强化学习-学习笔记12 | Dueling Network
这是价值学习高级技巧第三篇,前两篇主要是针对 TD 算法的改进,而Dueling Network 对 DQN 的结构进行改进,能够大幅度改进DQN的效果。
Dueling Network 的应用范围不限于 DQN,本文只介绍其在 DQN上的应用。
12. Dueling Network
12.1 优势函数
Advantage Function.
回顾一些基础概念:
折扣回报:
\(U_t = R_t + \gamma \cdot R_{t+1} + \gamma^2R+...\)
动作价值函数:
\(Q_\pi(s_t,a_t)=\mathbb{E}[U_t|S_t=s_t,A_t=a_t]\)
消去了未来的状态 和 动作,只依赖于当前动作和状态,以及策略函数 \(\pi\)。
状态价值函数:
\(V_\pi(s_t)=\mathbb{E}[Q_\pi(s_t,A)]\)
只跟策略函数 \(\pi\) 和当前状态 \(s_t\) 有关。
最优动作价值函数
\(Q^*(s,a)=\mathop{max}\limits_{\pi}Q_\pi(s,a)\)
只依赖于 s,a,不依赖策略函数。
最优状态价值函数
\(V^*(s)=\mathop{max}\limits_{a}V_\pi(S)\)
只依赖 S。
下面就是这次的主角之一:
Optimal Advantage function 优势函数:
\(A^*(s,a)=Q^*(s,a)-V^*(s)\)
V* 作为 baseline ,优势函数的意思是动作 a 相对 V* 的优势,A*越好,那么优势就越大。
下面介绍一个优势函数有关的定理:
定理一:\(V^*(s)=\mathop{max}\limits_a Q^*(s,a)\)
这一点从上面的回顾不难看出,求得最优的路径不同,但是相等。
上面提到了优势函数的定义:\(A^*(s,a)=Q^*(s,a)-V^*(s)\)
同时对左右求最大值:\(\mathop{max}\limits_{a}A^*(s,a)=\mathop{max} \limits_{a}Q^*(s,a)-V^*(s)\),而等式右侧正是上面定理,所以右侧==0;因此优势函数关于a的最大值=0,即:
\(\mathop{max}\limits_{a}A^*(s,a)=0\)
我们把这个 0 值式子加到定义上,进行简单变形:
定理二:\(Q^*(s,a)=V^*(s)+A^*(s,a)-\mathop{max}\limits_{a}A^*(s,a)\)
Dueling Network 就是由定理二得到的。
12.2 Dueling Network 原理
此前 DQN 用\(Q(s,a;w)\) 来近似 \(D^*(s,a)\) ,结构如下:
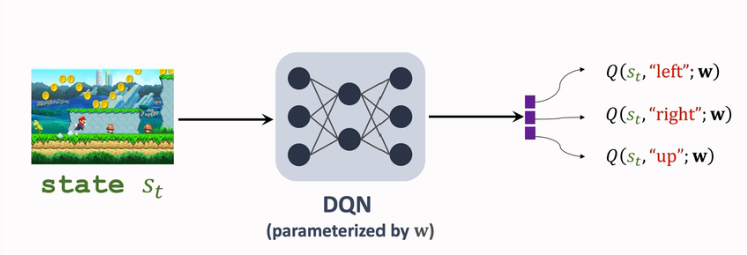
