论文笔记 - Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity

prompt 的影响因素
Motivation
- Prompt 中 Example 的排列顺序对模型性能有较大影响(即使已经校准参见好的情况下,选取不同的排列顺序依然会有很大的方差):
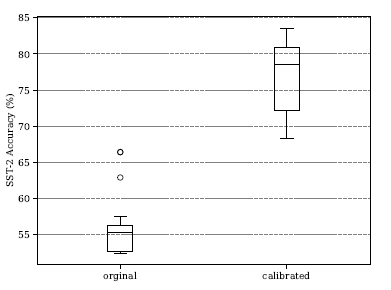
- 校准可以大幅度提高准确率,但是不同的排列顺序方差依然很大
Analysis
- 提出探测集(probing set),流程如下:
- 训练集 $S={(x_i, y_i)}$,模板转换函数(将一组数据转换为自然语言) $t_i=\tau (x_i,y_i)=input:x_i,type:y_y$,因此自然语言数据集 $S'=\{t_i\}$;
- 排列方程集合 $\mathfrak{F}=\{f_m\},m=1\rightarrow n!$,$f_m(S')=c_m$ 为一种训练数据的组合顺序($m=1\rightarrow n!$);
- 对于每一种排列组合$c_m$,使用语言模型进行去预测后续的句子(注意这里没有加上测试集的问题,纯粹对训练集进行组合),得到模型生成的新的 example:$g_m\propto P(...|c_m;\theta)$,$\theta$为语言模型的参数,对生成序列解析得到模型生成的数据集:$D=\{\tau ^{-1}(g_m)\},m=1\rightarrow n!$。
- 针对探测集提出两种评估 prompt 的指标:
Global Entropy
- 对探测集合中探测数据$(x'_i, y'_i)\in D$(生成的 label 不需要,不具有参考意义),选择一种排列组合(上下文)$c_m$进行推理得到$\hat{y_{i,m}}$,即:
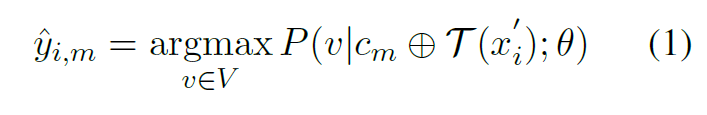
- 对探测集中的每个探测数据进行预测,求得每个预测的种类占探测集的比例:
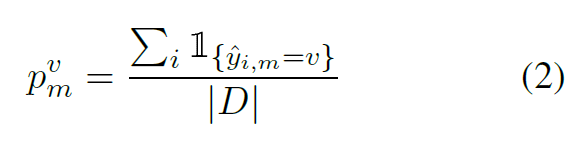
- 最后求熵(熵反应了预测各个种类的均匀程度,预测的正确与否并不重要,假如熵非常小,说明预测的结果 bias 非常大):
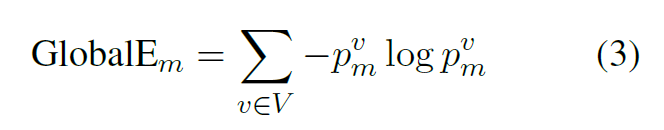
Local Entropy
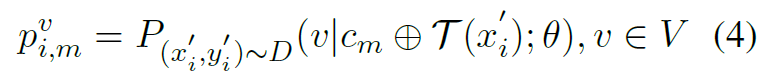
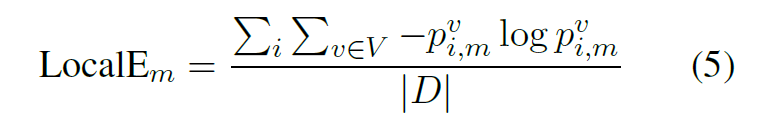
- 与全局熵类似,只不过先求熵再求和。
为什么上面的方法有用呢?
- 个人猜想:你能得到的训练集是非常有限的,假设改变 example 的排列顺序会使 output distribution 发生改变。假如你只有 4 个 example,那么你最多能模拟出来 24 种不同的 distribution(很多模拟不出来但是没有办法,受数据制约),也就是说你得到的包含 24 个数据的探测集其实就是尽最大能力准备出来的多样数据集。如果在这些探测数据上,某个排序$c_m$预测的结果集合很均匀(各种类别数量差不多),那么说明这种排序 rebust 比较强(这种排序没有倾向性,导致生成的问题都是中性的,生成什么label的可能性都一样)。
论文笔记 - Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
随机推荐
- 这次我设计了一款TPS百万级别的分布式、高性能、可扩展的RPC框架
作者:冰河 博客地址:https://binghe001.github.io 大家好,我是冰河~~ 没错,这次冰河又要搞事情了,这次准备下手的是RPC框架项目.为什么要对RPC框架项目下手呢,因为在如 ...
- NOI 2019 省选模拟赛 T1【JZOJ6082】 染色问题(color) (多项式,数论优化)
题面 一根长为 n 的无色纸条,每个位置依次编号为 1,2,3,-,n ,m 次操作,第 i 次操作把纸条的一段区间 [l,r] (l <= r , l,r ∈ {1,2,3,-,n})涂成颜色 ...
- BNC Part-of-speech codes
Extracted from the BNC Manual AJ0 adjective (general or positive) e.g. good, old AJC comparative adj ...
- std::atomic和std::mutex区别
std::atomic介绍 模板类std::atomic是C++11提供的原子操作类型,头文件 #include<atomic>.在多线程调用下,利用std::atomic可实 ...
- Mac_mysql_密码重置
1 通过Mac 的设置 stop mysql 2 跳过权限认证 // 进入数据库指令文件 cd /usr/local/mysql/bin // 跳过权限认证 sudo ./mysqld_safe -- ...
- 对表白墙wxml文件解释
一.index.wxml 1.代码 1 <view class="Beijingse" style="height: 100%;"> 2 <v ...
- 如何在JavaScript中使用高阶函数
将另一个函数作为参数的函数,或者定义一个函数作为返回值的函数,被称为高阶函数. JavaScript可以接受高阶函数.这种处理高阶函数的能力以及其他特点,使JavaScript成为非常适合函数式编程的 ...
- Prometheus自身的监控告警规则
1.先在 Prometheus 主程序目录下创建rules目录,然后在该目录下创建 prometheus-test.yml文件,内容如下: 内容很多,可以根据实际情况进行调整. 规则参考网址:http ...
- varchar与varchar2的区别
1. varchar2所有字符都占两字节处理(一般情况下),varchar只对汉字和全角等字符占两字节,数字,英文字符等都是一个字节. 2. varchar2把空串等同于null处理,而varchar ...
- 线上服务宕机,码农试用期被毕业,原因竟是给MySQL加个字段
1. 问题:怎么给线上表加字段? 工作中最常遇到的问题,怎么给线上频繁使用的大表添加字段? 比如:给下面的用户表(user)添加年龄(age)字段. CREATE TABLE `user` ( `id ...