Sql Server系列:索引基础
1 索引概念
索引用于快速查找在某个列中某个特定值的行,不使用索引,数据库必须从第1条记录开始读完整个表,知道找出需要的行。表越大,查询数据所花费的时间越多。如果表中查询的列有索引,数据库能快速到达一个位置去查找数据,而不必遍历所有数据。
索引是一个单独的、存储在磁盘上的数据库结构,包含对数据表里所有记录的引用指针。使用索引用于快速找出一个或多个列中有特定值的行,对相关列使用索引是降低查询操作时间的最佳途径。索引包含由表或试图中的一列或多列生成的键。
索引的优点:
◊ 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
◊ 可以大大加快数据的查询速度,这也是创建索引的最主要的原因。
◊ 实现数据的参照完整性,可以加速表和表之间的连接。
◊ 在使用分组和排序子句进行数据查询时,可以显著减少查询中分组和排序的时间。
索引的缺点:
◊ 创建索引和维护索引需要耗费时间,并且随着数据量的增加所消耗的时间会增加。
◊ 索引需要占用磁盘空间,除了数据表占数据空间之外,每一个索引还要占用一定的物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件大小。
◊ 当对表中的数据进行添加、修改和删除的时候,索引需要动态维护,这样降低了数据的维护速度。
2 索引的分类
SQL Server中索引有两种:聚集索引和非聚集索引。它们的区别是在物理数据的存储方式上。
2.1 聚集索引
聚集索引基于数据行的键值,在表内排序和存储这些数据行。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
创建聚集索引时需要考虑的几个因素:
◊ 每个表只能有一个聚集索引
◊ 表中的物理顺序和索引中行的物理顺序是相同的,创建任何非聚集索引之前要首先创建聚集索引,这是因为聚集索引改变了表中行的物理顺序。
◊ 关键值的唯一性使用UNIQUE关键字或者由内部的唯一标识符明确维护。
◊ 在索引的创建过程中,SQL Server临时使用当前数据库的磁盘空间,所以要保证有足够的空间创建聚集索引。
2.2 非聚集索引
非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页的数据按列排序。非聚集索引包含索引键值和指向表数据存储位置的行定位器。
可以对表或索引视图创建多个非聚集索引。设计非聚集索引是为了改善经常使用的、没有建立聚集索引的查询的性能。
查询优化器在查找数据值时,先查找非聚集索引以找到数据值在表中的位置,然后直接从该位置检索数据。这使得非聚集索引成为完全匹配查询的最佳选择,因为索引中包含所查找的数据值在表中的精确位置的项。
考虑使用非聚集索引的查询情况:
◊ 使用JOIN或GROUP BY子句。应为连接和分组操作中所涉及的列创建多个非聚集索引,为任何外键列创建聚集索引。
◊ 包含大量唯一值的字段。
◊ 不返回大型结果集的查询。创建筛选索引以覆盖从大型表中返回定义完善的行子集的查询。
◊ 经常包含在查询的搜索条件中的列。
3 创建索引
SQL Server中创建索引的两中方法:在SQL Server Management Studio的对象资源管理器中,通过图形化工具创建或使用T-SQL语句创建。
3.1 使用SQL Server Management Studio对象资源管理器创建
◊ 在【对象资源管理器】中,展开【数据库】找到需要创建索引的数据表节点,展开该节点下的子节点,右击【索引】节点,在弹出的快捷菜单中选择【新建索引】->【非聚集索引】。

◊ 在打开的【新建索引】界面选择需要创建索引的列,进而创建索引。
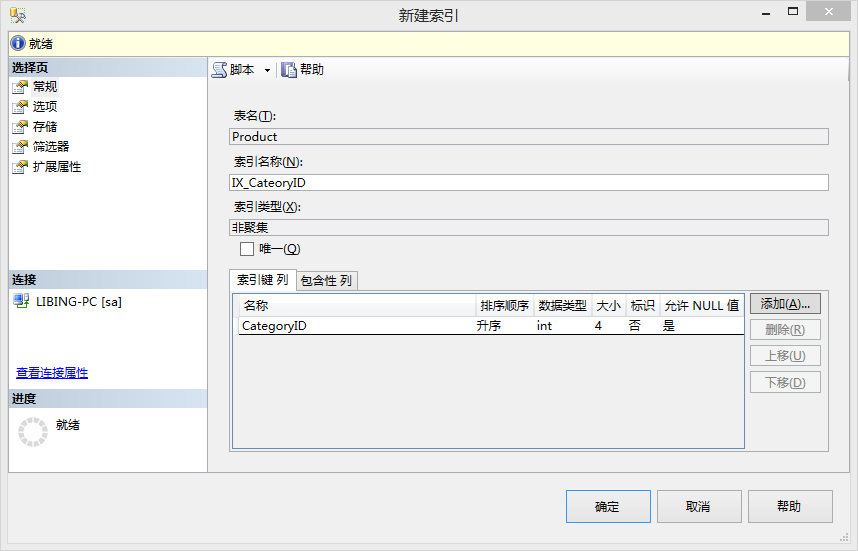
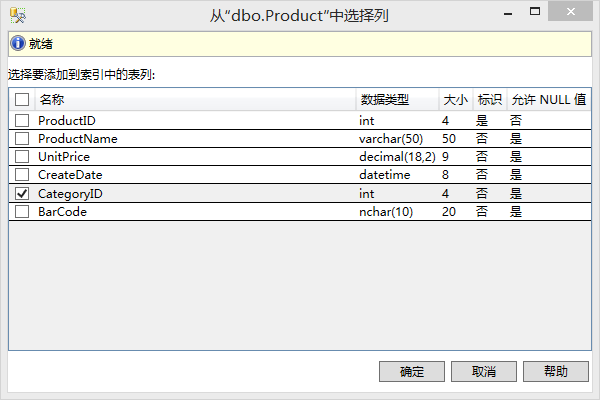
3.2 T-SQL创建索引
CREATE INDEX语法:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column [ ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
[ WITH ( <relational_index_option> [ ,...n ] ) ]
[ ON { partition_scheme_name ( column_name )
| filegroup_name
| default
}
]
[ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ] [ ; ] <object> ::=
{