而 Dueling Network 对 DQN 的结构改进原理是:
我们对于DQN的改进思路就是基于上面的定理2:\(Q^*(s,a)=V^*(s)+A^*(s,a)-\mathop{max}\limits_{a}A^*(s,a)\)
- 分别用神经网络 V 和 A 近似 V-star 和 A-star
- 即:\(Q(s,a;w^A,w^V)=V(s;w^V)+A(s,a;w^A)-\mathop{max}\limits_{a}A(s,a;w^A)\)
- 这样也完成了对于 Q-star 的近似,与 DQN 的功能相同。
首先需要用一个神经网络 \(V(s;w^V)\) 来近似 \(V^*(s)\):
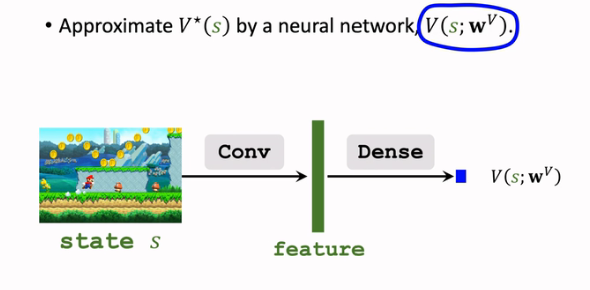
注意这里的输出是一个实数,是对状态的打分,而非向量;
- 用另一个神经网络\(A(s,a;w^A)\) 对\(A^*(s,a)\) 进行近似:
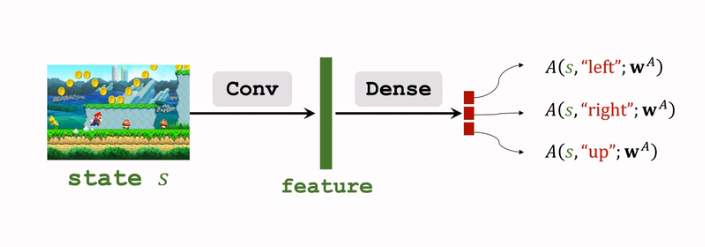
这个网络和上面的网络 \(V\) 结构有一定的相像,可以共享卷积层的参数;
后续为了方便,令 \(w=(w^A,w^V)\),即:
\]
现在 左侧 与 DQN 的表示就一致了。下面搭建Dueling Network,就是上面 V 和 A 的拼接与计算:
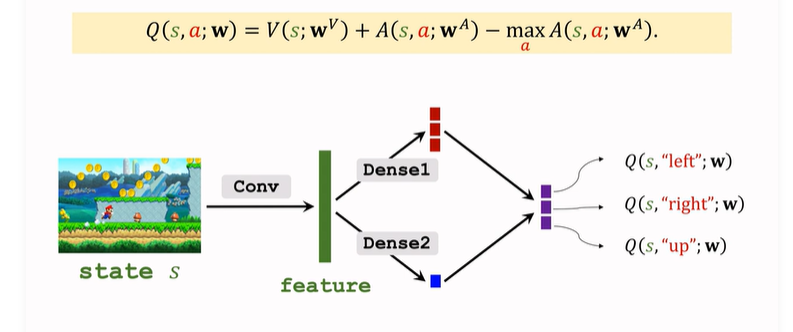
- 输入 状态 s,V 和 A 共享一些 卷积层,得到特征向量;
- 分别通过不同的全连接层,A输出向量,V输出实数;
- 通过上面的式子运算输出最终结果,是对所有动作的打分;
可见Dueling Network 的输入 和 输出 和 DQN 完全一样,功能也完全一样;但是内部的结构不同,Dueling Network 的结构更好,所以表现要比 DQN好;
注意,Dueling Network 和 DQN 都是对 最优动作价值函数 的近似。
12.3 训练 Dueling Network
接下来训练参数 \(w=(w^A,w^v)\),采用与 DQN 相同的思路,也就是采用 TD算法训练 Dueling Network。
之前介绍的 TD算法 的三种优化方法:
- 经验回放 / 优先经验回放
- Double DQN
- M-step TD target
都可以用在 训练 Dueling Network 上。
12.4 数学原理与不唯一性
之前推导 Dueling Network 原理的时候,有如下两个式子:
- \(Q^*(s,a)=V^*(s)+A^*(s,a)\)
- \(Q^*(s,a)=V^*(s)+A^*(s,a)-\mathop{max}\limits_{a}A^*(s,a)\)
我们为什么一定要用等式 2 而不是等式 1 呢?也就是为什么要加上一个 值为 0 的 \(\mathop{max}\limits_{a}A^*(s,a)\)?
