【Python爬虫技巧】快速格式化请求头Request Headers
你好,我是 @马哥python说 。
我们在写爬虫时,经常遇到这种问题,从目标网站把请求头复制下来,粘贴到爬虫代码里,需要一点一点修改格式,因为复制的是字符串string格式,请求头需要用字典dict格式:
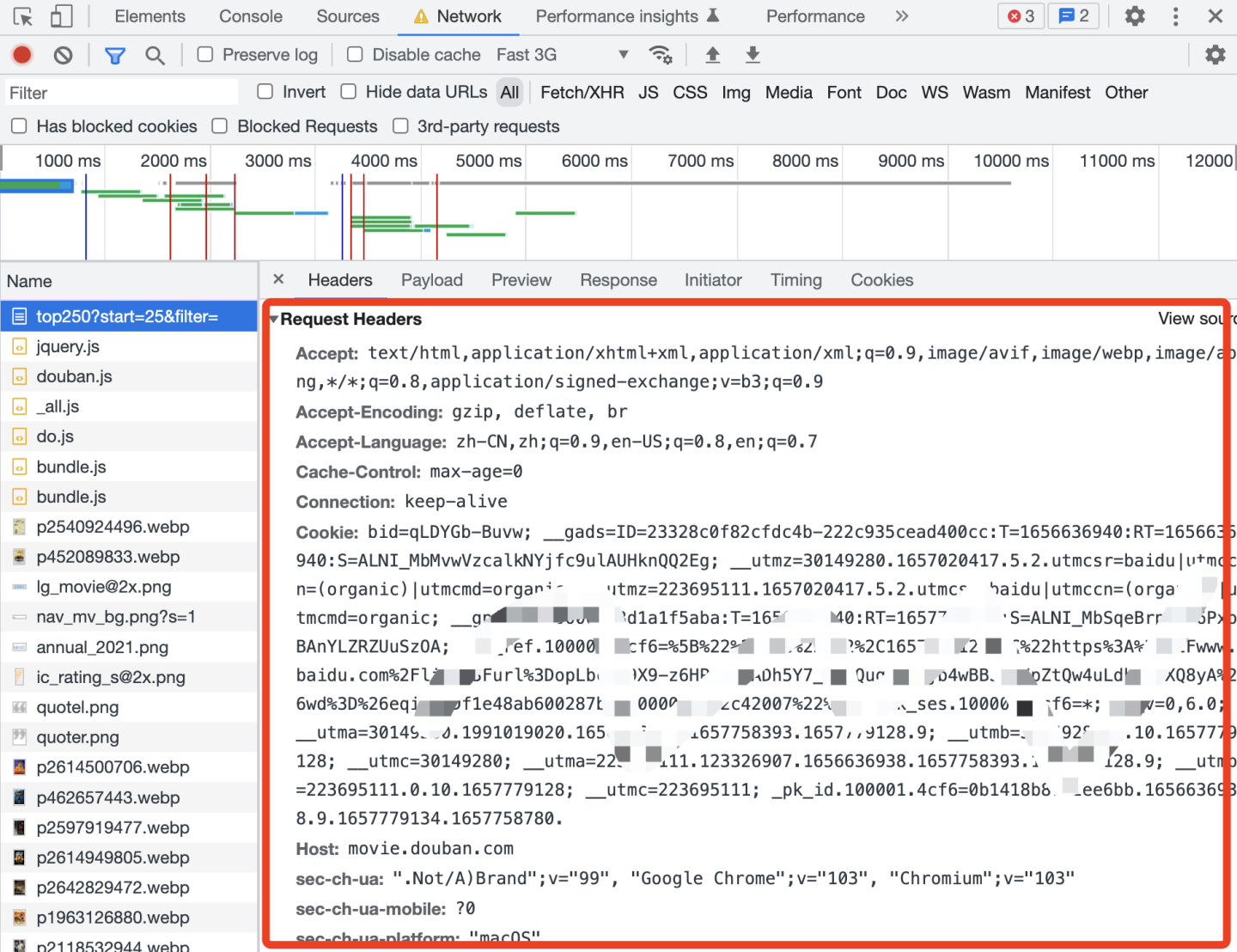
下面介绍一种简单的方法。
首先,把复制到的请求头放到一个字符串里:
# 请求头
headers = """
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
Cache-Control: max-age=0
Connection: keep-alive
