论文笔记 - Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity

prompt 的影响因素
Motivation
- Prompt 中 Example 的排列顺序对模型性能有较大影响(即使已经校准参见好的情况下,选取不同的排列顺序依然会有很大的方差):
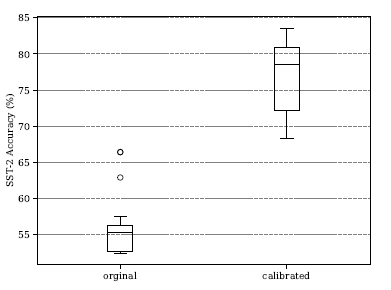
- 校准可以大幅度提高准确率,但是不同的排列顺序方差依然很大
Analysis
- 提出探测集(probing set),流程如下:
- 训练集 $S={(x_i, y_i)}$,模板转换函数(将一组数据转换为自然语言) $t_i=\tau (x_i,y_i)=input:x_i,type:y_y$,因此自然语言数据集 $S'=\{t_i\}$;
- 排列方程集合 $\mathfrak{F}=\{f_m\},m=1\rightarrow n!$,$f_m(S')=c_m$ 为一种训练数据的组合顺序($m=1\rightarrow n!$);
- 对于每一种排列组合$c_m$,使用语言模型进行去预测后续的句子(注意这里没有加上测试集的问题,纯粹对训练集进行组合),得到模型生成的新的 example:$g_m\propto P(...|c_m;\theta)$,$\theta$为语言模型的参数,对生成序列解析得到模型生成的数据集:$D=\{\tau ^{-1}(g_m)\},m=1\rightarrow n!$。
- 针对探测集提出两种评估 prompt 的指标:
Global Entropy
- 对探测集合中探测数据$(x'_i, y'_i)\in D$(生成的 label 不需要,不具有参考意义),选择一种排列组合(上下文)$c_m$进行推理得到$\hat{y_{i,m}}$,即:
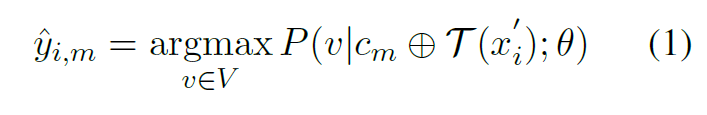
- 对探测集中的每个探测数据进行预测,求得每个预测的种类占探测集的比例:
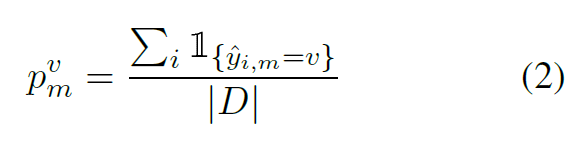
- 最后求熵(熵反应了预测各个种类的均匀程度,预测的正确与否并不重要,假如熵非常小,说明预测的结果 bias 非常大):
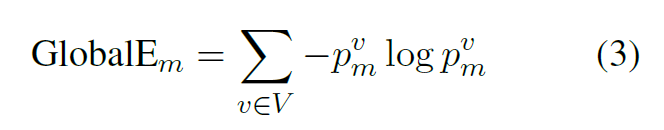
Local Entropy
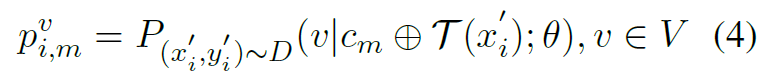
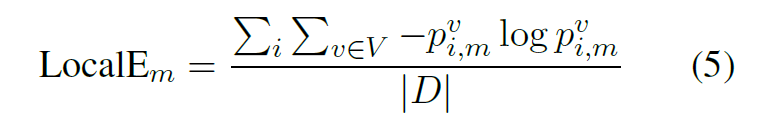
- 与全局熵类似,只不过先求熵再求和。
为什么上面的方法有用呢?
- 个人猜想:你能得到的训练集是非常有限的,假设改变 example 的排列顺序会使 output distribution 发生改变。假如你只有 4 个 example,那么你最多能模拟出来 24 种不同的 distribution(很多模拟不出来但是没有办法,受数据制约),也就是说你得到的包含 24 个数据的探测集其实就是尽最大能力准备出来的多样数据集。如果在这些探测数据上,某个排序$c_m$预测的结果集合很均匀(各种类别数量差不多),那么说明这种排序 rebust 比较强(这种排序没有倾向性,导致生成的问题都是中性的,生成什么label的可能性都一样)。
论文笔记 - Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
随机推荐
- python自学笔记10:while循环和for循环
条件控制和循环控制是两种典型的流程控制方法,前面我们写了 if 条件控制,这节讲 for 循环和 while 循环. 循环是另一种控制流程的方式,一个循环体中的代码在程序中只需要编写一次,但可能会连续 ...
- 配置IConfiguration
前言 配置是我们必不可少的功能,我们在开发中,经常会遇到需要获取配置信息的需求,那么如何才能优雅的获取配置信息? 我们希望新的配置: 支持强类型 配置变更后通知 学习难度低 快速入门 根据使用场景我们 ...
- C#使用BouncyCastle生成PKCS#12数字证书
背景 生成数字证书用于PDF文档数字签名 数字证书需要考虑环境兼容性,如linux.windows 网上资料不全或版本多样 本文章主要介绍了在C#中使用BouncyCastle生成PKCS#12个人信 ...
- 在 C# CLR 中学习 C++ 之了解 namespace
一:背景 相信大家在分析 dump 时,经常会看到 WKS 和 SRV 这样的字眼,如下代码所示: 00007ffa`778a07b8 coreclr!WKS::gc_heap::segment_st ...
- NFS生产环境部署调优
1.NFS简介 NFS(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间共享资源.在NFS的应用中,本地NFS的客户端应用可以透 ...
- redis的简单学习记录
安装 1 brew install redis 启动redis服务 1 redis-server & 启动命令 1 redis-cli -h 127.0.0.1 -p 6379 利用gored ...
- 华南理工大学 Python第6章课后测验-2
1.(单选)以下关于语句 a = [1,2,3,(4,5)]的说法中,正确的个数有( )个.(1)a是元组类型 (2)a是列表类型 (3)a有5个元素 (4)a有4个元素(5)a[1] ...
- 【loj2538】 【PKUWC 2018】Slay the Spire dp
我们不难发现,假设抽了x张攻击牌,y张强化牌,那么肯定是打出尽可能多张的强化牌后,再开始出攻击牌(当然最少要一张攻击牌) 我们设G(i,j)表示:所有(抽到的攻击牌牌数为i,打出的攻击牌牌数为j)的方 ...
- 使用Pipeline抽象业务生命周期流程
上篇关于流程引擎的文章还是快两年以前的<微服务业务生命周期流程管控引擎>,这中间各种低代码平台层出不穷,虽然有些仅仅是OA+表单的再度包装,但有些的确是在逻辑和操作单元层面进行了真正的高度 ...
- Latex中也能展示动态图?
技术背景 在学术领域,很多文档是用Latex做的,甚至有很多人用Latex Beamer来做PPT演示文稿.虽然在易用性和美观等角度来说,Latex Beamer很大程度上不如PowerPoint,但 ...