LeetCode随缘刷题之Java经典面试题将一个字符串数组进行分组输出,每组中的字符串都由相同的字符组成
今天给大家分享一个Java经典的面试题,题目是这样的:
本题是LeetCode题库中的49题。
将一个字符串数组进行分组输出,每组中的字符串都由相同的字符组成
举个例子:输入[“eat”,“tea”,“tan”,“ate”,“nat”,“bat”]
输出[[“ate”,“eat”,“tea”],[“nat”,“tan”],[“bat”]]
刚见到这个题,我的第一反应是正则。通过正则表达式加上循环,来筛选判断两个字母是否全部由相同字符组成。结果发现并没有想象中的简单。
于是我转换思路,想到用数组的方式来求,即将每个元素都转化为char类型数组,先判断长度是否相等。然后比较,也就是下面StringArrays类中的compareReverse方法。
但是这样效率实在不高,而且还要循环一次。因为会有包含关系的出现(比如abc就包含abb),这就需要我们再反向调用一次,这样才得到了最终方法compare。
后来我想到用排序也可以实现啊,将字符串拆分排序后再合并,如果两个字符串相同,那肯定都由相同的字符组成。于是就有了2.0版本compareNow:
package day_12_02.zuoye;
import java.util.Arrays;
/**
* @author soberw
*/
public class StringArrays {
/**
* 给定两个字符串,判定第二个串中的字符是否在第一个字符串中全部存在
* contains()当且仅当此字符串包含指定的char值序列时才返回true。
*
* @param a 第一个字符串
* @param b 第二个字符串
* @return boolean
*/
private boolean compareReverse(String a, String b) {
//记录次数
int count = 0;
char[] newB = b.toCharArray();
for (char bb : newB) {
if (a.contains(String.valueOf(bb))) {
count++;
}
}
//相等说明全部包含在内
if (count == a.length()) {
return true;
}
return false;
}
/**
* 对字符串排序
*
* @param str 字符串
* @return 排序后的
*/
private String sortString(String str) {
char[] s = str.toCharArray();
Arrays.sort(s);
return String.valueOf(s);
}
/**
* 判断两个字符串是否由相同字符组成,切长度相同
*
* @param m 第一个字符串
* @param n 第二个字符串
* @return boolean
*/
public boolean compare(String m, String n) {
if (m.length() != n.length()) {
return false;
}
//避免出现子包含情况
return compareReverse(m, n) && compareReverse(n, m);
}
/**
* 对compare方法的改进
*
* @param m 第一个字符串
* @param n 第二个字符串
* @return boolean
*/
public boolean compareNow(String m, String n) {
if (m.length() != n.length()) {
return false;
}
return sortString(m).equals(sortString(n));
}
}
想法实现一
解决了比较问题,于是迎来了第一次测试,一开始我只想到走二维数组来实现,加双重循环判断放入。
package day_12_02.zuoye;
import java.util.Arrays;
/**
* 对StringArrays的测试
*
* @author soberw
*/
public class SATest {
public static void main(String[] args) {
StringArrays sa = new StringArrays();
String[] str = {"eat", "tea", "tan", "ate", "nat", "bat"};
String[][] newStr = new String[str.length][str.length];
for (int i = 0; i < str.length; i++) {
for (int j = 0; j < str.length; j++) {
if (sa.compare(str[i], str[j])) {
newStr[i][j] = str[j];
}
}
}
for (String[] s : newStr) {
System.out.println(Arrays.toString(s));
}
}
}
结果是这样的 我直接凌乱。。。(虽然真的分好组了)

想法不成立。
其实原因很简单,数组局限性太多,必须指定长度,而且会有默认初始值null,当然最后可以去重得到最终结果。但是我实在是嫌麻烦(二维数组去重…)于是果断更换思路。
想法实现二