Cookie: cookie值
Host: movie.douban.com
Referer: https://movie.douban.com/top250
sec-ch-ua: ".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
"""
然后,导入lxpy库:
from lxpy import copy_headers_dict
把刚才的字符串转换为字典:
# 转换请求头为字典格式
headers = copy_headers_dict(headers)
再看一眼现在的请求头,已经转成了字典格式:
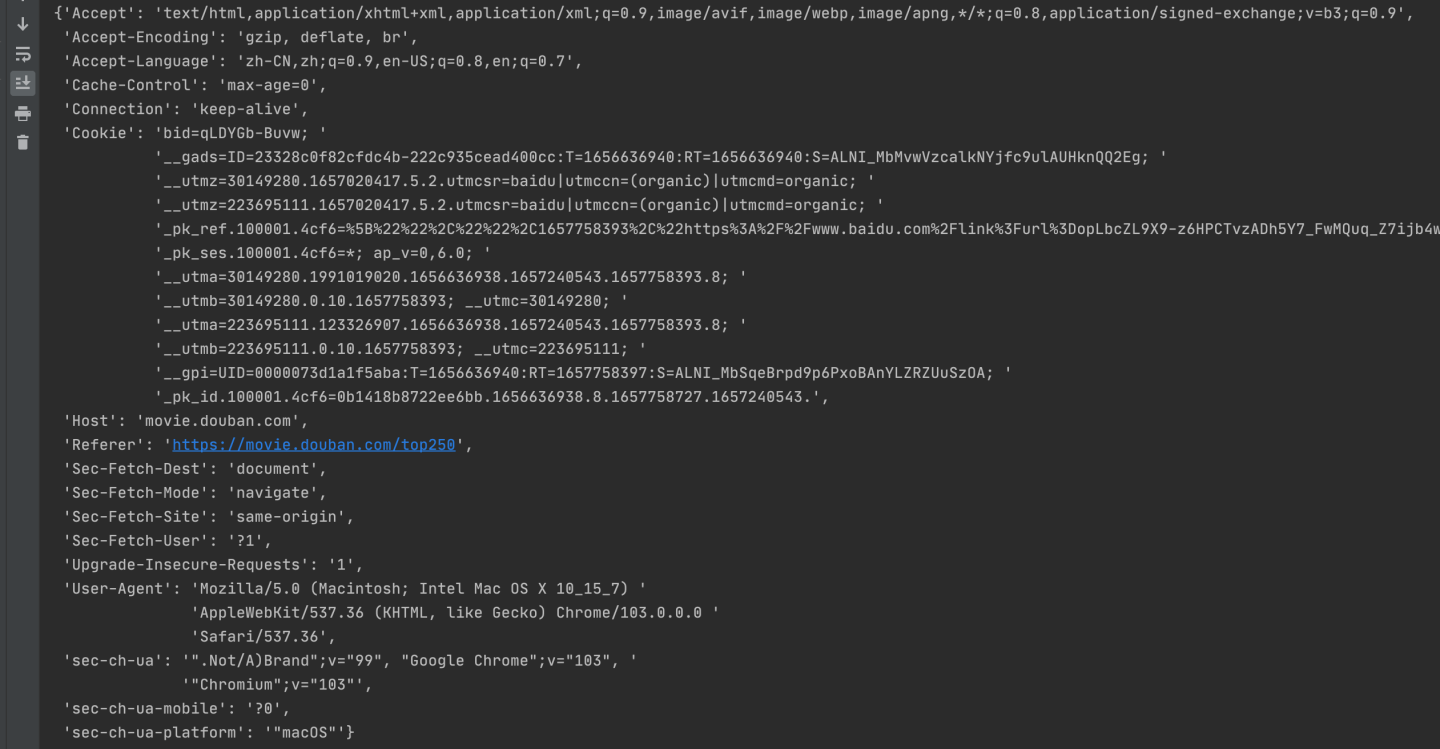
非常好用有没有!
