抛弃模板,一种Prompt Learning用于命名实体识别任务的新范式
原创作者 | 王翔
论文名称:
Template-free Prompt Tuning for Few-shot NER
文献链接:
https://arxiv.org/abs/2109.13532
01 前言
1.论文的相关背景
Prompt Learning通过设计一组合适的prompt将下游任务的输入输出形式重构成预训练任务中的形式,充分利用预训练阶段学习的信息,减少训练模型对大规模标注数据集的需求。
例如对于用户评论的情感分析任务:判断用户评论的“交通太不方便了。”这句话蕴含的情感是“正面”还是“负面”。原有的处理范式是将其建模成一个文本分类问题,输入“交通太不方便了。”,输出“正面”或者 “负面”。
但如果使用Prompt Learning范式,则会将输入重构成“交通太不方便了。感觉很“[MASK]”,输出“好”或者“差”。
Prompt Learning借助合适的prompt减少了预训练和微调之间的差异,进而使得模型在少量的样本上进行微调,即可取得不错的效果,因此受到大量专家学者的关注,被誉为自然语言处理的第四范式。
命名实体识别是指识别文本中具有特定意义的实体,主要包括人名、地名、 机构名、专有名词等。
目前基于深度学习的命名实体识别方法已经取得了较高的识别精度,但由于深度学习模型依赖于大量的标注语料,因此在缺少大规模标注数据的垂直领域很难取得较好的效果。
针对少样本命名实体识别问题,常规的方案是基于相似性的度量方法,但该方法无法利用模型参数中的知识进行迁移。
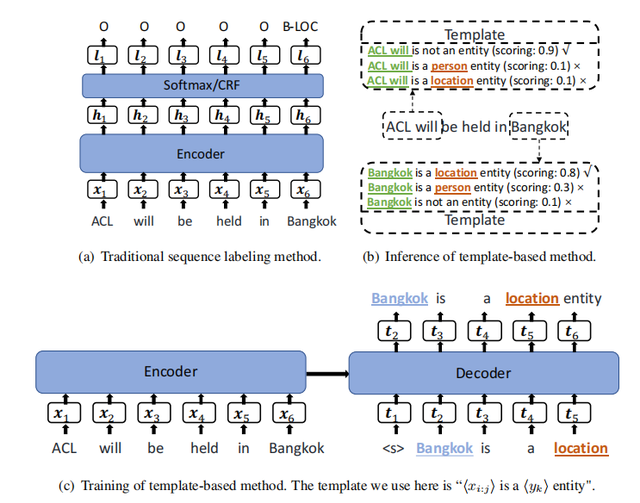
为了解决该问题,如下图所示的TemplateNER引入Prompt Learning通过人工设计的实体模板(<候选实体> is a <实体类型> entity)和非实体模板(<候选实体> is not a named entity)将命名实体识别问题建模成seq2seq框架下的语言模型打分任务,具体过程如下图所示。
TemplateNER在跨域和少样本场景下显著优于传统的序列标记方法和基于距离的少样本NER方法,但TemplateNER在生成候选实体时需要使用n-grams方法进行枚举,因此存在严重的效率问题。
2. 论文主要解决的问题
TemplateNER等基于Prompt Learning命名实体识别模型在识别效率上的问题
3. 论文的主要创新和贡献
● 提出了一种少样本场景下无模板的基于Prompt Learning的命名实体识别算法
● 舍弃了使用n-grams方法生成候选实体的思路,进而解决了TemplateNER等基于Prompt Learning命名实体识别模型的效率问题
02 论文摘要
Prompt Learning已被广泛应用于句子级自然语言处理任务中,但其在命名实体识别这类字符级的标记任务上取得的进展却相当有限。
TemplateNER通过n-grams方法枚举所有的潜在实体构建prompt进行命名实体识别任务,使得Prompt Learning得以应用于命名实体识别任务,但该构建方法容易产生大量的冗余数据,影响模型的效率。
针对上述问题,本文放弃了常规的prompt构建方法,采用预训练任务中的掩码预测任务的形式,将命名实体识别任务转化成将实体位置的词预测为选定的标签词的任务。
同时,为了标签词可以适配预训练语言模型的分布,本文提供了四种搜索适配模型的标签词的方法。
实验结果表明,在少样本场景下,本文方法优于直接使用BERT进行命名实体识别和TemplateNER。此外,在解码速度方面该方法比TemplateNER快1930.12倍。
