K2 4.7 升级 数据库排序规则更改
介绍
在过去,K2没有指定安装过程中要在其数据库上使用的标准排序规则。然而,现在K2引入了标准排序规则,以便在之后使用(如果我没有错的话,它是在4.7)。
因此, 问题出现在数据库的排序规则不是Latin1_General_CI_AS的情况,当您移动到新的 SQL server 并将默认值设置为Latin1_General_CI_AS时, 数据库将会不可用,表列、视图和用户定义表等主要组件都将受到影响。对于这些主要组件, 诸如存储过程、索引、函数等的子组件都受到了影响。
因此, 本文将指导您更改列排序规则。
注意: 这是根据 K2 4.7 数据库迁移记录的。
目标受众
您必须了解SQL Server、K2。
现在开始
规则与规则
排序规则只适用于某些列,这些列是NVARCHAR、VARCHAR和更多的文本列。所以我们必须关注这些列来改变排序规则。
要更改列的排序规则,我们必须遵守几个规则。这些是我遇到的规则:
- 列不能被索引(也适用于主键、外键和约束键)。
- 必须删除计算列(不能更改计算列排序规则)
- 必须删除用户定义的表(不能直接更改列)
备份
开始之前必须做数据库备份!
建议创建2个文件夹,命名为Drop和Create。脚本实际上是被隔离的,因为我们将对我们将执行什么以及我们应该运行哪个序列有一个更清晰的描述。也就是说,如果你对脚本有信心,你可以把它们组合在一起。(请注意,这实际上是一个非常巨大的脚本,如果你把它们全部结合起来)
生成脚本
以下是本练习之前需要准备的脚本列表:
- 删除索引、PK、FK、CK
- 删除计算列
- 删除存储过程、视图、用户定义的表和函数
- 创建索引、PK、FK、CK
- 创建计算列
- 创建存储过程、视图、用户定义的表和函数
- 更改列排序规则
供参考, 生成脚本的顺序将与下面的指南不一样, 因此只需根据步骤生成它, 我们就会看到最终的结果。
使用SQL Management Studio生成脚本
首先, 我们将生成以下内容的删除和创建脚本:
- 删除 SP、视图、函数和用户定义表的脚本
- 为函数、视图和用户定义的表创建脚本
- 为 SP 创建脚本
这些脚本都会通过SQL Management Studio来生成。
生成删除脚本
- 打开
SQL Management Studio - 转到 K2 数据库 > 右键单击 > 任务 > 生成脚本
- 选择视图、SP、用户定义的函数和用户定义的表类型, 然后单击 "下一步"
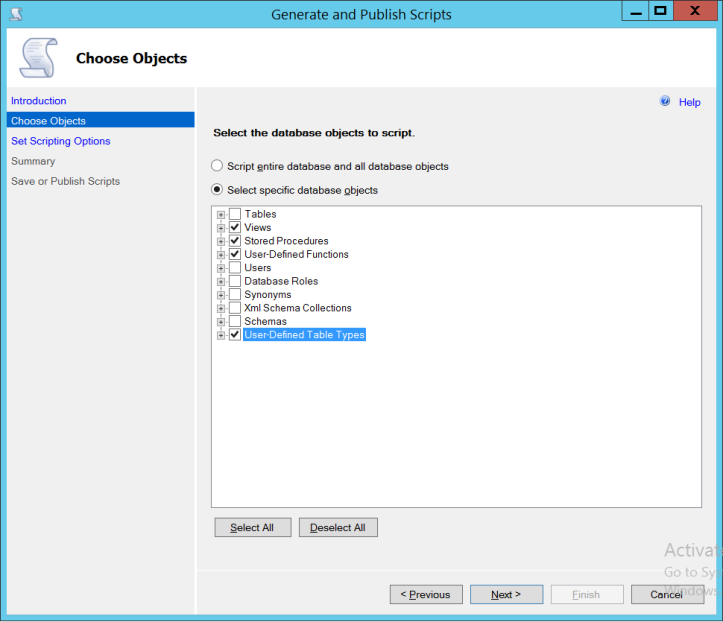
- 单击 "高级" 按钮, 选择
Script Drop选项

- 完成后, 生成脚本。将其保存在
Drop文件夹中并命名为6. Drop All SP View Fn UDT.sql
生成函数、视图和用户定义的表创建脚本
- 按照上面的步骤操作, 但只选择视图、用户定义的函数和用户定义的表类型
- 在高级中,把之前修改为
Script Drop选项,在这里应该选择Script Create - 完成后, 生成脚本。将其保存在
Create文件夹中并命名为3. Create View Fn UDT.sql
生成存储过程创建脚本
- 按照上面的步骤操作, 但只选择存储过程
- 在高级中,把之前修改为
Script Drop选项,在这里应该选择Script Create - 完成后, 生成脚本。将其保存在
Create文件夹中并命名为5. Create SP.sql
现在我们已经生成三个脚本了,分别是:
6. Drop All SP View Fn UDT.sql3. Create View Fn UDT.sql5. Create SP.sql
生成其它脚本
生成脚本-删除和创建
这是一个繁琐的部分, 您需要生成其余的脚本。
