使用Caffe训练适合自己样本集的AlexNet网络模型,并对其进行分类
1.在开始之前,先简单回顾一下几个概念。
Caffe(Convolution Architecture For Feature Extraction-卷积神经网络框架):是一个清晰,可读性高,快速的深度学习框架。
CUDA(Compute Unifined Device Architecture-计算统一设备框架):是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
CuDNN( CUDA Deep Neural Network library):是NVIDIA专门针对深度神经网络设计的一套GPU计算加速库,被广泛用于各种深度学习框架,例如Caffe, TensorFlow, Theano, Torch, CNTK等。
2.Caffe的安装可参考一下博客:
http://www.cnblogs.com/hust-yingjie/p/6525584.html
http://blog.csdn.net/zb1165048017/article/details/51549105
http://blog.csdn.net/zb1165048017/article/details/51355143
3.安装过程出现的问题,以及解决方法,可参考:
http://www.cnblogs.com/hust-yingjie/p/6515213.html
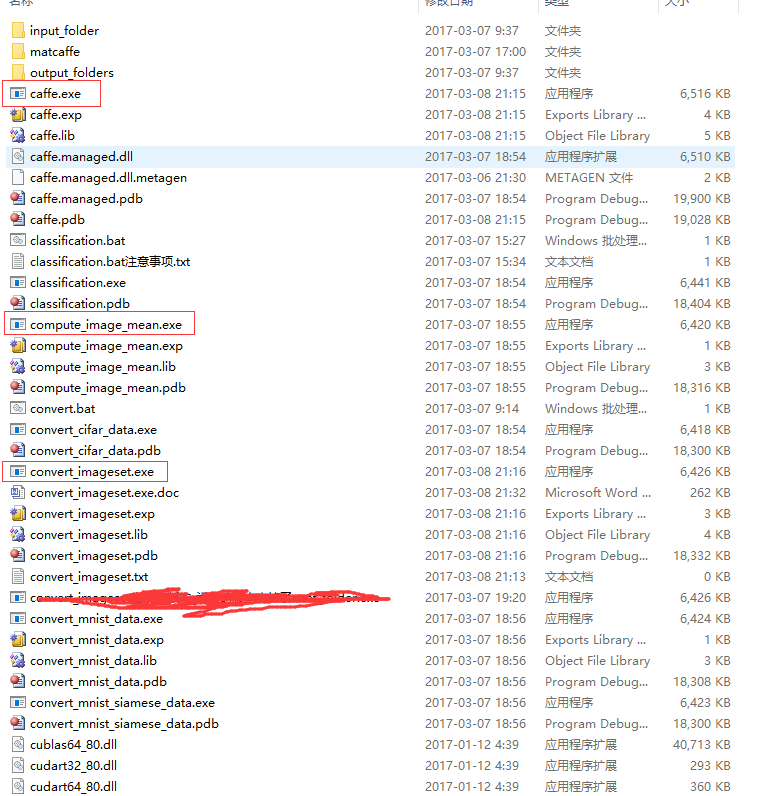
Caffe.sln中的16个工程编译成功,会生成12个.exe,如下图所示:
4.下面具体介绍基于Window训练自己的模型,并进行分类
4.1 第一步:制作Label标签文件,并利用convert_imageset.exe将图片转换为Caffe的数据格式LEVELDB格式或者lmdb格式。
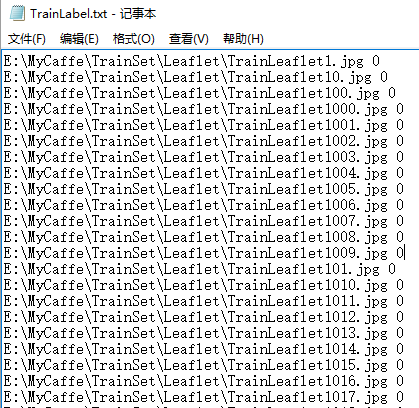
训练样本的标签文件TrainLabel.txt如下图所示:
测试样本的标签文件TestLabel.txt如下图所示:

此时需重新生成一下convert_imageset.exe文件,具体见http://www.cnblogs.com/hust-yingjie/p/6526419.html
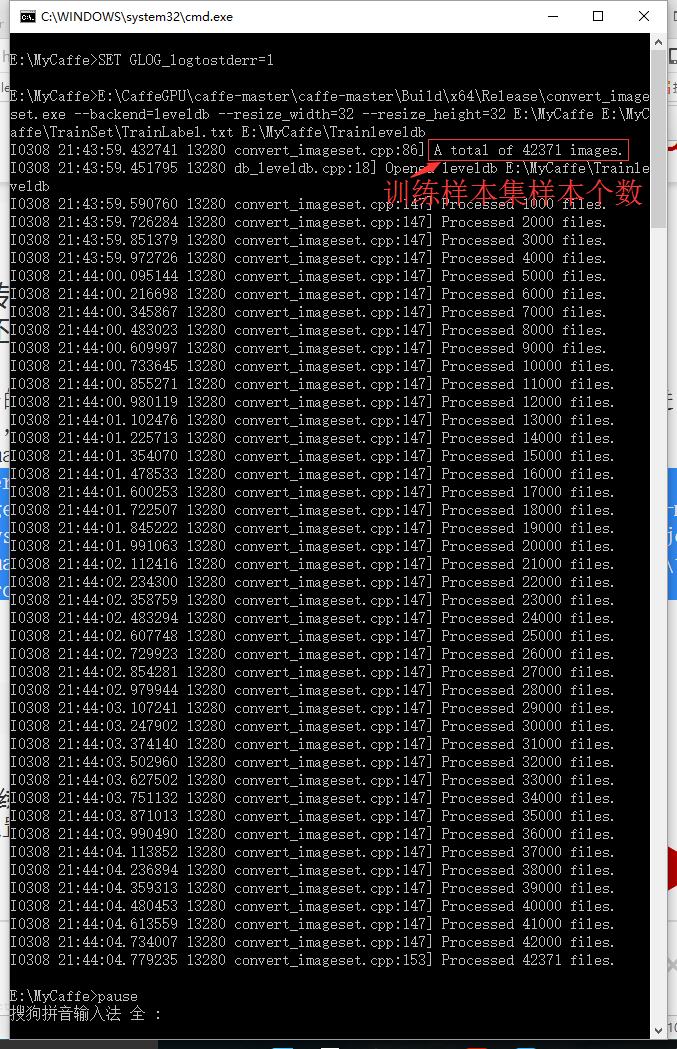
可根据实际情况执行convert_imageset.exe文件,其参数信息可打开convert_imageset.cpp查看,下面是我执行其的批处理文件,测试样本集类似:
SET GLOG_logtostderr=1
