(转)park1.0.0生态圈一览
转自博客:http://www.tuicool.com/articles/FVBJBjN
Spark1.0.0生态圈一览
Spark生态圈,也就是BDAS(伯克利数据分析栈),是伯克利APMLab实验室精心打造的,力图在算法(Algorithms)、机器(Machines)、人(People)之间通过大规模集成,来展现大数据应用的一个平台,其核心引擎就是Spark,其计算基础是弹性分布式数据集,也就是RDD。通过Spark生态圈,AMPLab运用大数据、云计算、通信等各种资源,以及各种灵活的技术方案,对海量不透明的数据进行甄别并转化为有用的信息,以供人们更好的理解世界。Spark生态圈已经涉及到机器学习、数据挖掘、数据库、信息检索、自然语言处理和语音识别等多个领域。
随着spark的日趋完善,spark以其优异的性能正逐渐成为下一个业界和学术界的开源大数据处理平台。随着spark1.0.0的发布和spark生态圈的不断扩大,可以预见在今后的一段时间内,Spark将越来越火热。下面我们来看看最近的Spark1.0.0生态圈,也就是BDAS(伯克利数据分析栈),对Spark生态圈做一简单的介绍。
如下图所示,Spark生态圈以Spark为核心引擎,以HDFS、S3、techyon为持久层读写原生数据,以Mesos、YARN和自身携带的 Standalone作为资源管理器调度job,来完成spark应用程序的计算;而这些spark应用程序可以来源于不同的组件,如Spark的批处理应用、SparkStreaming的实时处理应用、Spark SQL的即席查询、BlinkDB的权衡查询、MLlib或MLbase的机器学习、GraphX的图处理、来自SparkR的数学计算等等。更多的新信息请参看伯克利APMLab实验室的项目进展 https://amplab.cs.berkeley.edu/projects/ 或者 Spark峰会信息 http://spark-summit.org/ 。

:生态圈简介
A:Spark
Spark是一个快速的通用大规模数据处理系统,和Hadoop MapRedeuce相比:
- 更好的容错性和内存计算
- 倍速度于MapReduce
- 易用,相同的应用程序代码量要比MapReduce少2-5倍
- 提供了丰富的API
- 支持互动和迭代程序
Spark大数据平台之所以能日渐红火,得益于Spark内核架构的优秀:
- 提供了支持DAG图的分布式并行计算框架,减少多次计算之间中间结果IO开销
- 提供Cache机制来支持多次迭代计算或者数据共享,减少IO开销
- RDD之间维护了血统关系,一旦RDD fail掉了,能通过父RDD自动重建,保证了容错性
- 移动计算而非移动数据,RDD Partition可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算
- 使用多线程池模型来减少task启动开稍
- shuffle过程中避免不必要的sort操作
- 采用容错的、高可伸缩性的akka作为通讯框架
B:SparkStreaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、 Zero和TCP 套接字)进行类似map、reduce、join、window等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
SparkStreaming流式处理系统特点有:
- 将流式计算分解成一系列短小的批处理作业
- 将失败或者执行较慢的任务在其它节点上并行执行
- 较强的容错能力(基于RDD继承关系Lineage)
- 使用和RDD一样的语义

C:Spark SQL
Spark SQL是一个即席查询系统,其前身是shark,不过代码几乎都重写了,但利用了shark的最好部分内容。Spark SQL可以通过SQL表达式、HiveQL或者Scala DSL在Spark上执行查询。目前Spark SQL还是一个alpha版本。
Spark SQL的特点:
- 引入了新的RDD类型SchemaRDD,可以象传统数据库定义表一样来定义SchemaRDD,SchemaRDD由定义了列数据类型的行对象构成。
- SchemaRDD可以从RDD转换过来,也可以从Parquet文件读入,也可以使用HiveQL从Hive中获取。
- 在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行join操作。
- 内嵌catalyst优化器对用户查询语句进行自动优化