[ database_name. [ schema_name ] . | schema_name. ]
table_or_view_name
} <relational_index_option> ::=
{
PAD_INDEX = { ON | OFF }
| FILLFACTOR = fillfactor
| SORT_IN_TEMPDB = { ON | OFF }
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| STATISTICS_INCREMENTAL = { ON | OFF }
| DROP_EXISTING = { ON | OFF }
| ONLINE = { ON | OFF }
| ALLOW_ROW_LOCKS = { ON | OFF }
| ALLOW_PAGE_LOCKS = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| DATA_COMPRESSION = { NONE | ROW | PAGE}
[ ON PARTITIONS ( { <partition_number_expression> | <range> }
[ , ...n ] ) ]
}
创建索引:
IF EXISTS (SELECT name from sys.indexes
WHERE name = N'IX_Product_CategoryID')
DROP INDEX IX_Product_CategoryID ON [dbo].[Product];
GO
CREATE NONCLUSTERED INDEX IX_Product_CategoryID
ON [dbo].[Product]([CategoryID]);
创建过滤索引:
CREATE NONCLUSTERED INDEX IX_Product_CategoryID
ON [dbo].[Product]([CategoryID])
WHERE [UnitPrice] > 10
4 查看表或试图的索引信息
系统存储过程sp_helpindex可以返回某个表或试图的索引信息。
语法:
sp_helpindex [ @objname = ] 'name'
查看表中包含的全部索引:
EXEC sp_helpindex N'Product'
5 查看索引的统计信息
索引的统计信息可以用来分析索引性能,更好地维护索引。
DBCC SHOW_STATISTICS (N'Portal.dbo.Product', N'IX_CategoryID')
6 重命名索引
系统存储过程sp_rename可以用于更改索引的名称,其语法格式如下:
sp_rename [ @objname = ] 'object_name' , [ @newname = ] 'new_name'
[ , [ @objtype = ] 'object_type' ]
示例:
EXEC sp_rename 'dbo.Product.IX_CategoryID' , 'IX_Product_CategoryID' , 'INDEX'
7 修改索引
7.1 ALTER INDEX语法
ALTER INDEX { index_name | ALL }
ON <object>
{ REBUILD
[ PARTITION = ALL ]
[ WITH ( <rebuild_index_option> [ ,...n ] ) ]
| [ PARTITION = partition_number
[ WITH ( <single_partition_rebuild_index_option> ) [ ,...n ] ]
]
| DISABLE
| REORGANIZE
[ PARTITION = partition_number ]
[ WITH ( LOB_COMPACTION = { ON | OFF } ) ]
| SET ( <set_index_option> [ ,...n ] )
}
[ ; ]
<object> ::=
{
[ database_name. [ schema_name ] . | schema_name. ]
table_or_view_name
}
<rebuild_index_option > ::=
{
PAD_INDEX = { ON | OFF }
| FILLFACTOR = fillfactor
| SORT_IN_TEMPDB = { ON | OFF }
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| STATISTICS_INCREMENTAL = { ON | OFF }