我们都知道数组是指定长度的,那有没有不指定长度的动态的呢?当然,Java给我们提供了很多,如set,map,list,vector等等。 目前我的想法是创建一个动态的二维数组,和一个临时数组。通过循环,先取出一个单词放在临时数组中,并将原数组该位置值变为null,然后拿临时数组的元素和原数组的所有非null元素比较(通过compareNow方法),匹配一个放入一个,并将原数组对应元素赋值为null,循环的最后将临时数组放入二维数组中,依次循环下去,直到原数组值全部变为null。
下面实施,我决定选用Vector来存放数据:
package day_12_02.zuoye;
import java.util.Arrays;
import java.util.List;
import java.util.Vector;
/**
* 对StringArrays的测试
*
* @author soberw
*/
public class StringArr {
public static void main(String[] args) {
StringArrays sa = new StringArrays();
//初始数组
Vector<String> v = new Vector<>(List.of("eat", "tea", "tan", "ate", "nat", "bat"));
//保存数据
Vector<Vector<String>> saveV = new Vector<>();
//暂存数组
Vector<String> ver = new Vector<>();
while (true) {
//开始时清空
ver.clear();
for (int j = 0; j < v.size(); j++) {
if (v.get(j) != null) {
ver.add(v.get(j));
v.set(j, null);
break;
}
}
if (ver.size() == 0) {
break;
}
for (int k = 0; k < v.size(); k++) {
if (v.get(k) != null) {
if (sa.compareNow(ver.get(0), v.get(k))) {
ver.add(v.get(k));
v.set(k, null);
}
}
}
System.out.println(ver);
saveV.add(ver);
}
System.out.println(Arrays.toString(saveV.toArray()));
}
}
运行结果:

这是怎么回事,为什么上面输出正确,最后却为空呢。想一想,我终于明白为什么了。saveV.add(ver);这段代码只是添加了ver变量的引用,也就是说ver和saveV的数据都在同一地址单元内。而我每次循环开始都ver.clear() 将ver内的数据清空,那么对应的saveV中的数据也被清空了。
那么如何解决呢,很简单,每次循环重新new一个数组就好了:
package day_12_02.zuoye;
import java.util.Arrays;
import java.util.List;
import java.util.Vector;
/**
* 对StringArrays的测试
*
* @author soberw
*/
public class StringArr {
public static void main(String[] args) {
StringArrays sa = new StringArrays();
//初始数组
Vector<String> v = new Vector<>(List.of("eat", "tea", "tan", "ate", "nat", "bat"));
//保存数据
Vector<Vector<String>> saveV = new Vector<>();
while (true) {
//暂存数组
Vector<String> ver = new Vector<>();
for (int j = 0; j < v.size(); j++) {
if (v.get(j) != null) {
ver.add(v.get(j));
v.set(j, null);
break;
}
}
if (ver.size() == 0) {
break;
}
for (int k = 0; k < v.size(); k++) {
if (v.get(k) != null) {
if (sa.compareNow(ver.get(0), v.get(k))) {
ver.add(v.get(k));
v.set(k, null);
}
}
}
System.out.println(ver);
saveV.add(ver);
}
System.out.println(Arrays.toString(saveV.toArray()));
}
}
结果完美找出:

想法成立。
想法实现三
那么这就是最好的解决方案了吗?我认为当然不是。虽然实现了但我觉得还是太麻烦。还要声明函数,还要加循环判断,还有反复声明数组存放,如果面试时这样写,先不说面试官看了直摇头,就这代码量和需要考虑的点,等你还在改bug呢,其他同学早就交卷了。。。
于是催生出了想法三:
充分利用集合的不重复性,先将愿数组所有元素字符排序,放入集合,这样集合就能筛选出所有重复的。
然后只需要把这个集合遍历一遍,与原数组所有元素比较,相同则放入一个临时集合中。最后统一保存在二维集合中去。
