mysql 索引 零记
索引算法
二分查找法/折半查找法
伪算法 :
1. 前提,数据需要有序
2. 确定数据中间元素 K
3. 比如目标元素 A与K的大小
3.1 相等则找到
3.2 小于时在左区间
3.3 大于时在右区间
4. 重复以上过程,直到找到或遍历完所有数据
优点:比较次数少,查找速度快,总体性能好
缺点:要求数据有序,插入数据困难(因为有序,插入时要先找到位置)
二叉树
每个节点最多有两个子树
左节点永远小于右节点
最大层数为树的高度,无层数限制
下面文章有更详细的说明
https://www.jianshu.com/p/bf73c8d50dc2
平衡二叉树
当数据量大时,二叉树高度较大,查询复杂度上升,于是有了平衡二叉树,特点如下
左右两个子树的高度差的绝对值不超过1,依旧是二叉树
不满足上述条件时,会通过自旋,达到上述条件,故该二叉树不存在严重的数据倾斜现象,查询最坏/最好的时间复杂度都维持在O(logN)。
详细可参考
https://www.cnblogs.com/zhangbaochong/p/5164994.html
B树,平衡多叉树,又叫B-tree/B-树
一个结点的子树节点个数不限
可满足大量数据的读写,普遍运用于数据库、文件系统
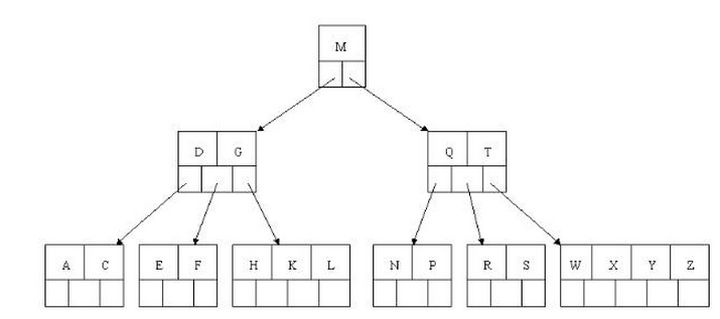
排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
有N个子结点的非叶子结点包含N-1个键值(索引节点),比如上图中DG所在结点有两个键值(D与G)、三个叶子结点
详细参考
https://zhuanlan.zhihu.com/p/27700617
B+树
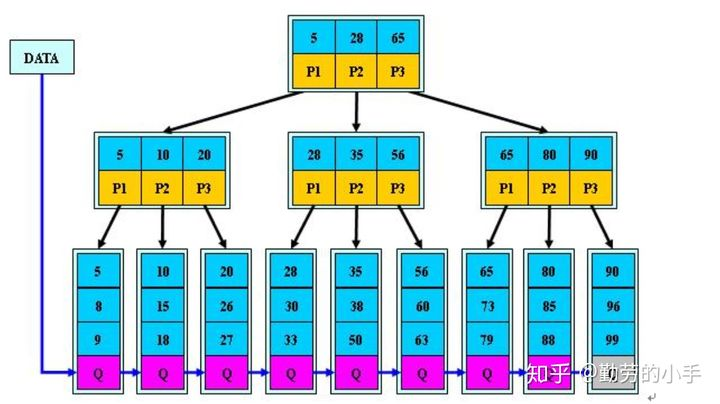
非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
所有数据都保存在叶子结点
B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
详细参考
https://my.oschina.net/u/4116286/blog/3107389
B*树
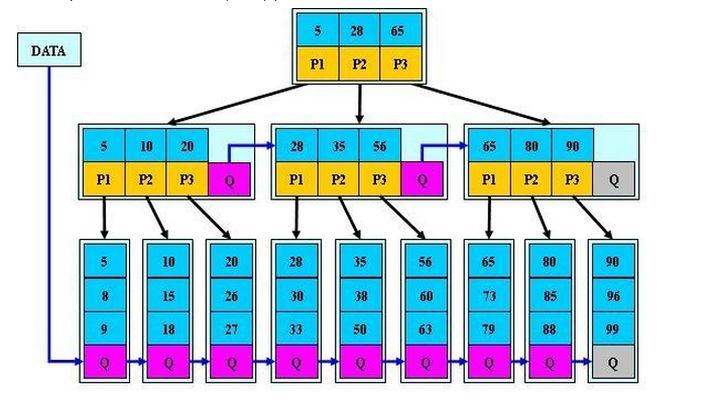
B*树是B+树的变种,相对于B+树他们的不同之处如下:
首先是关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b*树的初始化个数为(cei(2/3*m))
B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来;
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树额分解次数变得更少;
哈希索引/散列索引
mysql> select crc32(11);
+------------+
| crc32(11) |
+------------+
| 3596227959 |
+------------+
1 row in set (0.00 sec)
通过对键值key进行hash运算得到一个code,该code指向数据行;
innodb中不常用, NDB中使用
大量、唯一、等值查询,HASH索引效率高于B+Tree,原因是IO次数少,HASH索引一次就能找到数据,B+Tree需要2-3次
联合索引时,所有列必须同时出现,并且都是等值查询
HASH索引不支持范围、排序、模糊查询
HASH索引只能显式应用于HEAP/MEMORY/NDB表
在等值查询这一领域里,HASH算法优于B+Tree,综合性不如B+Tree
HASH索引与innodb内部的自应用HASH索引是两个概念
mysql 索引 零记的更多相关文章
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- mysql 索引2
/* 所有MySQL列类型可以被索引.根据存储引擎定义每个表的最大索引数和最大索引长度. 所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节.大多数存储引擎有更高的限制. 索引的存储类型 ...
