mysql中 groupby分组

数据如下:
name val memo
a 2 a2(a的第二个值)
a 1 a1--a的第一个值
a 3 a3:a的第三个值
b 1 b1--b的第一个值
b 3 b3:b的第三个值
b 2 b2b2b2b2
b 4 b4b4
b 5 b5b5b5b5b5
*/
insert into tb values('a', 2, 'a2(a的第二个值)')
insert into tb values('a', 1, 'a1--a的第一个值')
insert into tb values('a', 3, 'a3:a的第三个值')
insert into tb values('b', 1, 'b1--b的第一个值')
insert into tb values('b', 3, 'b3:b的第三个值')
insert into tb values('b', 2, 'b2b2b2b2')
insert into tb values('b', 4, 'b4b4')
insert into tb values('b', 5, 'b5b5b5b5b5')
go
--一、按name分组取val最大的值所在行的数据。
select a.* from tb a where val = (select max(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val > a.val)
--方法3:
select a.* from tb a,(select name,max(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , max(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name
/*
name val memo
---------- ----------- --------------------
a 3 a3:a的第三个值
b 5 b5b5b5b5b5
*/
本人推荐使用1,3,4,结果显示1,3,4效率相同,2,5效率差些,不过我3,4效率相同毫无疑问,1就不一样了,想不搞了。
--二、按name分组取val最小的值所在行的数据。
select a.* from tb a where val = (select min(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val < a.val)
--方法3:
select a.* from tb a,(select name,min(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , min(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val < a.val) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 1 b1--b的第一个值
*/
--三、按name分组取第一次出现的行所在的数据。
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
*/
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 5 b5b5b5b5b5
*/
--五、按name分组取最小的两个(N个)val
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val < a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
b 2 b2b2b2b2
*/
--六、按name分组取最大的两个(N个)val
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val desc) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val > a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
a 3 a3:a的第三个值
b 4 b4b4
b 5 b5b5b5b5b5
*/
2 数据如下:
3 name val memo
4 a 2 a2(a的第二个值)
5 a 1 a1--a的第一个值
6 a 1 a1--a的第一个值
7 a 3 a3:a的第三个值
8 a 3 a3:a的第三个值
9 b 1 b1--b的第一个值
10 b 3 b3:b的第三个值
11 b 2 b2b2b2b2
12 b 4 b4b4
13 b 5 b5b5b5b5b5
14
15 */
16
附:mysql “group by ”与"order by"的研究--分类中最新的内容
这两天让一个数据查询难了。主要是对group by 理解的不够深入。才出现这样的情况
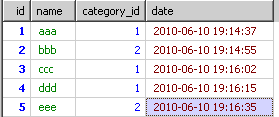
我现在需要取出每个分类中最新的内容
结果如下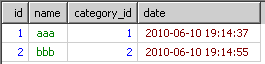
明显。这不是我想要的数据,原因是msyql已经的执行顺序是
执行顺序:from... where...group by... having.... select ... order by...
所以在order by拿到的结果里已经是分组的完的最后结果。
由from到where的结果如下的内容。
到group by时就得到了根据category_id分出来的多个小组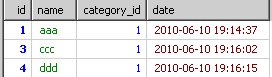
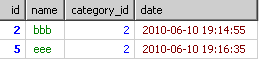
到了select的时候,只从上面的每个组里取第一条信息结果会如下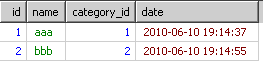
即使order by也只是从上面的结果里进行排序。并不是每个分类的最新信息。
回到我的目的上 --分类中最新的信息
根据上面的分析,group by到select时只取到分组里的第一条信息。有两个解决方法
1,where+group by(对小组进行排序)
2,从form返回的数据下手脚(即用子查询)
由where+group by的解决方法
对group by里的小组进行排序的函数我只查到group_concat()可以进行排序,但group_concat的作用是将小组里的字段里的值进行串联起来。
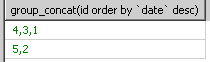
再改进一下
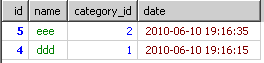
子查询解决方案
mysql中 groupby分组的更多相关文章
- mysql中的分组统计函数及其用法实例
1.使用group by对数据进行分组:select 字段名... from tablename group by 字段名...:可以把分组.排序.统计等等都结合在一起使用,实际应用中也多是这样的: ...
