tidyverse生态链
library(tidyverse)
mpg
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy))
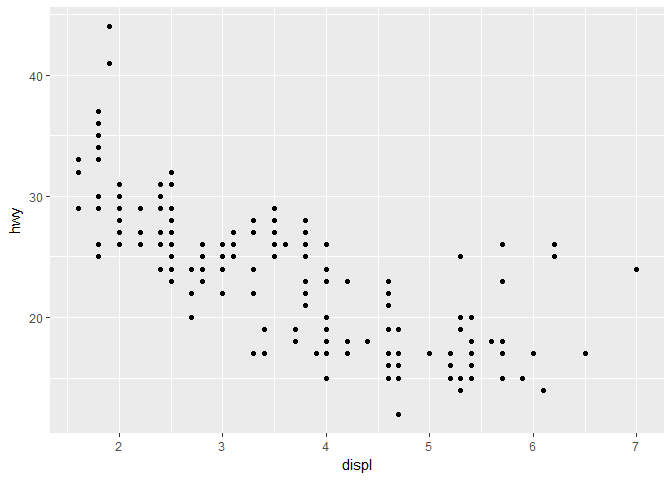
数据 : ggplot 的数据集必须是一个数据框,这里我们的数据是 mpg
图形属性映射:将数据变量映射到图形中,我们这里使用 aes(x = displ, y = hwy) 把 x 坐标映射到排气量,y 坐标映射到每公里耗油量
几何对象 : geom 代表几何对象,比如我们这里想画散点图,就用 geom_point 来生成散点图
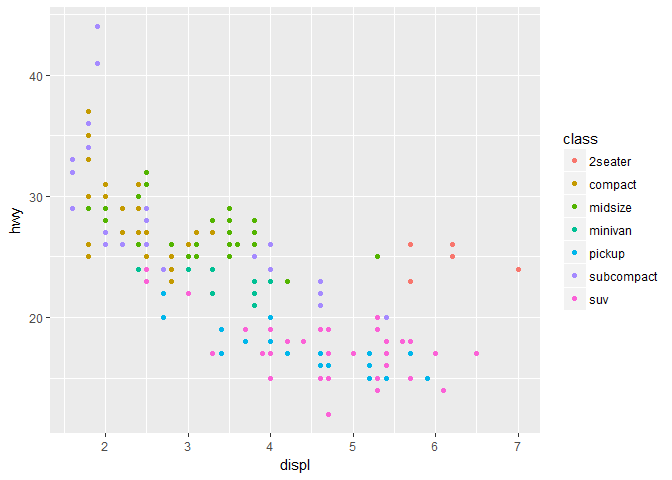
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = class))
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class)
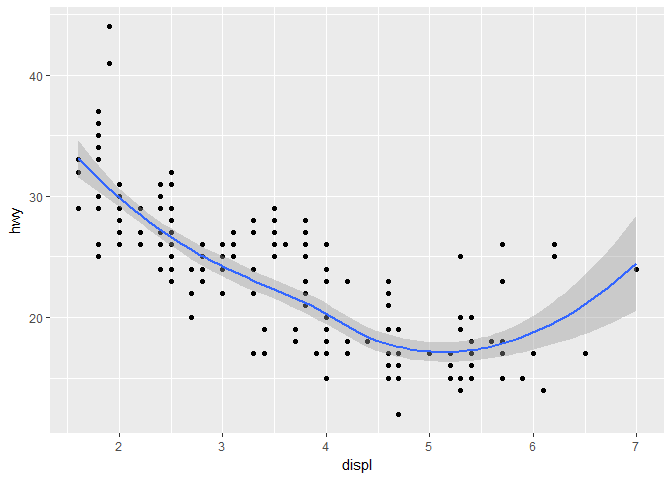
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
geom_smooth(mapping = aes(x = displ, y = hwy))
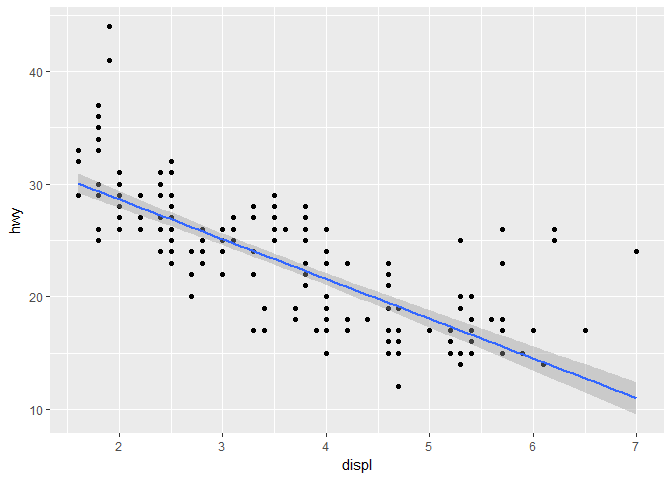
ggplot(mpg , aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth(method = "lm")
mpg %>% filter(displ >=5 , hwy < 20)
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy)
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy) %>% select(model)
mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ)
var(mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ))
mpg %>% group_by(class) %>% summarise(mean(displ) , mean(hwy))
tidyverse生态链的更多相关文章
- 运营或生态链没做好,APP质量再高有个鸟用(下)
上篇文章已经阐述了对于一款产品卖不卖作,事实上非常依赖于运营的打造和生态链的建立,这里能够解释为什么很多优秀的游戏产品功底非常好,但開始并不卖作,仅仅有碰到一家肯出力推的渠道游戏才迅速火了起来.这是不 ...
