机器学习-K近邻(KNN)算法详解
一、KNN算法描述
KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表。KNN算法属于有监督学习方式的分类算法,所谓K近邻算法,就是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(就是上面提到的K个邻居),如果这K个实例的多数属于某个类,就将该输入实例分类到这个类中,如下图所示。
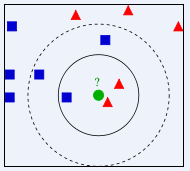
上图中有两种不同类别的样本数据,分别用蓝色正方形和红色三角形表示,最中间绿色的圆表示的数据则是待分类的数据。我们现在要解决的问题是:不知道中间的圆是属于哪一类(正方形类还是三角形类)?我们下面就来给圆分类。
从图中还能看出:如果K=3,圆的最近的3个邻居是2个三角形和1个正方形,少数从属于多数,基于统计的方法,判定圆标示的这个待分类数据属于三角形一类。但是如果K=5,圆的最近的5个邻居是2个三角形和3个正方形,还是少数从属于多数,判定圆标示的这个待分类数据属于正方形这一类。由此我们可以看到,当无法判定当前待分类数据从属于已知分类中的哪一类时,可以看它所处的位置特征,衡量它周围邻居的权重,而把它归为权重更大的一类,这就是K近邻算法分类的核心思想。
二、代码实现
算法步骤:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增依次排序;
- 选取与当前点距离最小的K个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类
"""
kNN: k Nearest Neighbors
Input: inX: vector to compare to existing dataset (1xN)
dataSet: size m data set of known vectors (NxM)
labels: data set labels (1xM vector)
k: number of neighbors to use for comparison (should be an odd number)
Output: the most popular class label
"""
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet #将inX重复成dataSetSize行1列,tile(A,n),功能是将数组A重复n次,构成一个新的数组
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #sum(axis=1)就是将矩阵的每一行向量相加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() #argsort()得到的是排序后数据原来位置的下标
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]#确定前k个距离最小元素所在的主要分类labels
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#计算各个元素标签的出现次数(频率),当voteIlabel在classCount中时,classCount.get()返回1,否则返回0
#operator.itemgetter(1)表示按照第二个元素的次序对元组进行排序,reverse=True表示为逆序排序,即从大到小排序
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] #最后返回发生频率最高的元素标签 classify0()函数有4个输入参数:用于分类的输入向量是inX,输入的训练样本集为dataSet,标签向量为labels,最后的参数k表示用于选择最近邻居的数目,其中标签向量的元素数目和矩阵dataSet的行数相同。除了K值之外,kNN算法的另一个核心参数是距离函数的选择。上述代码使用的是欧式距离,在日常生活中我们所说的距离往往是欧氏距离,也即平面上两点相连后线段的长度。欧氏距离的定义如下:

除此之外,在机器学习中常见的距离定义有以下几种:
汉明距离:两个字符串对应位置不一样的个数。汉明距离是以理查德·卫斯里·汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数;
马氏距离:表示数据的协方差距离。计算两个样本集相似度的距离;
余弦距离:两个向量的夹角作为一种判别距离的度量;
曼哈顿距离:两点投影到各轴上的距离总和;
切比雪夫距离:两点投影到各轴上距离的最大值;
标准化欧氏距离: 欧氏距离里每一项除以标准差。
还有一种距离叫闵可夫斯基距离,如下:

当q为1时,即为曼哈顿距离。当q为2时,即为欧氏距离。
在这里介绍距离的目的一个是为了让大家使用k近邻算法时,如果发现效果不太好时,可以通过使用不同的距离定义来尝试改进算法的性能。
KNN算法的优缺点
优点:
理解简单,数学知识基本为
0;既能用于分来,又能用于回归;
支持多分类。
kNN算法可以用于回归,回归的思路是将离待测点最近的k个点的平均值作为待测点的回归预测结果。
kNN算法在测试阶段是看离待测点最近的k个点的类别比分,所以不管训练数据中有多少种类别,都可以通过类别比分来确定待测点类别。
注:当然会有类别比分打平的情况,这种情况下可以看待测点离哪个类别最近,选最近的类别作为待测点的预测类别。
缺点:
当然kNN算法的缺点也很明显,就是当训练集数据量比较大时,预测过程的效率很低。这是因为kNN算法在预测过程中需要计算待测点与训练集中所有点的距离并排序。可想而知,当数据量比较大的时候,效率会奇低。对于时间敏感的业务不太适合。
三、使用sklearn进行KNN分类与回归算法
1.使用sklearn中的kNN算法进行分类
sklearn中KNeighborsClassifier的参数
比较常用的参数有以下几个:
n_neighbors,即K近邻算法中的K值,为一整数,默认为5;
metric,距离函数。参数可以为字符串(预设好的距离函数)或者是callable(可调用对象,大家不明白的可以理解为函数即可)。默认值为闵可夫斯基距离;
p,当metric为闵可夫斯基距离公式时,上文中的q值,默认为2。
代码实现:
from sklearn.neighbors import KNeighborsClassifier
def classification(train_feature, train_label, test_feature):
