kafka2
Master-Slave:
读写分离,save复制master的数据。同步复制:保证了强一致性但是会影响高可用性,因为写入的时候要保证slave都写入了才能返回告诉生产者数据写入成功,如果slave过多就是时间过长。异步复制:数据写入master之后不要求所有的slave都写入就返回生产者写入成功,然后由slave异步的同步,同步过程既可以是master去推也可以是slave去拉,master不需要等待slave的完成,减少了响应时间,风险在于数据的不一致性。
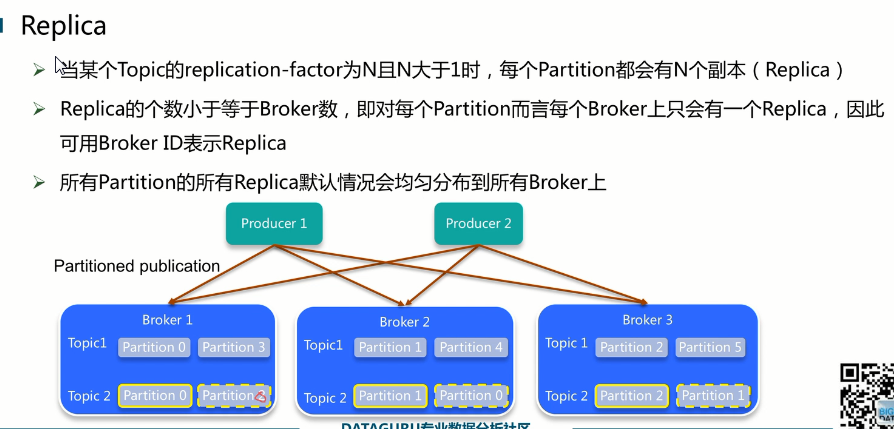
Broker是kafka的server,也可以看成是kafka的进程。
Topic2的Partition0再Broker1上,他的副本再Broker2上,Partition1的主本在Broker2上他的副本在Broker3上,就保证了一个Broker挂了partition还是可用的。 Kafka用的是Master和Slave的方式,每一个Patition有一个主节点leader(Master),还有好几个Follower(Slave)。
下图以Topic1的PAtition1为例,topic1-pation1的leader在broker1上面,follower在brojer2和broker3上面,生产者写消息的时候之后写入broker上面去,然后数据复制进broker2和broker3(拉的方式),消费者读数据也只是从leader读,follower只是保证leader挂了follower可以使用。
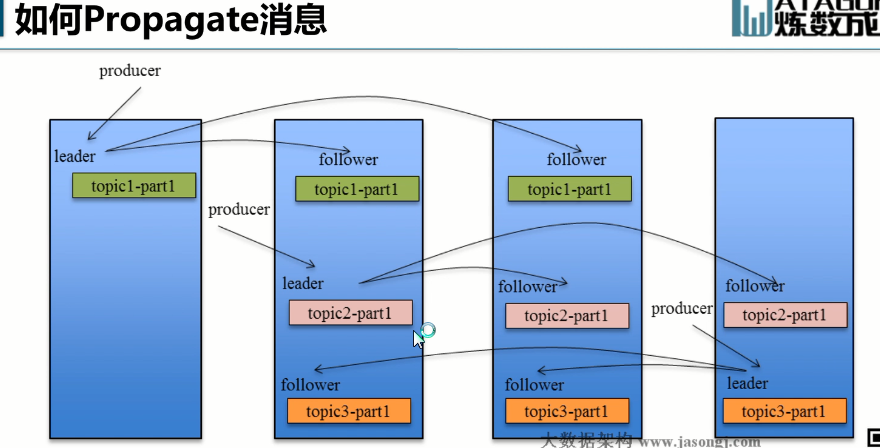
Kafka的主从复制,既不是同步复制也不是异步复制。

主节点会维护一个次节点的列表ISR,如果子节点(挂了)落后太多就会移除次节点,所有存活的次节点都向主节点发送ACk就commit,生产者就认为数据提交了,消费者只能读取commit的数据。

如果10秒还没有发送ack就移除次节点,如果主节点和次节点数据相差4000条就会移除follower。如果次节点后来的差距小于4000了就会把该次节点重新加入ISR。
最小的follower数量是1。
不需要等待follower发送ack。
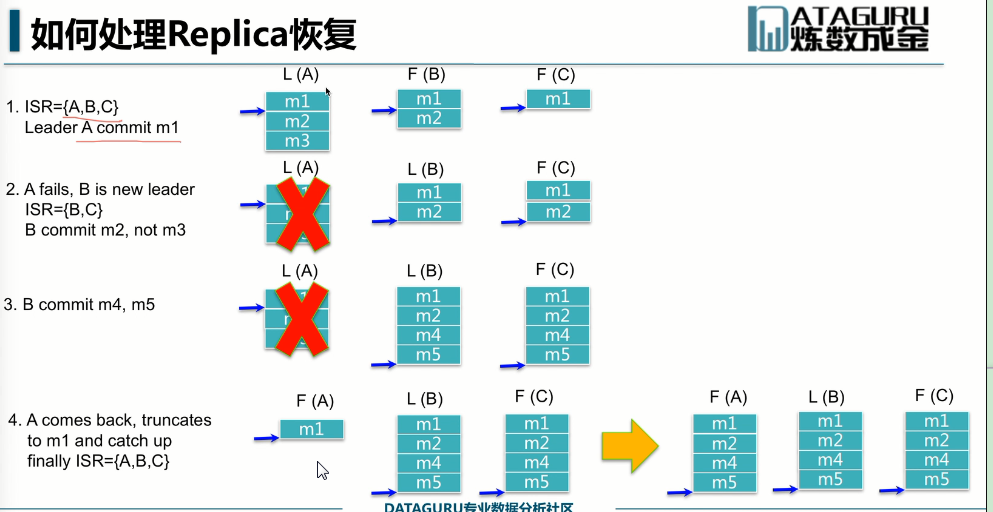
第一步:A是leader,B,C是followe,但是只有m1被commit了,所以消费者只能读到m1,m2,m3不能读到。
第二部:A挂了,B成为Leader,C是Follower, 此时m2被commit。
第三部:m4,m5被commit
第四部:A回来了,A就会去catch up把B里面commit的所有数据都拿过来。M3一直没有commit就丢失了,m3没有commit过,那么生产者就不会认为m3发生成功过,就会retry,retry3次还没有成功就丢失了,retry成功了就会在m5的后面,造成数据的顺序不一致。
kafka2的更多相关文章
- kafka2.9.2的伪分布式集群安装和demo(java api)测试
目录: 一.什么是kafka? 二.kafka的官方网站在哪里? 三.在哪里下载?需要哪些组件的支持? 四.如何安装? 五.FAQ 六.扩展阅读 一.什么是kafka? kafka是LinkedI ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- kafka-2.11-0.11集群搭建
kafka集群依赖于zookeeper,所以需要先搭建zookeeper集群,kafka默认自带了内建的zookeeper,建议使用自己外搭建的zookeeper,这样比较灵活并且解耦服务,同时也可以 ...
