GridSearchCV
GridSearchCV 简介:
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。这个时候就是需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试吧,后续可以再拿bagging再优化。回到sklearn里面的GridSearchCV,GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。
常用参数解读:
estimator:所使用的分类器,如estimator=RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_depth=8,max_features='sqrt',random_state=10), 并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法。
param_grid:值为字典或者列表,即需要最优化的参数的取值,param_grid =param_test1,param_test1 = {'n_estimators':range(10,71,10)}。
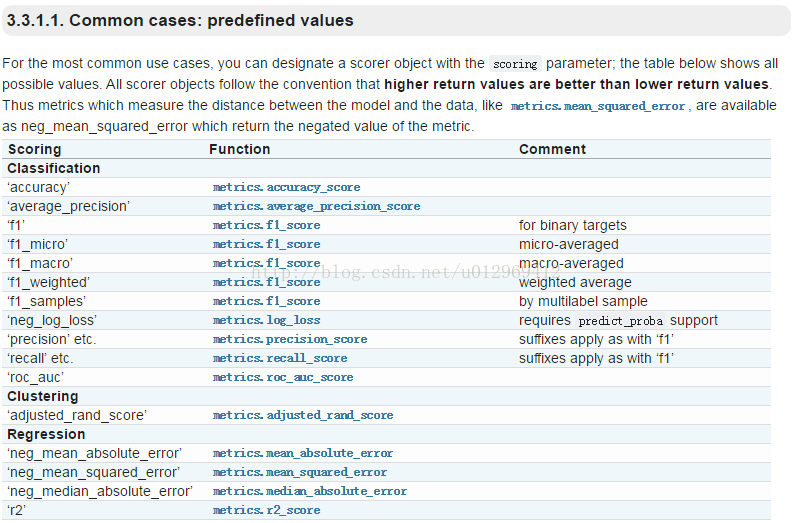
scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。scoring参数选择如下:
参考地址:http://scikit-learn.org/stable/modules/model_evaluation.html
cv :交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
refit :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
pre_dispatch:指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次。
常用方法:
grid.fit():运行网格搜索
grid_scores_:给出不同参数情况下的评价结果
best_params_:描述了已取得最佳结果的参数的组合
best_score_:成员提供优化过程期间观察到的最好的评分
使用案例:
param_test1 = { 'max_depth':list(range(3,10,1))
,'min_child_weight':list(range(1,6,2))
}
gsearch1 = GridSearchCV(
estimator = XGBClassifier(
silent=1 ,#设置成1则没有运行信息输出,最好是设置为0.是否在运行升级时打印消息。
learning_rate= 0.1,# 如同学习率
# max_depth=4,# 构建树的深度,越大越容易过拟合
colsample_bytree=1, # 生成树时进行的列采样
reg_lambda=4, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
objective= 'binary:logistic', #多分类的问题 指定学习任务和相应的学习目标
n_estimators=70, # 树的个数
),
param_grid = param_test1, scoring='roc_auc', iid=False, cv=5)
gsearch1.fit(X,y)
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
GridSearchCV的更多相关文章
- scikit-learn一般实例之四:使用管道和GridSearchCV选择降维
本例构建一个管道来进行降维和预测的工作:先降维,接着通过支持向量分类器进行预测.本例将演示与在网格搜索过程进行单变量特征选择相比,怎样使用GrideSearchCV和管道来优化单一的CV跑无监督的PC ...
- pipeline结合GridSearchCV的一点小介绍
clf = tree.DecisionTreeClassifier() ''' GridSearchCV search the best params ''' pipeline = Pipeline( ...
- 机器学习——交叉验证,GridSearchCV,岭回归
0.交叉验证 交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set) ...
- GridsearchCV调参
在利用gridseachcv进行调参时,其中关于scoring可以填的参数在SKlearn中没有写清楚,就自己找了下,具体如下: parameters = {'eps':[0.3,0.4,0.5,0. ...
- GridSearchCV交叉验证
代码实现(基于逻辑回归算法): # -*- coding: utf-8 -*- """ Created on Sat Sep 1 11:54:48 2018 @autho ...
- 封装GridSearchCV的训练包
import xgboost as xgb from sklearn.model_selection import GridSearchCV from sklearn.metrics import m ...
- StratifiedKFold与GridSearchCV版本前后使用方法
首先在sklearn官网上你可以看到: 所以,旧版本import时: from sklearn.cross_validation import GridSearchCV 新版本import时: fro ...
- 集成树模型使用自动搜索模块GridSearchCV,stacking
一. GridSearchCV参数介绍 导入模块: from sklearn.model_selection import GridSearchCV GridSearchCV 称为网格搜索交叉验证调参 ...
- sklearn的GridSearchCV例子
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_j ...
- 机器学习入门-随机森林预测温度-不同参数对结果的影响调参 1.RandomedSearchCV(随机参数组的选择) 2.GridSearchCV(网格参数搜索) 3.pprint(顺序打印) 4.rf.get_params(获得当前的输入参数)
使用了RamdomedSearchCV迭代100次,从参数组里面选择出当前最佳的参数组合 在RamdomedSearchCV的基础上,使用GridSearchCV在上面最佳参数的周围选择一些合适的参数 ...
随机推荐
- Codeforces758B Blown Garland 2017-01-20 10:19 87人阅读 评论(0) 收藏
B. Blown Garland time limit per test 1 second memory limit per test 256 megabytes input standard inp ...
- Scala偏函数与部分函数
函数 1.部分函数 部分应用函数(Partial Applied Function)是缺少部分参数的函数,是一个逻辑上概念. def sum(x: Int, y: Int, z: Int) = x + ...
- 在EBS里新建一个OU的步骤
http://blog.csdn.net/kevingao/archive/2010/09/11/5877092.aspx 在EBS里新建一个OU的步骤1. 建立OU组织,关联SOB,LE2. 系统管 ...
- mod_pagespeed
https://github.com/pagespeed/mod_pagespeed.git https://developers.google.com/speed/pagespeed/module/ ...
- EasyUi TreeGrid/DataGrid getChecked BUG
问题描述 步骤一,选中左边树一个节点,然后出现相应的数据,选中进行保存.如,我选中了前4个节点,上图: 步骤二,我再选tree中第二个节点,进行相应的选中和取消选中treegrid中的节点,并保存. ...
- Argument list too long error for rm, cp, mv commands
Another option is to use find's -delete flag: find . -name "*.pdf" -delete
- [翻译]NUnit---RequiresSTA and RequiresThread Attributes(十七)
RequiresSTAAttribute (NUnit 2.5) RequiresSTA特性用于测试方法.类.程序集中指定测试应该在单线程中运行.如果父测试不在单线程中运行则会创建一个新的线程. No ...
- .NET 任务调度Quartz系列(1)——自建定时任务
在我们平时项目中经常会遇到定时任务,比如定时同步数据,定时备份数据,定时统计数据等,定时任务我们都知道使用Quartz.net,此系列写的也是Quartz,但是在此之前,我们先用其他方式做个简单的定时 ...
- .net core 读取本地指定目录下的文件
项目需求 asp.net core 读取log目录下的.log文件,.log文件的内容如下: xxx.log ------------------------------------------beg ...
- css小点心
本文由作者邹欣华授权网易云社区发布. 有一个在邮件中用饼图直观地显示用户的各项消费比例的需求.邮箱中不能用js,纯css实现饼图,只能通过后端模版渲染数据,所以数据越少越简单越好. 想到css3的tr ...