下载完上述脚本后, 可以执行脚本并按文件名保存。步骤如下:
- 打开
1. Drop FK.doc文档文件, 复制内容, 粘贴到SQL Management studio - 确保您在 K2 数据库上并执行它

- 一旦执行, 该语句将生成到消息框 (以绿色如上所述)。复制消息框内的文本,把它保存为
sql文件(.sql)。 - 包含
Drop文本的文件名, 请将其保存在Drop文件夹中。包含Create文本的文件名, 请将其保存在Create文件夹中。
生成脚本–更改列排序规则
这有点复杂, 在生成脚本后需要进行一些更改。请下载2. Alter Collation。
- 打开
2. Alter Collation.doc文件, 复制内容, 粘贴到SQL Management studio - 确认归类名称参数 (@CollationName nvarchar (255)) 是正确的值。(这应该是要更改的排序规则名称)
- 确保您在 K2 数据库上并执行它
- 一旦执行, 该语句将生成到消息框中。复制消息框内的文本,把它保存为
sql文件(.sql)。 - 找到以下四个句子并注释/删除:
- ALTER TABLE [Identity].[Identity] ALTER COLUMN [DisplayName] nvarchar(448) COLLATE…
- ALTER TABLE [Identity].[Identity] ALTER COLUMN [Email] nvarchar(128) COLLATE…
- ALTER TABLE [SmartBroker].[SmartObject] ALTER COLUMN [Name_XML] nvarchar(450) COLLATE…
- ALTER TABLE [SmartBroker].[SmartObject] ALTER COLUMN [DisplayName_XML] nvarchar(450) COLLATE…
- 将其保存在
Create文件夹中。
在4.7 中, 注释的四语句实际上是表中的四个计算列。稍后将在另一个脚本中处理此问题。
标准脚本
我将提供3个脚本的其余部分,这将是这个练习所需要的。
- Update Database Collation
要用.sql扩展保存到Create文件夹中,确保K2数据库名称正确。 - Create Column
使用.sql扩展将其保存到Create文件夹中。请注意,列在4.7测试,这可能是不同的其他版本。 - Drop Columns
使用SQL扩展将其保存到Drop文件夹中。请注意,在4.7中对列进行测试,这可能与其他版本不同。
文件摘要
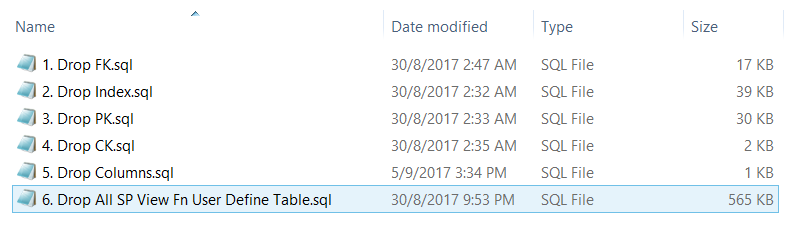
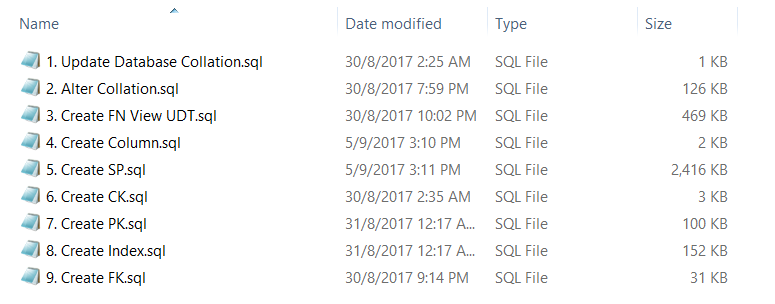
通过以上, 你应该有下面的:
Drop文件夹:
Create文件夹:
执行脚本
根据文件命名, 您将基于从1开始的序列执行,先从Drop文件夹开始, 然后再执行Create文件夹脚本。
执行完成后, 受影响的列应更新到排序规则,通过检查列属性进行快速检查。
希望这篇文章为您提供帮助。
其他
虽然本文在K2数据库中,但当您更改其他数据库的排序规则时,也可以使用一些脚本,你只需要在操作过程中注意几个方面(计算列、函数等)。
K2 4.7 升级 数据库排序规则更改的更多相关文章
- 数据库排序规则的冲突(理解collate Chinese_PRC_CI_AS)
之前碰到了数据库排序规则冲突问题,即百度或者 Google 的老话题: “ 无法解决 equal to 操作中‘ sql_latin1_general_cp1_ci_as ’和‘ chinese_pr ...