开始实施:
package day_12_02.zuoye;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
/**
* @author soberw
*/
public class StrArr {
/**
* 对字符串排序
*
* @param str 字符串
* @return 排序后的
*/
private static String sortStr(String str) {
char[] s = str.toCharArray();
Arrays.sort(s);
return String.valueOf(s);
}
public static void main(String[] args) {
//原始数组
String[] str = {"ate", "tae", "tan", "ant", "eat", "bat"};
//中间集合
Set<String> set = new HashSet<>();
//存放最终结果
Set<Set<String>> setLast = new HashSet<>();
for (int i = 0; i < str.length; i++) {
set.add(sortStr(str[i]));
}
for (String s : set) {
//暂存数据
Set<String> seter = new HashSet<>();
//排序后相等的元素放入临时集合
for (int i = 0; i < str.length; i++) {
if (s.equals(sortStr(str[i]))) {
seter.add(str[i]);
}
}
setLast.add(seter);
}
System.out.println(setLast);
}
}
运行结果:
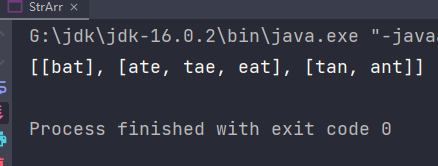
想法成立。
想法实现四
可以看到代码量惊人的减少了,但想法三中设置的中间集合让我灵光一现。我们都知道数组是通过索引下标来走的:0,1,2,3…索引是不可控的,我想着能不能控制索引,将索引的值改为将要判断的值呢?这样就不用通过中间集合了,可以直接通过索引值调用元素了。于是我想到了,Java给我们提供了Map,你可以理解为键值对的一种集合。
实现如下:
package day_12_02.zuoye;
import java.util.*;
/**
* @author soberw
*/
public class SATrue {
public static void main(String[] args) {
String[] strs = {"ate", "tae", "tan", "ant", "eat","bat"};
System.out.println(new SATrue().grouper(strs));
}
public List<List<String>> grouper(String[] strs) {
if (strs == null || strs.length == 0) {
return new ArrayList<>();
}
Arrays.sort(strs);
Map<String, List<String>> map = new HashMap<>();
for (String str : strs) {
char[] c = str.toCharArray();
Arrays.sort(c);
String sortedStr = String.valueOf(c);
if (!map.containsKey(sortedStr)) {
map.put(sortedStr, new ArrayList<>());
}
map.get(sortedStr).add(str);
}
return new ArrayList<>(map.values());
}
}
运行结果:
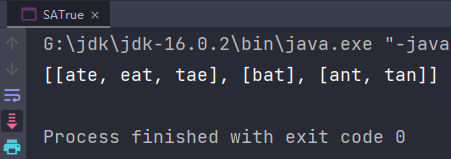
想法成立。
相比于想法三又简化了一步,这是我目前能够想到的最优解了。
一个看似简单的题目,实现起来却并不简单。刚开始我以为本题难点在于筛选出相同的字符组成的元素,结果等真正实现却发现,难点在于如何把它们表现在二维数组中,即如何分组显示。
如果你们有更好的想法,欢迎评论区留言。
LeetCode随缘刷题之Java经典面试题将一个字符串数组进行分组输出,每组中的字符串都由相同的字符组成的更多相关文章
- LeetCode随缘刷题之最短补全词
package leetcode.day_12_10; import org.junit.Test; /** * 给你一个字符串 licensePlate 和一个字符串数组 words ,请你找出并返 ...
- Leetcode随缘刷题之寻找两个正序数组的中位数
我一上来没读清题,想着这题这么简单,直接就上手写了: package leetcode.day_12_05; import java.util.ArrayList; import java.util. ...
- LeetCode随缘刷题之最长回文子串
这一题我用的相对比较笨的方法. 相对于大佬们用的动态规划法,比较复杂.但却更容易理解,我主要是通过记录下标来确定最长回文串的. package leetcode.day_12_06; /** * 给你 ...