这是因为 等式1 有一个问题。
即我们无法通过学习 Q-star 来 唯一确定 V-star 和 A-star,即对于求得的 Q-star 值,可以分解成无数组 V-star 和 A-star。
\(Q(s,a;w^A,w^V)=V(s;w^V)+A(s,a;w^A)-\mathop{max}\limits_{a}A(s,a;w^A)\)
我们是对 左侧Q 来训练整个 Dueling Network 的。如果 V 网络 向上波动 和 A 网络向下波动幅度相同,那么 Dueling Network 的输出完全相同,但是V-A两个网络都发生了波动,训练不好。
而加上最大化这一项就能避免不唯一性;即如果 V-star 向上波动10,A-star 向下波动10,那么整个式子的值会发生改变
因为max项随着A-star 的变化 也减少了10,总体上升了10
在上面的数学推导中,我们使用的是 \(\max \limits_{a}A(s,a;w^A)\)来近似最大项\(\max\limits_{a}A(s,a)\),而在实际应用中,用 \(\mathop{mean}\limits_{a}A(S,a;w^A)\)来近似效果更好;这种替换没有理论依据,但是实际效果好。
x. 参考教程
- 视频课程:深度强化学习(全)_哔哩哔哩_bilibili
- 视频原地址:https://www.youtube.com/user/wsszju
- 课件地址:https://github.com/wangshusen/DeepLearning
强化学习-学习笔记12 | Dueling Network的更多相关文章
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- ng-深度学习-课程笔记-12: 深度卷积网络的实例探究(Week2)
1 实例探究( Cast Study ) 这一周,ng对几个关于计算机视觉的经典网络进行实例分析,LeNet-5,AlexNet,VGG,ResNet,Inception. 2 经典网络( Class ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- Ext.Net学习笔记12:Ext.Net GridPanel Filter用法
Ext.Net学习笔记12:Ext.Net GridPanel Filter用法 Ext.Net GridPanel的用法在上一篇中已经介绍过,这篇笔记讲介绍Filter的用法. Filter是用来过 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
随机推荐
- Go语言 文件操作
@ 目录 引言 1. 打开和关闭文件 2. 读取文件 2.1 defer 语句 2.2 手动宕机处理 2.3 打开文件并获取内容 2.4 bufio 读取文件 2.5 ioutil 读取文件 2.6 ...
- Java中时间类中的Data类与Time类
小简博客 - 小简的技术栈,专注Java及其他计算机技术.互联网技术教程 (ideaopen.cn) Data类 Data类中常用方法 boolean after(Date date) 若当调用此方法 ...
- 攻防世界-MISC:base64÷4
这是攻防世界高手进阶区的第一题,题目如下: 点击下载附件一,发现是一个文本文档,打开后得到一串字符串 由题意猜测这些字符串应该是base16加密过的,写个脚本跑一下 import base64 s = ...
- 同时将代码备份到Gitee和GitHub
同时将代码备份到Gitee和GitHub 如何将GitHub项目一步导入Gitee 如何保持Gitee和GitHub同步更新 如何将GitHub项目一步导入Gitee 方法一: 登陆 Gitee 账号 ...
- [洛谷] P2241 统计方形(数据加强版)
点击查看代码 #include<bits/stdc++.h> using namespace std; long long n, m, total, sum1, sum2; int mai ...
- 干货 | Nginx 配置文件详解
一个执着于技术的公众号 前言 在前面章节中,我们介绍了nginx是什么.如何编译安装nginx及如何彻底卸载nginx软件. 干货|给小白的 Nginx 10分钟入门指南 Nginx编译安装及常用命令 ...
- dubbo发送过程编码失败,会唤醒发送线程吗?
dubbo发送过程编码失败,会唤醒发送(客户端业务)线程吗?如何实现的? 在上篇文章 dubbo坑- No provider available for the service xxx 中,如果dub ...
- this-2
读起来使你有新认识或可以使你离更确切的定义更近时的文章不应该被忽略.thisthis既不指向函数自身,也不指向函数的词法作用域(ES6中箭头函数采用词法作用域).this实际上是函数被调用时才发生绑定 ...
- 拯救一切强迫症 - 读《编写可维护的 JavaScript》(一)
拯救一切强迫症 - 读<编写可维护的 JavaScript>(一) 本文写于 2020 年 4 月 24 日 我在小学的时候就有接触过编程,所以读大一的时候 C 语言还算是轻车熟路.自然会 ...
- Random 中的Seed
C#中使用随机数 看下例 当Random的种子是0时 生成的随机数列表是一样的 也就是说当seed 一样时 审查的随机数时一样的 Random的无参实例默认 种子 时当前时间 如果要确保生成的随机数不 ...