| ONLINE = { ON [ ( <low_priority_lock_wait> ) ] | OFF }
| ALLOW_ROW_LOCKS = { ON | OFF }
| ALLOW_PAGE_LOCKS = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| DATA_COMPRESSION = { NONE | ROW | PAGE | COLUMNSTORE | COLUMNSTORE_ARCHIVE }
[ ON PARTITIONS ( { <partition_number_expression> | <range> }
[ , ...n ] ) ]
}
<range> ::=
<partition_number_expression> TO <partition_number_expression>
<single_partition_rebuild_index_option> ::=
{
SORT_IN_TEMPDB = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| DATA_COMPRESSION = { NONE | ROW | PAGE | COLUMNSTORE | COLUMNSTORE_ARCHIVE} }
| ONLINE = { ON [ ( <low_priority_lock_wait> ) ] | OFF }
}
<set_index_option>::=
{
ALLOW_ROW_LOCKS = { ON | OFF }
| ALLOW_PAGE_LOCKS = { ON | OFF }
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
}
<low_priority_lock_wait>::=
{
WAIT_AT_LOW_PRIORITY ( MAX_DURATION = <time> [ MINUTES ] ,
ABORT_AFTER_WAIT = { NONE | SELF | BLOCKERS } )
}
7.2 示例
禁用索引
ALTER INDEX [IX_CategoryID] ON [dbo].[Product] DISABLE
重新启用索引
ALTER INDEX [IX_CategoryID] ON [dbo].[Product] REBUILD
8 删除索引
DROP INDEX语法:
DROP INDEX
{ <drop_relational_or_xml_or_spatial_index> [ ,...n ]
| <drop_backward_compatible_index> [ ,...n ]
} <drop_relational_or_xml_or_spatial_index> ::=
index_name ON <object>
[ WITH ( <drop_clustered_index_option> [ ,...n ] ) ] <drop_backward_compatible_index> ::=
[ owner_name. ] table_or_view_name.index_name <object> ::=
{
[ database_name. [ schema_name ] . | schema_name. ]
table_or_view_name
} <drop_clustered_index_option> ::=
{
MAXDOP = max_degree_of_parallelism
| ONLINE = { ON | OFF }
| MOVE TO { partition_scheme_name ( column_name )
| filegroup_name
| "default"
}
[ FILESTREAM_ON { partition_scheme_name
| filestream_filegroup_name
| "default" } ]
}
示例:
DROP INDEX [dbo].[Product].[IX_Product_CategoryID]
DROP INDEX [IX_Product_CategoryID] ON [dbo].[Product]
Sql Server系列:索引基础的更多相关文章
- [译]SQL Server 之 索引基础
SQL Server中,索引以B-tree的结构组织数据.B-tree代表平衡树,但是SQL Server使用一种叫做B+的树. B+树不是总是保持严格的平衡的树. 首先,索引有两个主要的部件:一个页 ...