E:\CaffeGPU\caffe-master\caffe-master\Build\x64\Release\convert_imageset.exe --backend=leveldb --resize_width=32 --resize_height=32 E:\MyCaffe E:\MyCaffe\TrainSet\TrainLabel.txt E:\MyCaffe\Trainleveldb
pause
正确执行后,你会看到如下界面:
执行上述过程,可能出现以下两种情况,如下图所示:
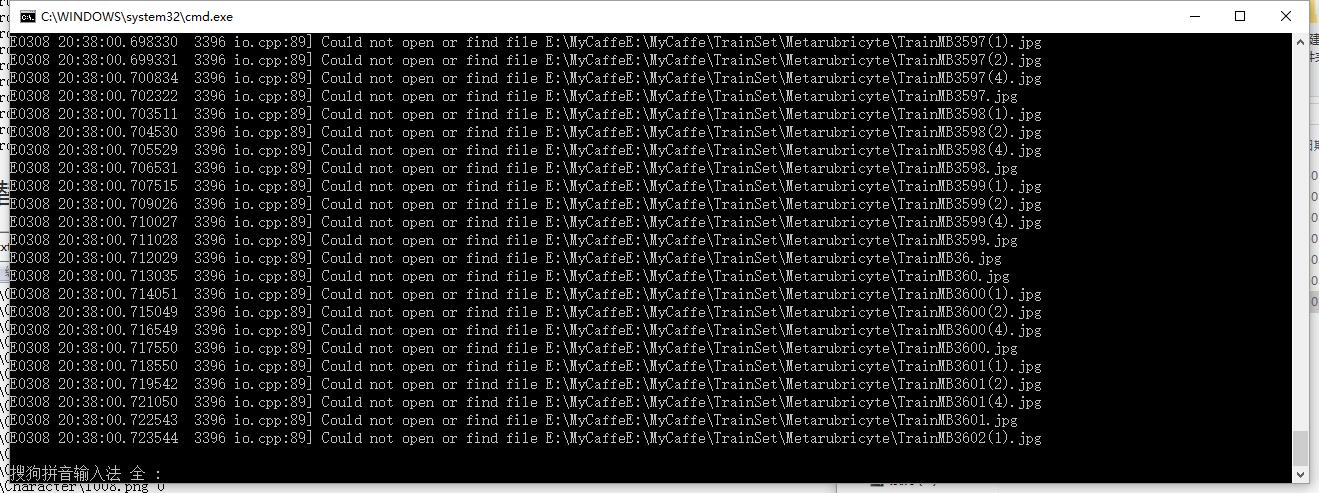
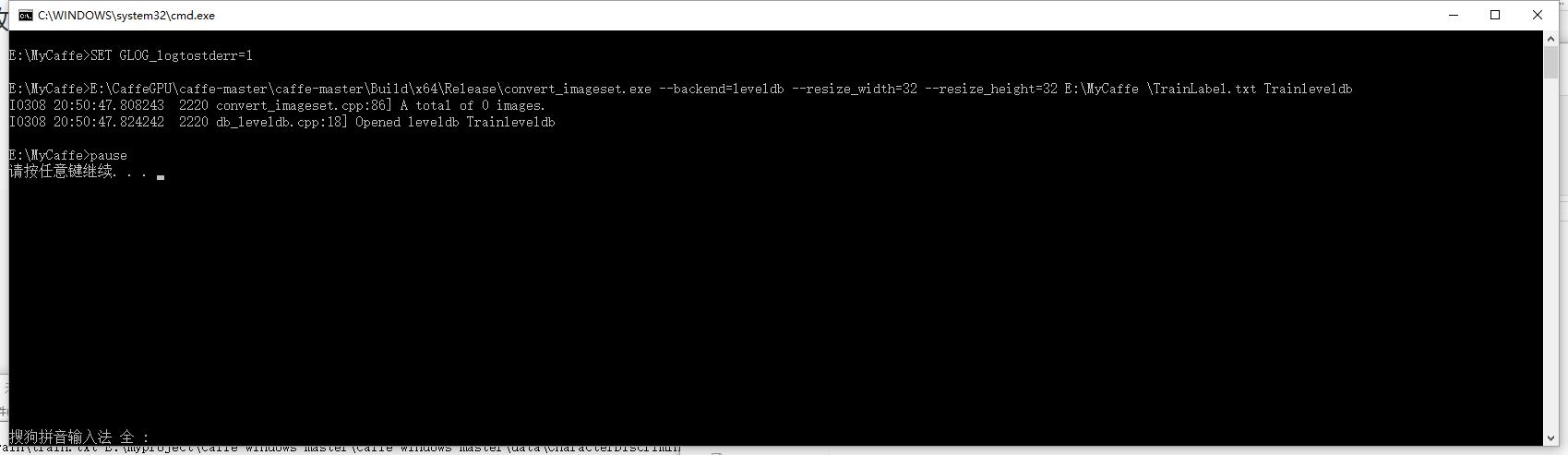
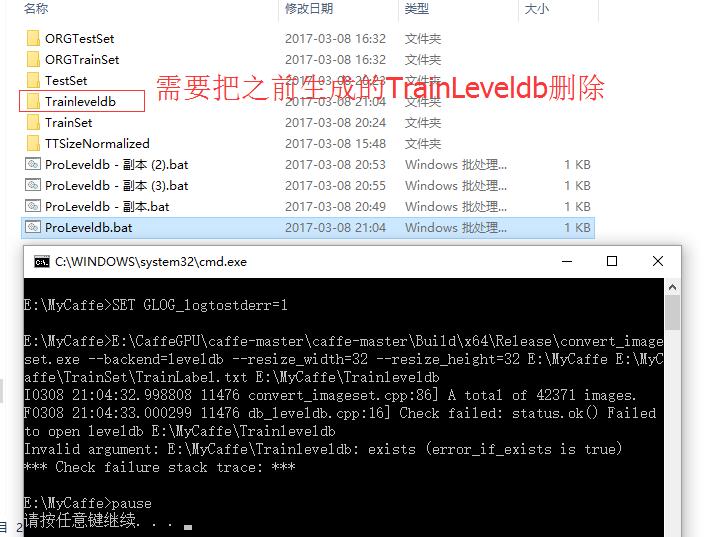
上面两种错误,都是由于路径错误导致,所以这里一定要注意。还有一种错误,解决比较简单,见下图:
成功后,会生成一个Trainleveldb文件夹,里面有如下内容:
4.2 第二步:基于LEVELDB文件利用compute_image_mean.exe获取均值文件Mean.binaryproto
可参考以下批处理文件执行compute_image_mean.exe,具体如下:
SET GLOG_logtostderr=1
