python中的递归问题,求圆周率
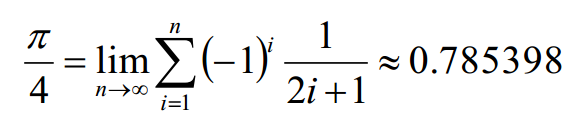
以上面一个公式为例:
import numpy as np
def getPi(n):
if n == 0:
return np.power(-1,n)*(1.0/(2*n+1))
else:
return np.power(-1,n)*(1.0/(2*n+1))+getPi(n-1) print 4*getPi(100)
可以通过上面一个递归实现。
特点:
①递归就是在过程或者函数里调用自身。
②在使用递归策略时,必须有一个明确的递归条件,称为递归出口。
③递归算法解题通常显得很简洁,但递归算法解题的效率较低。所以一般不倡导使用递归算法设计程序。
④在递归调用的过程当中系统的每一层的返回点、局部变量等开辟了栈来存储。递归函数次数过多容易造成栈溢出等。
所以一般不倡导用递归算法设计程序。
要求:
递归算法所体现的"重复"一般有三个条件:
①每次在调用规模上都有所缩小(通常是减半)。
②相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入)。
③在问题的规模极小时必须用直接接触解答而不再进行递归调用,因而每次递归调用都是有条件的(以规模未达到直接解答的大小为条件),
无条件的递归调用将会成为死循环而不能正常结束。
每当你调用一个函数,在这个函数执行前都会将之前的代码地址(也就是调用点)入栈,等被调用的函数执行完将地址出栈,程序根据这个数据返回调用点。
若递归调用次数太多,就会只入栈不出栈,于是堆栈就被压爆了,此为栈溢出。
python中的解决办法:
1、人为设置递归深度
import sys
sys.setrecursionlimit(1000000) #括号中的值为递归深度
事实上并不能完全解决,太多还是会程序崩溃的。
2、所谓的尾递归
import numpy as np def getPi(n,m):
if n == 0:
return m+np.power(-1,n)*(1.0/(2*n+1))
else:
return getPi(n-1,m+np.power(-1,n)*(1.0/(2*n+1))) print 4*getPi(100,0)
尾递归参考:https://www.cnblogs.com/hello--the-world/archive/2012/07/19/2599003.html
尾递归的写法就是将操作的值作为参数传递,事实上,python并不支持尾递归的优化!而且对递归的次数有限制,当递归深度超过1000时,会抛出异常。
故对于继续研究突破递归次数的话,虽然有高手找到解决办法,并没有太大意义。
3、利用迭代的方式,而不是使用递归(譬如,reduce)
import numpy as np s = reduce(lambda x,n:x+np.power(-1,n)*(1.0/(2*n+1)),[np.power(-1,0)*(1.0/(2*0+1))]+range(1,100000))
print 4*s s = reduce(lambda x,n:x+np.power(-1,n)*(1.0/(2*n+1)) if x>0 else np.power(-1,x)*(1.0/(2*x+1))+np.power(-1,n)*(1.0/(2*n+1)),\
range(0,100000))
print 4*s
可以看到,利用reduce函数是处理这类问题的比较好的办法。用一句话总结:
普通程序员用迭代,天才程序员用递归!
python中的递归问题,求圆周率的更多相关文章
- Python中利用进度条求圆周率
从祖冲之到现在,圆周率的发展越来越丰富,求法也是越来越快其中: 1.求圆周率的方法: (1)蒙特卡罗法 这是基于“随机数”的算法,通过计算落在单位圆内的点与正方形内的比值来求圆周率PI. 如果一共投入 ...
- python中的递归
python中的递归 关注公众号"轻松学编程"了解更多. 文章更改后地址:传送门 间接或直接调用自身的函数被称为递归函数. 间接: def func(): otherfunc() ...
- Python中解决递归限制的问题
在做某些算法时,使用递归会出现类似下面的报错: RuntimeError: maximum recursion depth exceeded python默认的递归深度是很有限的,大概是900多的样子 ...
- python中使用递归实现反转链表
反转链表一般有两种实现方式,一种是循环,另外一种是递归,前几天做了一个作业,用到这东西了. 这里就做个记录,方便以后温习. 递归的方法: class Node: def __init__(self,i ...
- python中的递归小实例
#1.n! def fact(n): if n == 0: return 1 else: return n*fact(n-1)print(fact(10)) #2.斐波那契数列F(n)=F(n-1)+ ...
- Python中使用递归输出嵌套列表并转化为大写
- JS中的递归
递归基础 递归的概念 在程序中函数直接或间接调用自己 直接调用自己 简介调用自己 跳出结构,有了跳出才有结果 递归的思想 递归的调用,最终还是要转换为自己这个函数 如果有个函数foo,如果他是递归 ...
- python中的归并排序
本来在博客上看到用python写的归并排序的程序,然后自己跟着他写了一下,结果发现是错的,不得不自己操作.而自己对python不是非常了解所以就变百度边写,最终在花了半个小时之后就写好了. def m ...
- python中的迭代与递归
遇到一个情况,需要进行递归操作,但是呢递归次数非常大,有一万多次.先不说一万多次递归,原来的测试代码是java的,没装jdk和编译环境,还是用python吧 先看下原本的java代码: public ...
随机推荐
- 深入理解KS
一.概述 KS(Kolmogorov-Smirnov)评价指标,通过衡量好坏样本累计分布之间的差值,来评估模型的风险区分能力. KS.AUC.PR曲线对比: 1)ks和AUC一样,都是利用TPR.FP ...
- Html5使用history对象history.pushState()和history.replaceState()方法添加和修改浏览历史记录
根据网上参考自己做个笔记:参考网址:http://javascript.ruanyifeng.com/bom/history.html history.pushState() HTML5为histor ...
- gitHub 迁移到gitlab上
GitHub 迁移到 GitLab 上 第一步在github上生成 token 地址 https://blog.csdn.net/u014175572/article/details/55510825 ...
- CSS锚伪类顺序需注意的几点
CSS锚伪类有以下几种: a:link{color:pink} /*未访问的链接*/ a:visited{color:red} /*已访问的链接*/ a:hover{color:blue} /*鼠标移 ...
- linux系统iostat命令详解
iostat -k 3 5 (以KB为单位,每3秒统计一次,共统计5次) • avg-cpu: 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值 %user 用户空 ...
- mysql -> 索引_07
索引与sql语句优化 压力测试对比
- 缓存数据库-redis数据类型和操作(sorted set)
一:Redis 有序集合(sorted set) Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员. 不同的是每个元素都会关联一个double类型的分数.redis正是 ...
- java基础52 编码与解码
1.解码与编码的含义 编码:把看得懂的字符变成看不懂的码值,这个过程就叫编码 解码:根据码值查到相对应的字符,我们把这个过程就叫解码 注意:编码与解码时,我们一般使用统一的码表,否则非常容易出现 ...
- 详解MySQL大表优化方案
单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的.而事实上很多时 ...
- Trie树子节点快速获取法
今天做了一道leetcode上关于字典树的题:https://leetcode.com/problems/word-search-ii/#/description 一开始坚持不看别人的思路,完全自己写 ...