- SqlServer nvarchar中的中文字符匹配,更改SqlServer实例和数据库排序规则的办法
我们都知道在SqlServer中的nvarchar类型可以完美的存储诸如中文这种unicode字符,但是我们会发现有时候查询语句去查询nvarchar列的时候查不出来. 为什么nvarchar类型有时 ...
- mysql 数据库排序规则
MySQL中的排序规则.在新建MySQL数据库或表的时候经常会选择字符集和排序规则.数据库用的字符集大家都知道是怎么回事,那排序规则是什么呢? 排序规则:是指对指定字符集下不同字符的比较规则.其特征有 ...
- 【mysql】mysql创建数据库,基字符集 和 数据库排序规则 的对比选择
1.一般选择utf8.下面介绍一下utf8与utfmb4的区别. utf8mb4兼容utf8,且比utf8能表示更多的字符.至于什么时候用,看你的做什么项目了,到https://www.cnblogs ...
- 修改SQL Service数据库排序规则
修改数据库 alter database KidsPang COLLATE Chinese_PRC_CI_AS 修改表中字段ALTER TABLE [Member] ALTER COL ...
- 关于mysql创建数据库,基字符集 和 数据库排序规则 的对比选择
1.一般选择utf8.下面介绍一下utf8与utfmb4的区别. utf8mb4兼容utf8,且比utf8能表示更多的字符.至于什么时候用,看你的做什么项目了,unicode编码区从1 - 126就属 ...
- 修改sqlserver的数据库排序规则语句
alter database SOETMS collate Chinese_PRC_CI_AS
- MS SQL 排序规则总结
排序规则术语 什么是排序规则呢? 排序规则是根据特定语言和区域设置标准指定对字符串数据进行排序和比较的规则.SQL Server 支持在单个数据库中存储具有不同排序规则的对象.MSDN解 ...
- SQL 排序规则问题
http://blog.csdn.net/delphigbg/article/details/12744807 MSSQL排序规则总结 什么是排序规则呢? 排序规则根据特定语言和区域设置标准指定对 ...
随机推荐
- centos 快速安装wordpress
1.两种方式得到Wordpress 首先你可以去wordpress官方网站看下最新的wordpress的下载地址多少.比如wordpress 3.9.1的下载地址是: http://cn.wordpr ...
- 【代码笔记】iOS-JASidePanelsDemo(侧滑)
一,效果图. 二,工程图. 三,代码. AppDelegate.h #import <UIKit/UIKit.h> @class JASidePanelController; @inter ...
- p2p项目工具类
1.用于存放当前用户的上下文UserContext package com.xmg.p2p.base.util; import javax.servlet.http.HttpSession; impo ...
- error MSB3552: Resource file "**/*.resx" cannot be found. [/ConsoleApp1.csproj]
问题场景: 练习在docker下操作netcore,镜像为centos7,安装完netcore sdk 2.2后,执行操作: dotnet new consoledotnet run 出现报错: /u ...
- webpack HMR是如何工作的?
https://github.com/webpack/docs/wiki/hot-module-replacement-with-webpack https://www.jianshu.com/p/9 ...
- web assembly是什么,能干什么
web assembly混合javascript和另外底层语言编译的模块,共同运行.将js的高级,易用及c/c++的高效底层优势结合起来. 最可能的用处是提供一种可行的方法将原来的c/c++应用por ...
- [C# | XML] XML 反序列化解析错误:<xml xmlns=''> was not expected. 附通用XML到类解析方法
使用 XML 反化时出现错误: public static TResult GetObjectFromXml<TResult>(string xmlString) { TResult re ...
- C#下使用XmlDocument详解
XML在开发中作为文件存储格式.数据交换的协议用的非常普遍,各个编程语言有都支持.W3C也制定了XML DOM的标准.在这里主要介绍下.Net中的XmlDocument,包括xml读取和写入等功能.一 ...
- Asp.net单点登录解决方案
原文出处:http://www.cnblogs.com/wu-jian 主站:Passport集中验证服务器,DEMO中为:http://www.passport.com/ 分站:http://www ...
- 3 个简单、优秀的 Linux 网络监视器
作者: Carla Schroder 译者: LCTT geekpi 用 iftop.Nethogs 和 vnstat 了解更多关于你的网络连接. 你可以通过这三个 Linux 网络命令,了解有关你网 ...