E:\CaffeGPU\caffe-master\caffe-master\Build\x64\Release\convert_imageset.exe --backend=leveldb --resize_width=256 --resize_height=256 E:\MyCaffe E:\MyCaffe\TrainSet\TrainLabel.txt E:\MyCaffe\Trainleveldb
pause
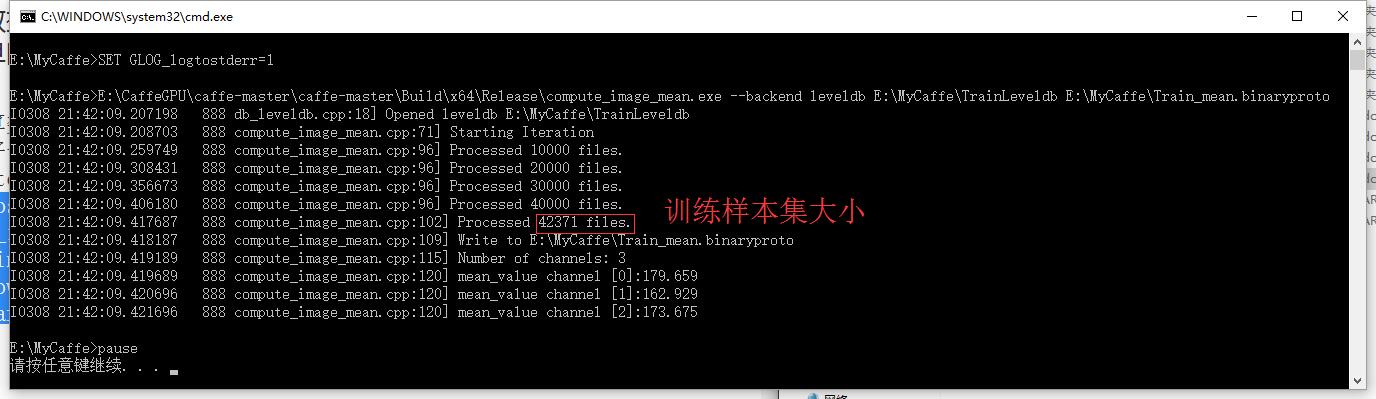
正确执行后的效果如下图所示:
4.3 第三步:定义网络结构并进行训练
在安装的Caffe目录下找到\models\bvlc_alexnet文件夹,里面有如下内容:
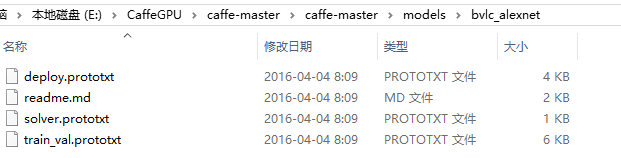
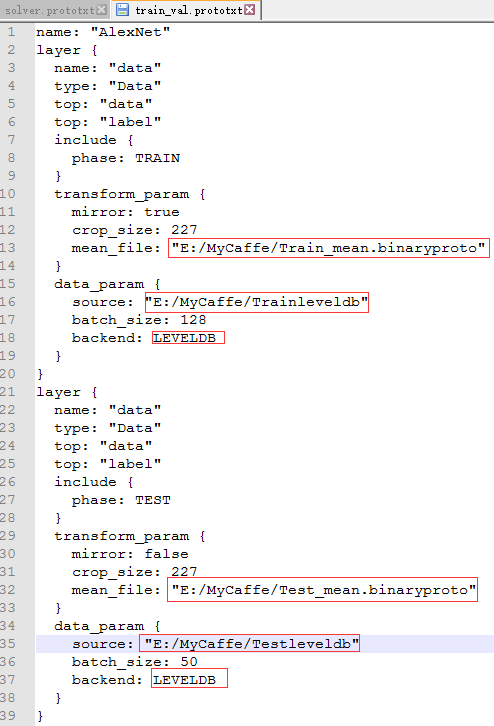
将最后两个文件拷贝到自己的工程目录下,并做一下修改:
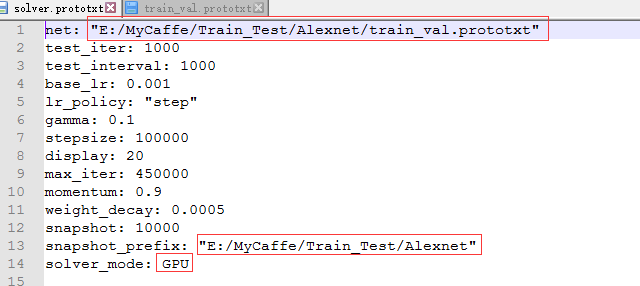
如果你使用的LMDB文件格式,就不需要修改backend,否则就需修改为LEVELDB数据格式。
4.4 第四步:利用Caffe.exe文件训练AlexNet模型网络
基于第三步的两个文件,执行Caffe.exe文件,可参考下面批处理文件,具体如下:
E:\CaffeGPU\caffe-master\caffe-master\Build\x64\Release\caffe.exe train --solver=E:/MyCaffe/Train_Test/Alexnet/solver.prototxt
pause
正确执行的效果,如下图所示:
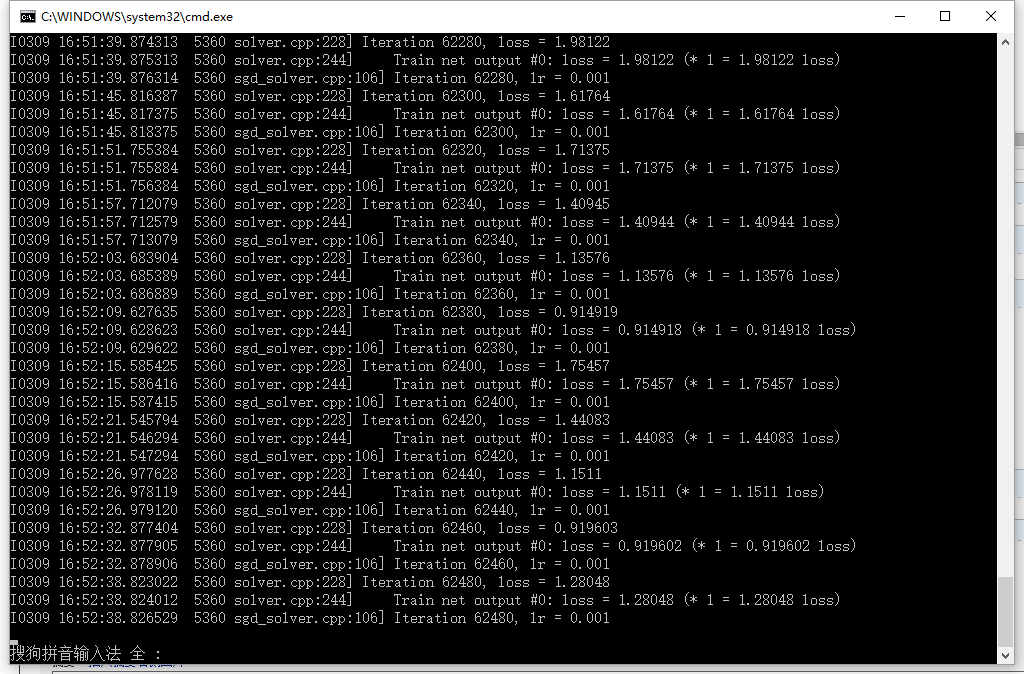
可参考:http://m.blog.csdn.net/article/details?id=51001536
4.5 第五步:测试模型
上述步骤完成后,会得到两个文件,第一个caffemodel是训练完毕得到的模型参数文件,第二个solverstate是训练中断以后,可以用此文件从中断地方继续训练,具体如下所示:
后面的操作参考:http://blog.csdn.net/zb1165048017/article/details/51483206
使用Caffe训练适合自己样本集的AlexNet网络模型,并对其进行分类的更多相关文章
- Caffe训练AlexNet网络,精度不高或者为0的问题结果
当我们使用Caffe训练AlexNet网络时,会遇到精度一值在低精度(30%左右)升不上去,或者精度总是为0,如下图所示: 出现这种情况,可以尝试使用以下几个方法解决: 1.数据样本量是否太少,最起码 ...