- Mysql数据库知识-Mysql索引总结 mysql mysql数据库 mysql函数
mysql数据库知识-Mysql索引总结: 索引(Index)是帮助MySQL高效获取数据的数据结构. 下边是自己整理的资料与自己的学习总结,,做一个汇总. 一.真的有必要使用索引吗? 不是每一个性能 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- MySQL索引入门
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 索引分单列索引和组合索引.单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引. ...
- Mysql 索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
随机推荐
- Linux 系统分区方案 详细教程
简单分区方案 实际上,很多时候我们只需要分两个区:/和交换分区,日常使用基本不会有任何影响,甚至于交换分区对于现在的电脑来说都不是必要的,我们完全可以只分配一个根分区.linux只需要一个/根分区就可 ...
- 腾讯发布 K8s 多集群管理开源项目 Clusternet
11月4日,在腾讯数字生态大会上,腾讯宣布了云原生领域一项重磅开源进展-- K8s 多集群管理项目 Clusternet 正式开源. Clusternet 由腾讯联合多点生活.QQ音乐.富途证券.微众 ...
- Cookie、Session、localStorage、sessionStorage区别和用法
Cookie 在学习一个新知识点前,我们应该明白自己的学习目标,要带着疑问去学习,该小节须要了解 Cookies 什么是cookie,cookie的作用 cookie的工作机制,即cookie是运作流 ...
- appium环境搭建基于安卓(mac系统)
1.需要环境 JDK Python Andriod SDK Node.js Appium Appium-Python-Client Appium-doctor 2.安装jdk(我的版本是1.8) 下载 ...
- sqlalchemy flush commit
https://segmentfault.com/q/1010000000698181 flush 将sql发送到内存 commit 真正提交
- 前端---梳理 http 知识体系 2
为什么要有HTTPS HTTP 天生具有明文的特点,整个传输过程完全透明,任何人都能够在链路中截获.修改或者伪造请求 / 响应报文,数据不具有安全性.仅凭HTTP 自身是无法解决的,需要引入新的HTT ...
- 图片处理看这篇就完了「GitHub 热点速览 v.21.48」
作者:HelloGitHub-小鱼干 图像处理一直是个实用且热门的研究领域,而本周的 GitHub 项目则多个图像项目上榜.先是勉强和图像处理搭边的渲染引擎 Filament,它能渲染出效果极佳的 3 ...
- 使用 CSS 轻松实现一些高频出现的奇形怪状按钮
背景 在群里会有同学问相关的问题,怎么样使用 CSS 实现一个内切角按钮呢.怎么样实现一个带箭头的按钮呢? 本文基于一些高频出现在设计稿中的,使用 CSS 实现稍微有点难度和技巧性的按钮,讲解使用 C ...
- java Scanner类与String类
Scanner类的使用: 导入Scanner包,new Scanner对象,记得调用System.in参数,调用对应next方法实现键盘录入. import java.util.Arrays; i ...
- 【2020五校联考NOIP #7】伟大的卫国战争
题面传送门 题意: 数轴上有 \(n\) 个点,现在要在它们之间连 \(m\) 条边,第 \(i\) 条边连接 \(a_i,b_i\) 两个点. 现在你要钦定每条边连在数轴的上方还是下方,使得任意两条 ...