- LeetCode随缘刷题之字符串转换整数
package leetcode.day_01_29; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * 请你 ...
- LeetCode随缘刷题之转化成小写字母
这道题应该是最简单的一道题了把,简直在侮辱我. package leetcode.day_12_12; /** * 709. 转换成小写字母 * 给你一个字符串 s ,将该字符串中的大写字母转换成相同 ...
- LeetCode随缘刷题之截断句子
这道题相对比较简单.正好最近学到StringBuilder就用了. package leetcode.day_12_06; /** * 句子 是一个单词列表,列表中的单词之间用单个空格隔开,且不存在前 ...
- LeetCode随缘刷题之无重复字符的最长子串
欢迎评论区交流. package leetcode.day_12_04; /** * 给定一个字符串 s ,请你找出其中不含有重复字符的最长子串的长度. * <p> * 示例1: * &l ...
- LeetCode随缘刷题之赎金信
欢迎评论区讨论. package leetcode.day_12_04; /** * 为了不在赎金信中暴露字迹,从杂志上搜索各个需要的字母,组成单词来表达意思. * * 给你一个赎金信 (ransom ...
- LeetCode随缘刷题之两数相加
逐步解释,有说错的地方欢迎指正. package leetcode.day_12_03; /** * 给你两个非空 的链表,表示两个非负的整数.它们每位数字都是按照逆序的方式存储的,并且每个节点只能存 ...
随机推荐
- Canvas原生API(纯CPU)计算并渲染三维图
Canvas原生API(纯CPU)计算并渲染三维图 前端工程师学图形学:Games101 第三次作业 利用Canvas画三维中的三角形并使用超采样实现抗锯齿 最终完成功能 Canvas 原生API实现 ...
- python使用String的Template进行参数动态替换
1.前言: 之前使用string的find(),从指定的param里面查找,是否包含了某个字符,有的话,使用replace进行替换,一个接口的param要替换的参数少的话,使用这种方式,的确可行,如果 ...
- Java8的stream用法整理
map 1 直接获取对象的值 this.categoryMapper.selectByIdList(ids).stream().map(Category::getName).collect(Colle ...
- js对象数组多字段排序
来源:js对象数组按照多个字段进行排序 一.数组排序 Array.sort()方法可以传入一个函数作为参数,然后依据该函数的逻辑,进行数组的排序. 一般用法:(数组元素从小大进行排序) var a = ...
- BitMap算法知识笔记以及在大数据方向的使用
概述 所谓的BitMap算法就是位图算法,简单说就是用一个bit位来标记某个元素所对应的value,而key即是该元素,由于BitMap使用了bit位来存储数据,因此可以大大节省存储空间,这是很常用的 ...
- DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | TENSORS
Tensor是一种特殊的数据结构,非常类似于数组和矩阵.在PyTorch中,我们使用tensor编码模型的输入和输出,以及模型的参数. Tensor类似于Numpy的数组,除了tensor可以在GPU ...
- 【小记录】解决链接libcufft_static.a库出现的错误
程序中使用了 cv::cuda::dft() 函数,需要在链接的时候使用libcufft_static.a这个库.链接出现大量类似错误:error: undefined reference to __ ...
- 安卓无法访问Azure服务器和微软API
Azure服务器保护机制限制移动端访问 必须使用移动app服务来转接api,才可以访问.
- gorm中的基本查询
检索单个对象 GORM 提供了 First.Take.Last 方法,以便从数据库中检索单个对象.当查询数据库时它添加了 LIMIT 1 条件 // 获取第一条记录(主键升序) db.First(&a ...
- 带你十天轻松搞定 Go 微服务系列(五)
序言 我们通过一个系列文章跟大家详细展示一个 go-zero 微服务示例,整个系列分十篇文章,目录结构如下: 环境搭建 服务拆分 用户服务 产品服务 订单服务(本文) 支付服务 RPC 服务 Auth ...