- Kafka2.6.0发布——性能大幅提升
近日Kafka2.6版本发布,距离2.5.0发布只过去了不到四个月的时间. Kafka 2.6.0包含许多重要的新功能.以下是一些重要更改的摘要: 默认情况下,已为Java 11或更高版本启用TLSv ...
- Kafka2.8安装
1.概述 最近Kafka官网发布了2.8版本,在该版本中引入了KRaft模式.鉴于新版本和新特性的引入,相关使用资料较少,那边本篇博客笔者将为大家介绍Kafka2.8的安装和使用. 2.内容 2.1 ...
- kafka2.x常用命令笔记(一)创建topic,查看topic列表、分区、副本详情,删除topic,测试topic发送与消费
接触kafka开发已经两年多,也看过关于kafka的一些书,但一直没有怎么对它做总结,借着最近正好在看<Apache Kafka实战>一书,同时自己又搭建了三台kafka服务器,正好可以做 ...
- Kafka(二)CentOS7.5搭建Kafka2.11-1.1.0集群与简单测试
一.下载 下载地址: http://kafka.apache.org/downloads.html 我这里下载的是Scala 2.11对应的 kafka_2.11-1.1.0.tgz 二.kaf ...
- kafka2 简单介绍
kafka是JMS的一种实现 JMS(java message service):middle ware,中间件技术.Queue:队列模式,P2P,点对点.publish-subscribe:主题模式 ...
- CentOS6.5安装kafka-2.10-0.8.2(单机)
1.下载 地址:https://kafka.apache.org/downloads 本文中下载版本:kafka_2.10-0.8.2.2.tgz 2.安装 安装目录:/usr/local [root ...
- 单机RedHat6.5+JDK1.8+Hadoop2.7.3+Spark2.1.1+zookeeper3.4.6+kafka2.11+flume1.6环境搭建步骤
1.RHEL 6.5系统安装配置图解教程(rhel-server-6.5) 2.在Linux下安装JDK图文解析 3.RedHat6.5上安装Hadoop单机 4.RedHat6.5安装Spark单机 ...
随机推荐
- BZOJ 3527 [Zjoi2014]力 ——FFT
[题目分析] FFT,构造数列进行卷积,挺裸的一道题目诶. 还是写起来并不顺手,再练. [代码] #include <cmath> #include <cstdio> #inc ...
- NCCloud 指令示例
http://ansrlab.cse.cuhk.edu.hk/software/nccloud/ Implementation of NCCloud in C++ (updated: August 2 ...
- 【shell】shell编程(一)-入门
如今,不会Linux的程序员都不意思说自己是程序员,而不会shell编程就不能说自己会Linux.说起来似乎shell编程很屌啊,然而不用担心,其实shell编程真的很简单.背景 什么是shell编程 ...
- Linux,以逗号为分隔符,打印文件file.txt中的第一个和第三个字符
https://zhidao.baidu.com/question/1883257355267391828.html
- js react 全选和反选
onCheckAll = (data) => { var CheckBox = document.getElementsByName(data); for(let i=0;i<CheckB ...
- (5)Swing事件
import javax.swing.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; publi ...
- B站papi酱、陈一发、李云龙
李云龙-花田错 https://www.bilibili.com/video/av10842071/?from=timeline&isappinstalled=1 李云龙:你猜旅长怎么说? h ...
- java基础之IO流(一)字节流
java基础之IO流(一)之字节流 IO流体系太大,涉及到的各种流对象,我觉得很有必要总结一下. 那什么是IO流,IO代表Input.Output,而流就是原始数据源与目标媒介的数据传输的一种抽象.典 ...
- Javascript构造函数和原型
相信你已经知道了,Javascript函数也可以作为对象构造器.比如,为了模拟面向对象编程中的Class,可以用如下的代码 function Person(name){ this.name = nam ...
- Elasticsearch shield权限管理详解
Elasticsearch shield权限管理详解 学习了:https://blog.csdn.net/napoay/article/details/52201558 现在(20180424)改名为 ...