下面,就可以继续开心的撸爬虫代码了~
同步讲解视频:
https://www.zhihu.com/zvideo/1530851114778210304
我是 @马哥python说 ,持续分享Python干货!
【Python爬虫技巧】快速格式化请求头Request Headers的更多相关文章
- Retrofit2.0+OkHttp设置统一的请求头(request headers)
有时候要求Retrofit2的接口中每个都要增加上headers,又不想做重复的事情,可以使用这种方法来为每个request请求都设置上相同的请求头header. 修改请求头request heade ...
- 请求头(request headers)和响应头(response headers)解析
*****************请求头(request headers)***************** POST /user/signin HTTP/1.1 --请求方式 文件名 http ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python爬虫技巧
Python爬虫技巧一之设置ADSL拨号服务器代理 reference: https://zhuanlan.zhihu.com/p/25286144 爬取数据时,是不是只能每个网站每个网站的分析,有没 ...
- python爬虫之快速对js内容进行破解
python爬虫之快速对js内容进行破解 今天介绍下数据被js加密后的破解方法.距离上次发文已经过去半个多月了,我写文章的主要目的是把从其它地方学到的东西做个记录顺便分享给大家,我承认自己是个懒猪.不 ...
- Python3 自定义请求头消息headers
Python3 自定义请求头消息headers 使用python爬虫爬取数据的时候,经常会遇到一些网站的反爬虫措施,一般就是针对于headers中的User-Agent,如果没有对headers进行设 ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- requests快速构造请求头的方法
上图请求头内容,内容多不说,也不确认哪些数据是必须的,网上找到一个懒办法 快速一键生成 Python 爬虫请求头 实战演练 抓取网站:https://developer.mozilla.org... ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
随机推荐
- 基本命令学习 -(4)链接文件:ln命令
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 前言 在Windows系统中,快捷方式是指向原始文件的一个链接文件,原文件一旦被删除或剪切到其 ...
- 看 AWS 如何通过 Nitro System 构建竞争优势
目录 目录 目录 前言 Amazon Nitro System Overview AWS EC2 的虚拟化技术演进之路 Nitro Hypervisor Nitro Cards Nitro Contr ...
- maven install resources failed: newPosition < 0: (-1 < 0)
添加以下代码在 pom.xml 中,具体参阅这里 <build> <plugins> <plugin> <groupId>org.apache.mave ...
- PostGIS 扩展创建失败原因调查
Issue 升级 PostgreSQL 9.1 的一个集群,由于该集群用到了 PostGIS,在升级 PostgreSQL 时也需要升级一下 PostGIS.PostGIS 相关软件安装好后,在 Po ...
- 好客租房53-context的使用
app组件要传递给child组件 该如何处理 更好的姿势 跨组件传递数据 Provider 用来提供数据 Consumer用来消费数据 1调用React.createContext() 创建provi ...
- Helloworld 驱动模块加载
介绍 本文引用<linux设备驱动开发>书中部分解释,记录开篇第一章helloworld程序 以下内容需要掌握如下基础信息linux模块概念.链接编译.c语言基础 内容 helloworl ...
- 个人冲刺(二)——体温上报app(一阶段)
任务:完成了WenData类的编写,同时完成了SecondActivity.java SecondActivity.java package com.example.helloworld; impor ...
- Fail2ban 命令详解 fail2ban-regex
fail2ban-regex是fail2ban提供的用来测试正则表达式的一个小工具,我们可以用它来测试正则表达式是否能够匹配到日志文件中的要禁止的IP行. fail2ban-regex默认情况下自动匹 ...
- 安装Suberversion[SVN]到CentOS(YUM)
运行环境 系统版本:CentOS Linux release 7.3.1611 (Core) 软件版本:Suberversion-1.7.14 硬件要求:无 安装过程 1.安装YUM-EPEL源 Su ...
- js循环调用axios异步请求,实现同步
准备: const axios = require('axios'); // axios请求 const res = []; const arr = ["a", "b&q ...