隔符字符切分每行。在分隔符字符之前的内容为Key,在之后的为Value。
分隔符变量通过key.value.separator.in.input.line变量设置,默认为(\t)字符
map shufer处理
1,当Map程序开始产生结果时,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作
每个Map任务都有一个循环内存缓冲区(默认100MB),当缓存的内容达到80%时,后台线程开始将内容写到临时文件,此时Map任务可以继续输出,如果缓冲区满了,Map任务则需要等待
2,在写入文件之前,先将数据按照Reduce进行分区。对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner
Combine:对map数据处理进行聚合减少结果数据量(异写文件1次,和并小文件1次)减少shuffer IO加快reduce处理
注:每次map数据达到缓冲区的阀值时,都会将结果输出到一个文件,在Map结束时,可能会产生大量的文件,因此在Map完成前,会将这些文件进行合并和排序。
如果文件的数量超过3个,则合并后会再次运行Combiner(1、2个文件就没有必要)如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据
3,一旦Map完成,则通知任务管理器,此时Reduce就可以开始拉取对应的结果集数据进行迭代计算,将结果写入文件。
注:reduce数量默认为1 ,如果需要多个需要重写GroupCombaner。当文件数量为2(小于合并参数)则不能保证相同的key只出现一条
数据倾斜问题:
(1)重写分区器
(2)key的拼接 k0_1 k0_2 ,combiner使用。
相关参数
io.sort.mb//使用缓冲区的大小,默认100M
io.sort.spill.percent//缓冲区写文件阈值,默认0.8
min.num.spills.for.combine//combine合并文件最小数
mapred.reduce.copy.backoff//这段时间内reducer失败则会反复尝试,默认300s
参考
http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html
http://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
Hadoop YARN与MapReduce的更多相关文章
- MapReduce扩展:应用程序如何运行于Hadoop Yarn之上
1. 背景 “应用程序运行于Hadoop Yarn之上”的需求来源于微博运维数据平台中的调度系统,即调度系统中的任务需要运行于Hadoop Yarn之上.这里的应用程序可以简单理解为一个普通的进程 ...
- hadoop YARN配置参数剖析—MapReduce相关参数
MapReduce相关配置参数分为两部分,分别是JobHistory Server和应用程序参数,Job History可运行在一个独立节点上,而应用程序参数则可存放在mapred-site.xml中 ...
- 3.Hadoop测试Yarn和MapReduce
Hadoop测试Yarn和MapReduce 1.配置Yarn (1)配置ResourceManager 生产环境中,一般是重开一台机器作为ResourceManager,这里我们以Master机器代 ...
- Hadoop YARN配置参数剖析(3)—MapReduce相关参数
MapReduce相关配置参数分为两部分,分别是JobHistory Server和应用程序参数,Job History可运行在一个独立节点上,而应用程序参数则可存放在mapred-site.xml中 ...
- Hadoop YARN 100-1知识点
0 YARN中实体 资源管理者(resource manager, RM) 长时间运行的守护进程,负责管理集群上资源的使用 节点管理者(node manager, NM) 长时间运行的守护进程,在集群 ...
- Wordcount on YARN 一个MapReduce示例
Hadoop YARN版本:2.2.0 关于hadoop yarn的环境搭建可以参考这篇博文:Hadoop 2.0安装以及不停集群加datanode hadoop hdfs yarn伪分布式运行,有如 ...
- 怎样通过Java程序提交yarn的mapreduce计算任务
因为项目需求,须要通过Java程序提交Yarn的MapReduce的计算任务.与一般的通过Jar包提交MapReduce任务不同,通过程序提交MapReduce任务须要有点小变动.详见下面代码. 下面 ...
- Hadoop YARN配置参数剖析—RM与NM相关参数
注意,配置这些参数前,应充分理解这几个参数的含义,以防止误配给集群带来的隐患.另外,这些参数均需要在yarn-site.xml中配置. 1. ResourceManager相关配置参数 (1) ...
- Hadoop Yarn内存资源隔离实现原理——基于线程监控的内存隔离方案
注:本文以hadoop-2.5.0-cdh5.3.2为例进行说明. Hadoop Yarn的资源隔离是指为运行着不同任务的“Container”提供可独立使用的计算资源,以避免它们之间相互干扰.目 ...
- hadoop错误org.apache.hadoop.yarn.exceptions.YarnException Unauthorized request to start container
错误: 14/04/29 02:45:07 INFO mapreduce.Job: Job job_1398704073313_0021 failed with state FAILED due to ...
随机推荐
- java时区相关问题(被恶心到了)
在项目开发中,遇到了mysql5.7数据库相关的时区问题.整理如下: 问题一:在使用swagger测试接口时,数据库记录的时间和输入的不一致.如下图: swagger中输入的是:"recei ...
- 我曾经用“UC震惊部”震碎了很多人的三观
Hi,欢迎大家在有空的时候做客[江涛学编程],这里是2023年的第9篇原创文章,今天写的这篇是当事人对昨天上热搜的统一回复. 我没有曾经跨过山河大海,我也没有曾经穿越人山人海,但我曾经用"U ...
- pytest框架的简介
概念:是一款基于python语言的单元测试框架 用途:用于发现测试用例.执行测试用例.判断测试结果.生成测试报告的一款框架 测试用例的规则: 测试文件必须与test开头,或_test结尾 类文件必须T ...
- ZROI3
题解 ZROI3 T1 与<滑动窗口>类似,用单调队列维护 #include <queue> #include <cstdio> #include <cstr ...
- day07-Spring管理Bean-IOC-05
Spring管理Bean-IOC-05 3.基于注解配置bean 3.3自动装配 基本说明: 基于注解配置bean,也可以实现自动装配,使用的注解是:@AutoWired或者@Resource @Au ...
- 基础文之-----typeof 和 instanceof
为了巩固基础,我会通过实例来详细说明,让我们一起搞懂 typeof 和 instanceof. <!DOCTYPE html> <html lang="en"&g ...
- Entrypoint undefined = index.html html-webpack-plugin 错误ERROR in Error: Child compilation failed: Module build failed (from ./node_modules/html-webpack-plu SyntaxError: Unexpected token )
Entrypoint undefined = index.html html-webpack-plugin 错误 ERROR in Error: Child compilation failed: M ...
- 反射_Class对象功能_获取Constructor-反射_Class对象功能_获取Method
反射_Class对象功能_获取Constructor Constructor<?>[] getConstructors() Constructor<T> getConstruc ...
- Unity3D——鼠标双击
Unity之鼠标双击 小黑终于又回到公司了! 能在公司安生的待段时间了,今天更新一篇吧! 懒惰的小黑给大家分享个好东西吧,解决双击之痛! 前言 小黑相信有许多人和我一样.万年不会碰到一个需求:双击!可 ...
- 【学习笔记】QT从入门到实战完整版(基础控件)(4)
添加资源 将存有资源文件的文件夹放到工程目录中,如文件夹名称为 "Image",里面有 Luffy.png 文件. 在 Qt Creator 中右击工程选择[添加新文件]. 在弹出 ...