D:BlinkDB
BlinkDB是一个很有意思的交互式查询系统,就像一个跷跷板,用户需要在查询精度和查询时间上做一权衡;如果用户想更快地获取查询结果,那么将牺牲查询结果的精度;同样的,用户如果想获取更高精度的查询结果,就需要牺牲查询响应时间。用户可以在查询的时候定义一个失误边界。
BlinkDB的设计核心思想:
- 通过采样,建立并维护一组多维度样本
- 查询进来时,选择合适的样本来运行查询

E:MLbase/MLlib
MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类,回归,聚类,协同过滤,降维,以及底层优化。
MLbase通过边界定义,力图将MLbase打造成一个机器学习平台,让机器学习的门槛更低,让一些可能并不了解机器学习的用户也能方便地使用MLbase这个工具来处理自己的数据,MLbase定义了四个边界:
- ML Optimizer 优化器会选择最适合的、已经实现好了的机器学习算法和相关参数
- MLI 是一个进行特征抽取和高级ML编程抽象的算法实现的API或平台
- MLlib 基于Spark的底层分布式机器学习库,可以不断的扩充算法
- MLRuntime 基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。

F:GraphX
GraphX是基于Spark的图处理和图并行计算API。GraphX定义了一个新的概念:弹性分布式属性图,一个每个顶点和边都带有属性的定向多重图;并引入了三种核心RDD:Vertices、Edges、Triplets;还开放了一组基本操作(如subgraph, joinVertices, and mapReduceTriplets),并且在不断的扩展图形算法和图形构建工具来简化图分析工作。

G:SparkR
SparkR是AMPLab发布的一个R开发包,使得R摆脱单机运行的命运,可以作为Spark的job运行在集群上,极大得扩展了R的数据处理能力。
Spark的几个特性:
- 提供了Spark中弹性分布式数据集(RDD)的API,用户可以在集群上通过R shell交互性的运行Spark job。
- 支持序化闭包功能,可以将用户定义函数中所引用到的变量自动序化发送到集群中其他的机器上。
- SparkR还可以很容易地调用R开发包,只需要在集群上执行操作前用includePackage读取R开发包就可以了,当然集群上要安装R开发包。

:生态圈的应用
Spark生态圈以Spark为核心、以RDD为基础,打造了一个基于内存计算的大数据平台,为人们提供了all-in-one的数据处理方案。人们可以根据不同的场景使用spark生态圈的多个产品来解决应用,而不是使用多个隔离的系统来满足场景需求。下面是几个典型的例子:
:历史数据和实时数据分析查询
通过spark进行历史数据分析、spark Streaming进行实时数据分析,最后通过spark SQL或BlinkDB给用户交互查询。