- 【转】[caffe]深度学习之图像分类模型AlexNet解读
[caffe]深度学习之图像分类模型AlexNet解读 原文地址:http://blog.csdn.net/sunbaigui/article/details/39938097 本文章已收录于: ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 使用caffe训练mnist数据集 - caffe教程实战(一)
个人认为学习一个陌生的框架,最好从例子开始,所以我们也从一个例子开始. 学习本教程之前,你需要首先对卷积神经网络算法原理有些了解,而且安装好了caffe 卷积神经网络原理参考:http://cs231 ...
- 实践详细篇-Windows下使用Caffe训练自己的Caffemodel数据集并进行图像分类
三:使用Caffe训练Caffemodel并进行图像分类 上一篇记录的是如何使用别人训练好的MNIST数据做训练测试.上手操作一边后大致了解了配置文件属性.这一篇记录如何使用自己准备的图片素材做图像分 ...
- caffe训练自己的图片进行分类预测--windows平台
caffe训练自己的图片进行分类预测 标签: caffe预测 2017-03-08 21:17 273人阅读 评论(0) 收藏 举报 分类: caffe之旅(4) 版权声明:本文为博主原创文章,未 ...
- [caffe] caffe训练tricks
Tags: Caffe Categories: Tools/Wheels --- 1. 将caffe训练时将屏幕输出定向到文本文件 caffe中自带可以画图的工具,在caffe路径下: ./tools ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe训练AlexNet网络模型——问题三
caffe 进行自己的imageNet训练分类:loss一直是87.3365,accuracy一直是0 解决方法: http://blog.csdn.net/jkfdqjjy/article/deta ...
随机推荐
- 数据分析与展示---Pandas库数据特征分析
说明:0轴axis=0和1轴axis=1 简介 一:数据的排序 二:数据的基本统计分析 三:数据的累积统计分析 四:数据的相关分析 一:数据的排序 a b c d a b c d 二:数据的基本统计分 ...
- Mongo 后台加索引踩坑
背景,随着mongo数据量变大,查询效率变低,要对索引进行优化,所在公司对mongo依赖比较严重,而DBA并不对mongo的权限做控制,所以每个后端开发都有mongo的读写权限,通常每个人各自管理自己 ...
- [NOI1999] 棋盘分割
COGS 100. [NOI1999] 棋盘分割 http://www.cogs.pro/cogs/problem/problem.php?pid=100 ★★ 输入文件:division.in ...
- python学习笔记2-dict
常用的dict操作: d={'name':'suki', ', 'sex':'man', 'addr':'nanjing' } #字典取值方便,但是字典是没有顺序的,List有下标 print(d[' ...
- [整理]标准C中的"布尔"类型
C语言提供的基本数据类型:char , int ,float, double. 为什么没有其他语言中常见bool布尔数据类型呢? 1.在标准C语言(ANSI C)中并没有bool数据类型 标准C中,表 ...
- 20145209 2016-2017-2 《Java程序设计》第7周学习总结
20145209 2016-2017-2 <Java程序设计>第7周学习总结 教材学习内容总结 read()每次读入一个字节. eg:short2个字节,2=0x0201,读入后要0x & ...
- Cloudera Manager Admin控制台启动不起来
这几天都在搞大数据这一块,由于以前自己在弄hadoop等安装的时候特别的费劲,于是乎找到了广大程序员的福音——cloudera manager,但是第一步安装好了以后无法启动,再三思考+百度发现: 通 ...
- Spring4笔记12--SSH整合3--Spring与Struts2整合
SSH 框架整合技术: 3. Spring与Struts2整合(对比SpringWeb): Spring 与 Struts2 整合的目的有两个: (1)在 Struts2 的 Action 中,即 V ...
- 配置虚拟机时间使其与国内时间同步,linux时间 ntp
设置系统时间 [root@node2 ~]# date -s "10/30/18 09:30:00"Tue Oct 30 09:30:00 PDT 2018[root@node2 ...
- 读后感+资源-----java8函数式编程pdf
花了两周时间工作之余抽空读完了这本书,对lamdba以及java的理解又有了一个新的认识(装个逼,哈哈) 以前看视频学习的还是太基本了,感觉读书更容易理解背后的设计思想和编程思路 这本书还是挺不错,就 ...