03 论文模型
3.1 Entity-Oriented LM Fine-tuning
为了解决TemplateNER存在的效率问题,论文提出了一种Entity-Oriented LM(EntLM)微调方法,整体形式与图(a)所示的传统序列标注任务范式一致,不同的是,传统的序列标注任务的输出是输入句子中每个字符所对应的实体类型标签,EntLM则是输出的非实体部分同输入字符,实体部分为预设的最能代表该实体类型的字符。
如下图(b)所示,输入为`Obama was born in America`,其中`Obama `是实体类型标签为`PER`(人物)的实体,`America`是实体类型标签为`LOC`(地名)的实体,预设最能代表`PER`类型的字符是`John`,最能代表`LOC`类型的字符是`Australia`,则`was born in`所对应的输出为`was born in`,`Obama `所对应的输出为`John`,`America`所对应的输出为`Australia`。
与图(c)所示的TemplateNER需要针对实体类型和候选实体构建不同的模板进行输入相比,EntLM的实体识别过程仅需要一次前向计算即可完成,大大减少了冗余计算,提高了算法识别的效率。
至此,论文已经解决了TemplateNER等基于Prompt Learning命名实体识别模型的效率问题,但同时也延伸出了新的问题,即如何选定代表实体类型的字符(论文将该类字符成为label word)。

3.2 Label Word Engineering
EntLM面对的是少样本场景,因此如果只使用训练数据来生成label word,不论是使用何种算法都会面临label word不置信的问题。
为了解决上述问题,论文采用了BOND[1]中远程监督生成伪标签数据的方法(尽管论文中提到该方法引用自BOND,但其实该部分就是一个普通的远程监督生成伪标签数据的过程,并未实际使用BOND算法),借助外部知识库为数据提供标签,该方法的假设便是如果文本中的字符串包含在预定义的实体字典中,则该字符串可能是一个实体。
远程监督生成伪标签的方法存在噪声标注的问题,但EntLM使用远程监督的目标是为了找到相对置信的label word,而不是将其直接作为标签使用,因此,噪声标注对其影响相对较小。
生成伪标签数据后,论文提供了四种方法用来选定label word。
●Searching with data distribution (Data search)
每类实体类型均选择出现频率最高的字符作为label word,例如在伪标签数据中属于`LOC`类型的字符仅有`America`和`Australia`,其中`America`出现的频率为5,`Australia`出现的频率为6,则选择`Australia`作为label word。
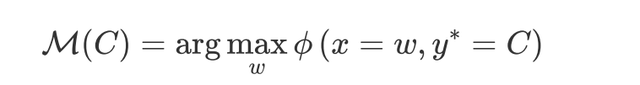
●Searching with LM output distribution (LM search)
使用预训练模型对伪标签数据中的每个样本进行掩码预测,获取模型在每个实体位置上的预测分布,选择每个实体位置预测TOPK的字符进行频率统计。
例如,对`Obama was born in America`进行掩码预测,`America`位置对应的预测TOP3为`America`、`Australia`和`Beijing`,若选择TOP2进行频率统计,则`America`作为`LOC`类型出现的频率加1,`Australia`作为`LOC`类型出现的频率加1。