:欺诈检测、异常行为的发现
通过spark进行历史数据分析,用MLlib建立数据模型,对Spark Streaming实时数据进行评估,检测并发现异常数据。

:社交网络洞察
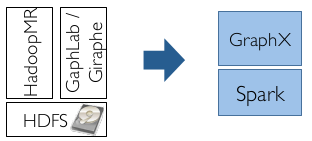
通过Spark和GraphX计算社交关系,给出建议
(转)park1.0.0生态圈一览的更多相关文章
- Spark1.0.0 生态圈一览
Spark生态圈,也就是BDAS(伯克利数据分析栈),是伯克利APMLab实验室精心打造的,力图在算法(Algorithms).机器(Machines).人(People)之间通过大规模集 ...
- MongoDB 3.0新增特性一览
转自:http://blog.sina.com.cn/s/blog_48c95a190102vedr.html 引言 在历经版本号修改(2.8版本直接跳到3.0版本)和11个rc版本之后,MongoD ...
- Spark1.0.0 学习路径
2014-05-30 Spark1.0.0 Relaease 经过11次RC后最终公布.尽管还有不少bug,还是非常令人振奋. 作为一个骨灰级的老IT,经过非常成一段时间的消沉,再次被点燃 ...
- Spark1.0.0 学习路线指导
转自:http://www.aboutyun.com/thread-8421-1-1.html 问题导读1.什么是spark?2.spark编程模型是什么?3.spark运维需要具有什么知识?4.sp ...
- 复利计算--结对项目<04-11-2016> 1.0.0 lastest 阶段性完工~
结对项目:Web复利计算 搭档博客地址:25江志彬 http://www.cnblogs.com/qazwsxedcrfv/ 个人摘要: (2016-04-09-12:00)补充:之前传送门没做好, ...
- Powermock2.0.0 详细 总结
目录 1 单元测试 2 Junit测试框架 2.1 Junit是什么 2.2 Junit 能做什么? 3 Junit测试的局限性 4 Mock技术 5 相关的Mock工具 5.1 Mockito.Ea ...
- 离线方式部署Ambari2.6.0.0
Hadoop生态圈-离线方式部署Ambari2.6.0.0 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我现在所在的公司用的是CDH管理Hadoop集群,前端时间去面试时发现很多 ...
- Castle Core 4.0.0 alpha001发布
时隔一年多以后Castle 项目又开始活跃,最近刚发布了Castle Core 4.0.0 的alpha版本, https://github.com/castleproject/Core/releas ...
- ASP.NET Core: You must add a reference to assembly mscorlib, version=4.0.0.0
ASP.NET Core 引用外部程序包的时候,有时会出现下面的错误: The type 'Object' is defined in an assembly that is not referenc ...
随机推荐
- JS日期与字符串相互转换!!
一 日期转字符串 dateToString: function(date){ var year = date.getFullYear(); var month =(date.getMonth() + ...
- Centos7安装FTP突然无法登录
vi /etc/pam.d/vsftpd //注释掉auth required pam_shells.so session optional pam_keyinit.so force revokeau ...
- 空洞卷积(dilated Convolution) 与感受野(Receptive Field)
一.空洞卷积 空洞卷积是是为了解决基于FCN思想的语义分割中,输出图像的size要求和输入图像的size一致而需要upsample,但由于FCN中使用pooling操作来增大感受野同时降低分辨率,导致 ...
- HTTP之一 If-Modified-Since & If-None-Match
If-Modified-Since & If-None-MatchIf-Modified-Since,和 Last-Modified 一样都是用于记录页面最后修改时间的 HTTP 头信息,只是 ...
- centos7联网
一般centos安装(在虚拟机上安装)完成后需要自己配置服务,下面我就讲下如何配置 配置联网步骤 首先,打开虚拟机的两个服务,右击我的电脑-->管理--->找到服务-->右击启动 两 ...
- 浮动元素垂直居中,bootstrap栅格布局垂直居中
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Unix IPC之共享内存区(1)
1 共享内存区 共享内存区是可用IPC形式中最快的,只有映射和解除映射需要进入内核的系统调用,映射后对共享内存区的访问和修改不再需要系统调用(内核只要负责好页表映射和处理页面故障即可),但通常需要同步 ...
- 最邻近规则分类KNN算法
例子: 求未知电影属于什么类型: 算法介绍: 步骤: 为了判断未知实例的类别,以所有已知类别的实例作为参照 选择参数K 计算未知实例与所有已知实例的距离 选择最近K个已 ...
- ASP.NET Web API 2:创建API帮助页面
当你新建了一个web API服务之后,再建一个API帮助页面是很有好处的,这样其他开发人员就会很清楚地知道如何调用你的API接口.你可以选择自己手工建立,但是如果能自动生成岂不是更好.为了简 ...
- Dubbo的特点
1.介绍 DUBBO有良好的连通性.健壮性.伸缩性.升级性.结合dubbo可以相对于单体系统提升系统整体的扩展性 2. 连通性 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在 ...