- SQL Server 查询优化 索引的结构与分类
一.索引的结构 关系型数据库中以二维表来表达关系模型,表中的数据以页的形式存储在磁盘上,在SQL SERVER中,数据页是磁盘上8k的连续空间,那么,一个表的所有数据页在磁盘上是如何组织的呢?分两种情 ...
- SQL Server 数据库索引
原文:SQL Server 数据库索引 一.什么是索引 减少磁盘I/O和逻辑读次数的最佳方法之一就是使用[索引] 索引允许SQL Server在表中查找数据而不需要扫描整个表. 1.1.索引的好处: ...
- SQL Server之索引解析(一)
SQL Server之索引解析(一) 1.写在前面 微软专门给出SQL Server设计思路及实现路线,从7大体系结构阐述是如何实现,通过了解这些,我们就可以总结出数据库设计原则.编程中sql写法 ...
- SQL Server 系列文章快速导航(SWF版)
一.前言 在博客园写博客不自不觉已经有5个年头了,一开始只是为了记录工作中遇到的问题和解决办法,后来写的文章不自不觉的侧重在SQL Server方面的技术文章,在2014年1月终于鼓起勇气申请了微软S ...
- 公司内部培训SQL Server传统索引结构PPT分享
公司内部培训SQL Server传统索引结构PPT分享 下载地址 http://files.cnblogs.com/files/lyhabc/SQLServer%E4%BC%A0%E7%BB%9F%E ...
- SQL Server创建索引(转)
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的速度,汉语字(词)典一般都有按拼音. ...
- 理解SQL Server中索引的概念
T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他 简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能 ...
- SQL Server创建索引
原文:SQL Server创建索引 什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的 ...
随机推荐
- Set和存储顺序
set(interface) 存入Set的每个元素必须是唯一的,因为Set不保存重复的元素.加入Set的元素必须定义 equal()方法以确保对象的唯一性.Set和Collection有完全一样的接口 ...
- 通过url传参
简介: 通过url传单个和多个参数 你得配Route; 你得使用ui-sref传参数; 在你相关Route的Controller里面Inject $stateParams,然后取参数就OK. 实例: ...
- 原生JS 年月日、省市区 三级联动
这个算生日日期,因为是从100年前的到现年. <select id="sel_year"></select> <select id="sel ...
- Xml 建议优先使用属性
要点:建议优先选用属性的方式记录数据,除非还需要包容层级式的数据. 优点: 1. 可以完全覆盖关系型数据库的数据格式设计,利于交换. 2. 占用空间小.相当于 JSON 格式,不再有大量重复的节点名后 ...
- Yii框架CURD方法
在YII框架中,CURD有2种方式: 1.AR模式:2. DAO模式 AR模式下 查全部 MODEL $model->find()->asArray()->all()查单 个 ...
- Qgis连接Oracle
CMake编译中选择编译Oracle一项以后,编译的qgis才会有连接Oracle数据库的功能. 编译qgis以后,可以通过添加矢量图层中选择Oracle数据库,或是添加Oracle空间图层,或是添加 ...
- 安装cocoaPods的详细步骤
先大概说下安装的步骤: Xcode 这个是开发必须的, HomeBrew RVM Ruby CocoaPods 一.HomeBrew: 打开官网链接:http://brew.sh/index_zh-c ...
- 【WPF】WPF中的List<T>和ObservableCollection<T>
在WPF中 控件绑定数据源时,数据源建议采用 ObservableCollection<T>集合 ObservableCollection<T> 类:表示一个动态数据集合,在添 ...
- centos上安装php运行环境
可以参考,但我安装的过程不完全一样http://www.cnblogs.com/liulun/p/3535346.html 我先安装的apache,直接执行的yum -y install httpd ...
- Kafka设计解析(二)- Kafka High Availability (上)
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/04/24/KafkaColumn2 摘要 Kafka在0.8以前的版本中,并不提供High Av ...