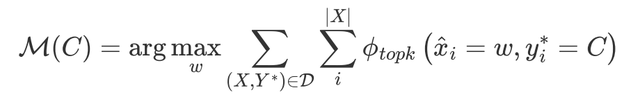
●Searching with both data & LM output distribution (Data&LM seach)
综合上述两个方法,使用两种频率的乘积作为最终的频率
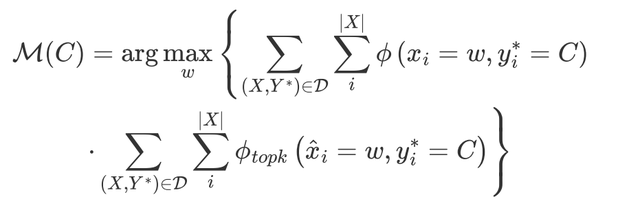
●Virtual label word (Virtual)
选择实体类型中出现频率TOPK的字符的词向量(通过预训练模型生成)进行平均作为代表该类实体类型的向量,进而生成虚拟label word。
例如,`LOC`类型中出现频率TOP2的字符分别为`America`和`Australia`,将这两个字符的词向量进行平均,生成的新词向量记为`LOC`的词向量。
生成`LOC`的词向量后,将`LOC`和`LOC`的词向量加入到预训练模型的词典。
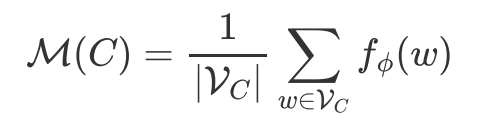
3.3 Removing conflict label words
因为存在一个高频词出现在多个实体类型中的情况,因此论文设置了一个阈值Th来判断高频词是否能属于某一类实体:
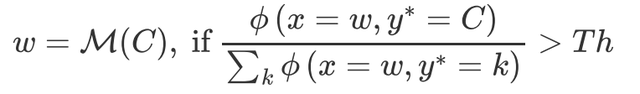
04 论文实验
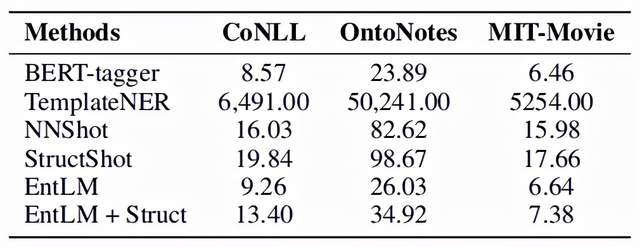
EntLM主要在`CoNLL2003`、`OntoNotes 5.0`和`MIT-Movie`上进行实验,由于主要是验证模型对于文本中出现的实体的识别能力,因此删去了OntoNotes 5.0数据集中值、数字、时间和日期等实体类型。
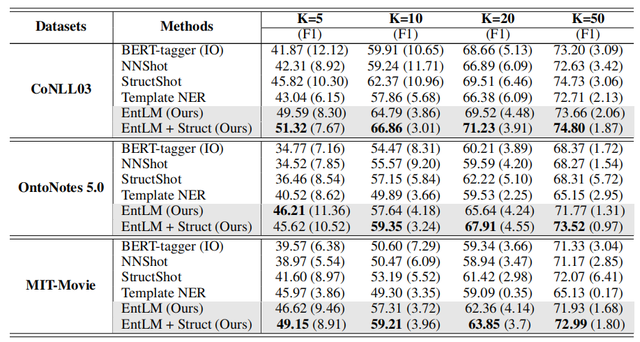
评价指标采用了F1-score。实验结果如下图,其中BERT-tagger是直接使用BERT微调的模型,NNShot和StructShot是基于相似性的度量方法,EntLM+Struct则是在EntLM的基础上使用维特比算法对输出进行解码[2],可以看出EntLM在三个数据集上都取得了不错的效果。
论文对EntLM的效率进行了实验,由于EntLM摒弃了人工设计模板和使用n-grams方法生成候选实体的做法,因此EntLM在推理速度上相比于TemplateNER有明显的优势:
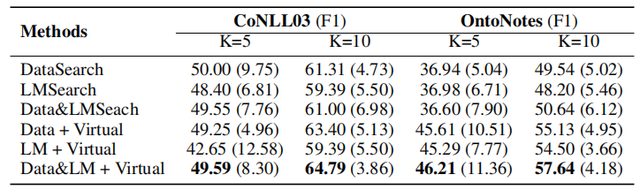
此外,论文还针对不同label word搜索方法对EntLM的影响进行了实验,结果如下图所示,可以发现将Data search、LM search和Virtual结合使用可以获得最佳的效果。
参考文献
[1] [BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision](https://arxiv.org/abs/2006.15509)
[2] [Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning](https://aclanthology.org/2020.emnlp-main.516.pdf)
抛弃模板,一种Prompt Learning用于命名实体识别任务的新范式的更多相关文章
- pytorch实现BiLSTM+CRF用于NER(命名实体识别)
pytorch实现BiLSTM+CRF用于NER(命名实体识别)在写这篇博客之前,我看了网上关于pytorch,BiLstm+CRF的实现,都是一个版本(对pytorch教程的翻译), 翻译得一点质量 ...
- DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
三个月之前 NLP 课程结课,我们做的是命名实体识别的实验.在MSRA的简体中文NER语料(我是从这里下载的,非官方出品,可能不是SIGHAN 2006 Bakeoff-3评测所使用的原版语料)上训练 ...
- NLP入门(八)使用CRF++实现命名实体识别(NER)
CRF与NER简介 CRF,英文全称为conditional random field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机 ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
- 用CRF做命名实体识别(一)
用CRF做命名实体识别(二) 用CRF做命名实体识别(三) 用BILSTM-CRF做命名实体识别 博客园的markdown格式可能不太方便看,也欢迎大家去我的简书里看 摘要 本文主要讲述了关于人民日报 ...
- 『深度应用』NLP命名实体识别(NER)开源实战教程
近几年来,基于神经网络的深度学习方法在计算机视觉.语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展.在NLP的关键性基础任务—命名实体识别(Named Entity Recogni ...
- 用深度学习做命名实体识别(七)-CRF介绍
还记得之前介绍过的命名实体识别系列文章吗,可以从句子中提取出人名.地址.公司等实体字段,当时只是简单提到了BERT+CRF模型,BERT已经在上一篇文章中介绍过了,本文将对CRF做一个基本的介绍.本文 ...
- 【NER】对命名实体识别(槽位填充)的一些认识
命名实体识别 1. 问题定义 广义的命名实体识别是指识别出待处理文本中三大类(实体类.时间类和数字类).七小类(人名.机构名.地名.日期.货币和百分比)命名实体.但实际应用中不只是识别上述所说的实体类 ...
随机推荐
- Servlet-请求的分发处理
1,HelloServlet类中 2,a.html中
- nginx配置支持websocket
前两天折腾了下socketio,部署完发现通过nginx代理之后前端的socket无法和后端通信了,于是暴查一通,最后解决问题: location / { proxy_pass http://127. ...
- python12day
昨日回顾 可迭代对象: 可以更新迭代的实实在在的值. 内部含有'__iter__'方法. str.tuple.dict.set.range 优点:操作方法多,灵活直观 缺点:占用内存. 迭代器: 可以 ...
- makefile 编译多个目标
1.静态库libtools.a源码 libtools.h #ifndef tools_h_ #define tools_h_ int sub(int x,int y); int mul(int x,i ...
- Understanding C++ Modules In C++20 (2)
Compiling evironment: linux (ubuntu 16.04)+ gcc-10.2. The post will focus on using export,import,vis ...
- c++14新特性
1.函数返回值类型推导 c++14对函数返回类型推导规则做了优化: auto func(int i) { //C++11编译非法,c++14支持auto返回值类型推导 return i; } int ...
- C3P0数据库连接池数据库插入中文乱码问题解决
问题描述 近期修改一个学生信息管理的JavaWeb项目,其数据库连接池使用了C3P0.在实际测试时,发现在学生信息模块添加中文学生信息会在数据库(MySQL)出现中文乱码问题. 如图所示: 问题分析 ...
- JAVA多线程学习六-守护线程
java中的守护程序线程是一个服务提供程序线程,它为用户线程提供服务. 它的生命依赖于用户线程,即当所有用户线程都死掉时,JVM会自动终止该线程. 有许多java守护程序线程自动运行,例如 gc,fi ...
- MySQL server has gone away 异常
原因 一种可能是发送的SQL语句太长,以致超过了max_allowed_packet的大小,如果是这种原因,你只要修改my.cnf,加大max_allowed_packet的值即可. 还有一种可能是因 ...
- Foundation框架介绍
1.Foundation框架介绍 什么是框架? 众多功能\API的集合 框架是由许多类.方法.函数.文档按照一定的逻辑组织起来的集合,以便使研发程序变得更容易,在OS X下的Mac操作系统中大约有80 ...