- 如何在MySQL中查询每个分组的前几名【转】
问题 在工作中常会遇到将数据分组排序的问题,如在考试成绩中,找出每个班级的前五名等. 在orcale等数据库中可以使用partition语句来解决,但在mysql中就比较麻烦了.这次翻译的文章就是专门 ...
- 在mysql中使用group by和order by取每个分组中日期最大一行数据
转载自:https://blog.csdn.net/shiyong1949/article/details/78482737 在mysql中使用group by进行分组后取某一列的最大值,我们可以直接 ...
- 如何在mysql中查询每个分组的前几名
问题 在工作中常会遇到将数据分组排序的问题,如在考试成绩中,找出每个班级的前五名等. 在orcale等数据库中可以使用partition 语句来解决,但在MySQL中就比较麻烦了.这次翻译的文章就是 ...
- 一个MySQL中两表联合update的例子(并带有group by分组)
内容简介 本文主要展示了在MySQL中,使用两表联合的方式来更新其中一个表字段值的SQL语句. 也就是update table1 join table2 on table1.col_name1=tab ...
- Python中itertools.groupby分组的使用
Python中itertools.groupby分组的使用 有时候我们需要给一个列表按照某个属性分组,可以借助groupby来实现. 比如:一下列表我想以严重程度给它分组,并求出每组的元素个数. fr ...
- MySQL中group_concat函数 --- 很有用的一个用来查询出所有group by 分组后所有 同组内的 内容
本文通过实例介绍了MySQL中的group_concat函数的使用方法,比如select group_concat(name) . MySQL中group_concat函数 完整的语法如下: grou ...
- mysql中explain
1.select_type: /* select_type 使用 SIMPLE */explain select * from tb_shop_order where id='201603292570 ...
- laravel groupby分组问题。
laravel 5.7使用groupBy分组查询时会提示一个错误,但是sql可以执行. 因为:mysql从5.7以后,默认开启了严格模式. 解决方法:将/config/database.php 中:关 ...
随机推荐
- 07Html、CSS
07Html.CSS-2018/07/17 1.HTML是用来描述网页的一种标记语言,是一套标记标签.HTML用使用标记标签来描述网页.超文本 标记语言. 2.格式 <html> < ...
- MySQL各种版本的下载方式
1.在百度上搜“MySQL”,进入官网 原文地址:https://blog.csdn.net/mieleizhi0522/article/details/79109195
- 网络模型、IP命令、SS命令介绍
1. 分层对应关系 OSI七层模型和TCP/IP五层模型都属于TCP/IP协议栈,而TCP/IP协议栈只有两种传输层协议:TCP.UDP,所以对于Telnet.FTP这些协议,建议称之为承载在TCP之 ...
- 洛谷 1062 NOIP2006普及T4 数列
[题解] 鲜活的水题..我们把数列换成k进制的,发现数列是001,010,011,100,101,110,111...,而第m项用k进制表示的01串刚好就是m的二进制的01串.于是我们预处理k的幂,把 ...
- JavaScript保留关键字(全)
JavaScript 标准 所有的现代浏览器已经完全支持 ES5(ECMAScript 5). JavaScript 保留关键字(keyword) Javascript 的保留关键字(标识符)不可以用 ...
- Python学习笔记 (2.1)标准数据类型之Number(数字)
Python3中,数字分为四种——int,float,bool,complex int(整型) 和数学上的整数表示没啥区别,没有大小限制(多棒啊,不用写整数高精了),可正可负.还可表示16进制,以 0 ...
- noip模拟赛 立方数
题目描述LYK定义了一个数叫“立方数”,若一个数可以被写作是一个正整数的3次方,则这个数就是立方数,例如1,8,27就是最小的3个立方数.现在给定一个数P,LYK想要知道这个数是不是立方数.当然你有可 ...
- noip模拟赛 运
[问题背景]zhx 和妹子们玩数数游戏.[问题描述]仅包含 4 或 7 的数被称为幸运数.一个序列的子序列被定义为从序列中删去若干个数, 剩下的数组成的新序列.两个子序列被定义为不同的当且仅当其中的元 ...
- Promise 异步编程
//1.解决异步回调问题 //1.1 如何同步异步请求 //如果几个异步操作之间并没有前后顺序之分,但需要等多个异步操作都完成后才能执行后续的任务,无法实现并行节约时间 const fs = requ ...
- Mysql 练习题 及 答案
--1.学生表 Student(S,Sname,Sage,Ssex) --S 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 --2.课程表 Course(C,Cname,T ...