- 浅谈API网关(API Gateway)如何承载API经济生态链
序言 API经济生态链已经在全球范围覆盖, 绝大多数企业都已经走在数字化转型的道路上,API成为企业连接业务的核心载体, 并产生巨大的盈利空间.快速增长的API规模以及调用量,使得企业IT在架构上.模 ...
- TCL、华星光电和中环股份,如何在一条生态链上领跑?
聚众智.汇众力.采众长. "我们决心用五年时间,将TCL科技和TCL实业做到真正的世界500强,将智能终端.半导体显示.半导体光伏三大核心产业力争做到全球领先,将半导体材料等其他产业做到中国 ...
- 【计理05组01号】R 语言基础入门
R 语言基本数据结构 首先让我们先进入 R 环境下: sudo R 赋值 R 中可以用 = 或者 <- 来进行赋值 ,<- 的快捷键是 alt + - . > a <- c(2 ...
- X86上搭建交叉工具链,来给龙芯笔记本编译本地工具链(未完待续)
故事的背景是,我买了一台龙芯2F的笔记本来装B. 为什么说是装B呢?因为不但操作系统是Linux,而且CPU还是龙芯的. 一般人有这么酷的装备吗?简直是装B大圣啊. 这里一定要申明一点,本人不是IT技 ...
- OA发展史:由点到生态
在当今无边界组织的商业背景下,企业与员工关系已经转化为联盟关系,以往通过工作场所.劳动合同等约束的形式已经逐步弱化,管理行为空前复杂,OA正是将一个个散点整合起来的看不见的手.那么,推动OA发展的核心 ...
- Rust这种新型的语言注定火不起来,功能太强大(特性太多),还不如用成熟稳定强大的C/C++,而且生态不行、所以恶性循环
这种新型的语言注定火不起来,功能太强大(特性太多),还不如用成熟稳定强大的C/C++,,而Golang足够简单,入门快,编译快,性能也强悍,解决了服务端开发人员的痛点,,注定被大多数人接受... go ...
- Modelarts与无感识别技术生态总结(浅出版)
[摘要] Modelarts技术及相关产业已成为未来AI与大数据重点发展行业模式之一,为了促进人工智能领域科学技术快速发展,modelarts现状及生态前景成为研究热点.笔者首先总结modelarts ...
- 阿里云吴天议:云原生SDWAN 应用 构建智能化云原生SDWAN生态
2019年11月16日 SDWAN 大会在北京正式召开.阿里云网络资深产品专家吴天议先生继阿里云网络研究员祝顺民先生发表了对云原生SDWAN的进化与展望之后(原文请见https://bit.ly/2K ...
随机推荐
- sqlacodegen
这个工具可以把数据库的表转成sqlalchemy用的class. 但是 table必须要有主键.否则转化成的是Table类型而不是class root@rijx:/tmp# sqlacodegen - ...
- NYOJ 16 矩形嵌套 (DAG上的DP)
矩形嵌套 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描写叙述 有n个矩形,每个矩形能够用a,b来描写叙述.表示长和宽.矩形X(a,b)能够嵌套在矩形Y(c,d)中当且仅当 ...
- UltraEdit UE如何设置自动换行
1如何设置Ultraedit自动换行 学过编程方面电脑知识的朋友可能都清楚,ultraedit是一款易用强大的文本编辑工具.并且打开没有Unicode签名(BOM)的UTF-8格式半角英文文件 ...
- jsp,velocity,freemark页面引擎的比較
在java领域.表现层技术主要有三种:jsp.freemarker.velocity. jsp是大家最熟悉的技术 长处: 1.功能强大,能够写java代码 2.支持jsp标签(jsp tag) 3.支 ...
- 模式匹配-BF算法
/***字符串匹配算法***/ #include<cstring> #include<iostream> using namespace std; #define OK 1 # ...
- Cant't call setState(or forceUpdate) on an unmount component. 报错的可能性原因
react 小白编程 遇到了如下错误 调试了很久没找到到底为啥 后来发现,是因为多次将组件挂在到根节点的原因导致的 使用路由之后,只需要使用 ReactDOM.render()方式将最外层的路由挂在到 ...
- 模块化开发(二)--- seaJs入门学习
SeaJS是一个基于CMD模块定义规范实现一个模块系统加载器 [CMD规范](https://github.com/cmdjs/specification/blob/master/draft/mo ...
- centos上装eclipse步骤
1.去官网下个eclipse for linux的 地址:http://www.eclipse.org/downloads/ Eclipse IDE for Java EE Developer ...
- to prof. Choi
Dear Prof. Choi It is my great pleasure to receive your reply ,but terribly sorry for my late reply ...
- bzoj3527
http://www.lydsy.com/JudgeOnline/problem.php?id=3527 今天肿么这么颓废啊...心态崩了 首先我们得出Ei=Fi/qj,然后我们设f[i]=1/i/i ...