'''
使用KNeighborsClassifier对test_feature进行分类
:param train_feature: 训练集数据
:param train_label: 训练集标签
:param test_feature: 测试集数据
:return: 测试集预测结果
'''
clf = KNeighborsClassifier()
clf.fit(train_feature, train_label)
predict_result = clf.predict(test_feature)
return predict_result2.使用sklearn中的kNN算法进行回归
当我们需要使用kNN算法进行回归器时,只需要把KNeighborsClassifier换成KNeighborsRegressor即可。KNeighborsRegressor和KNeighborsClassifier的参数是完全一样的,所以在优化模型时可以参考上述的内容。
代码实现:
from sklearn.neighbors import KNeighborsRegressor
def regression(train_feature, train_label, test_feature):
'''
使用KNeighborsRegressor对test_feature进行分类
:param train_feature: 训练集数据
:param train_label: 训练集标签
:param test_feature: 测试集数据
:return: 测试集预测结果
'''
clf = KNeighborsRegressor()
clf.fit(train_feature, train_label)
predict_result = clf.predict(test_feature)
return predict_result上述为KNN算法的简述
机器学习-K近邻(KNN)算法详解的更多相关文章
- 算法代码[置顶] 机器学习实战之KNN算法详解
改章节笔者在深圳喝咖啡的时候突然想到的...之前就有想写几篇关于算法代码的文章,所以回家到以后就奋笔疾书的写出来发表了 前一段时间介绍了Kmeans聚类,而KNN这个算法刚好是聚类以后经常使用的匹配技 ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习-KNN算法详解与实战
最邻近规则分类(K-Nearest Neighbor)KNN算法 1.综述 1.1 Cover和Hart在1968年提出了最初的邻近算法 1.2 分类(classification)算法 1.3 输入 ...
- knn算法详解
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习_K近邻Python代码详解
k近邻优点:精度高.对异常值不敏感.无数据输入假定:k近邻缺点:计算复杂度高.空间复杂度高 import numpy as npimport operatorfrom os import listdi ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- 机器学习之路--KNN算法
机器学习实战之kNN算法 机器学习实战这本书是基于python的,如果我们想要完成python开发,那么python的开发环境必不可少: (1)python3.52,64位,这是我用的python ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
随机推荐
- Java函数的学习
函数的定义 - 定义的位置:定义在类的内部 - 组成部分: 函数修饰符 类型 函数名(形式参数){ 局部变量: 注释: 函数体: } 函数的调用 - 调用函数时使用 : `函数名():` - 函数在执 ...
- Oracle 错误表
ORA-00001: 违反唯一约束条件 (.) ORA-00017: 请求会话以设置跟踪事件 ORA-00018: 超出最大会话数 ORA-00019: 超出最大会话许可数 ORA-00020: 超出 ...
- jmeter元件分析
jmeter元件分析 一.脚本通用性 1.性能测试脚本改动一下,加入断言等元件,就可以作为接口测试脚本来使用 2.但是接口测试的脚本不可以作为性能测试脚本来使用 3.原因:因为性能测试考虑更多的性能, ...
- RAID5加热备盘
RAID 5加热备盘 RAID 10磁盘阵列中最多允许50%的硬盘设备发生故障,但是存在这样一种极端情况,即同一RAID 1磁盘阵列中的硬盘设备若全部损坏,也会导致数据丢失.换句话说,在RAID 10 ...
- 【链表】【leetCode高频】: 19. 删除链表的倒数第 N 个结点
1.题目描述 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点. 2.算法分析 知识补充: . 分析: 题目要求是删除链表中倒数第N个结点.可以使用两个指针slow,fast. 重点是 ...
- 用python实现matlib的 生成高斯模糊核
最近在做一个关于模糊图片恢复的数学建模,遇到了一个大问题,特记录一下. 在matlib中有 PSF = fspecial('motion', LEN, THETA); 来生成模糊核函数,但在pyt ...
- 手机USB共享网络是个啥
智能手机一般都提供了USB共享网络的功能,将手机通过USB线与电脑连接,手机端开启『USB共享网络』,电脑就能通过手机上网. 手机端开启『USB共享网络』: 电脑端出现新的网络连接: 通过设备管理器看 ...
- nacos 详细介绍(二)
五.nacos的namespace和group namespace:相当于环境,开发环境 测试环境 生产环境 ,每个空间里面的配置是独立的默认的namespace是public, namespace可 ...
- 李阳:京东零售OLAP平台建设和场景实践
导读: 今天和大家分享京东零售OLAP平台的建设和场景的实践,主要包括四大部分: 管控面建设 优化技巧 典型业务 大促备战 -- 01 管控面建设 1. 管控面介绍 管控面可以提供高可靠高效可持续运维 ...
- 解放双手!推荐一款 GitHub 星标 8.2k+的命令行软件管理器,非常酷炫!
小二是公司新来的实习生,之前面试的过程中对答如流,所以我非常看好他.第一天,我给他了一台新电脑,要他先在本地搭建个 Java 开发环境. 二话不说,他就开始马不停蹄地行动了.真没想到,他竟然是通过命令 ...