【面试 hibernate】【第二篇】hibernate相关问题
1.hibernate工作原理【说一下你怎么理解的hibernate】
hibernate是一个ORM对象关系映射的持久层框架,是对JDBC的轻量级封装。
【可以不记,hibernate核心接口】
1》Configuration 加载配置,启动hibernate,创建sessionFactory
2》SessionFactory,初始化hibernate,创建session
3》session负责被持久化对象的CRUD操作,并开启事务Transaction tx = session.beginTransaction();
4》Query和Criteria接口,拼接SQL,进行持久化操作
5》提交事务
6》关闭session
7》关闭sessionFactory
1)拓展1:hibernate有什么好处,和mybatis相比
http://www.cnblogs.com/sxdcgaq8080/p/8834845.html
===============================================================
2.hibernate核心接口有哪些,核心模块都分别扮演什么样的角色
1》Configuration 加载配置,启动hibernate,创建sessionFactory
2》SessionFactory,初始化hibernate,创建session
3》session负责被持久化对象的CRUD操作,并开启事务Transaction tx = session.beginTransaction();
4》Query和Criteria接口,拼接SQL,进行持久化操作
5》提交事务
6》关闭session
7》关闭sessionFactory
===============================================================
3.get()和load()方法的区别
http://www.cnblogs.com/sxdcgaq8080/p/8836164.html
1》get()用于查询不确定是否存在的对象、立即执行sql语句、返回真实对象、没有返回Null
2》load()用于查询确定存在的对象、不立即执行sql语句、返回代理对象或真实对象、实际使用非ID字段时没有则抛异常ObjectNotFoundException
===============================================================
4.save()、saveOrUpdate()、persist()、merge()、update()方法的区别【http://www.cnblogs.com/sxdcgaq8080/p/8836302.html】
1》save()方法 执行inset语句、立即执行sql、返回标识、不会被保存到持久化上下文中
2》saveOrUpdate()方法 执行inset/update语句、无返回值、会将实体对象添加到持久化上下文中,后续操作会被跟踪
3》persist() 执行inset语句、不立即执行sql、无返回值、会将实体对象添加到持久化上下文中,后续操作会被跟踪
4》update()方法,执行update语句、不立即执行sql、无返回值、会将实体对象添加到持久化上下文中,后续操作会被跟踪
5》merge()方法,更新数据库记录,唯一区别在于创建传递进来实体对象的副本,作为返回值,返回值为持久化上下文对象,能够跟踪实体的改变,而传递进来的值不会。
===============================================================
5.sessionFactory是什么,是做什么的
sessionFactory是用来创建每次客户请求到达的一个一个session的。单例,全局唯一,所以线程安全。
===============================================================
6.hibernate中的session是指什么,是否可以多线程间共享
hibernate中负责被持久化对象CRUD操作的接口,每个请求到达是一个新的session,所以是线程不安全的,用完就关闭了。
===============================================================
7.瞬时状态、持久化状态和游离状态分别都是什么,怎么可以转化
1》瞬时状态:从未与session发生关联,persist()或save() 可以转成持久化状态
2》持久化状态:唯一与session关联的,字段变更或手动flush()都会持久化到数据库中
3》游离状态:以前与session有关联,现在没有关联的,可以通过update()或saveOrUpdate()方法让它重新变成持久化状态
7.1 三种状态之间的转化
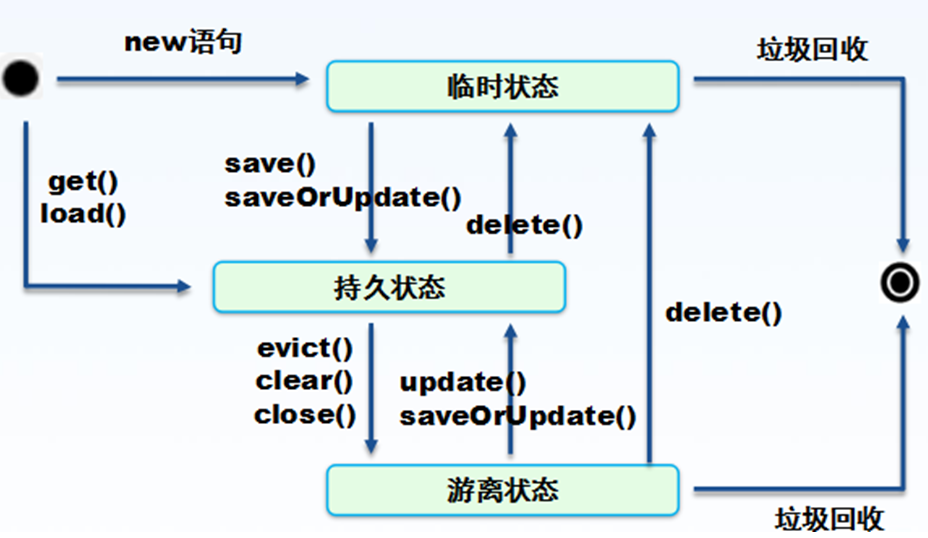
7.2 evict() clear() close()方法的区别
1》evict(obj)方法,将指定对象从session中清除
2》clear()方法,将所有对象从session中清除,但不包括正在操作的对象
3》close()方法,关闭session,关闭之前会强制行一次flush()操作,将内存中的数据flush进数据库
===============================================================
8.hibernate的二级缓存你了解么?
1》hibernate的一级缓存是session级别的缓存,属于事务级别的缓存,默认是开启的。
2》hibernate二级缓存是sessionFactory级别的缓存,被所有session共享。
3》二级缓存默认是关闭的,之前项目使用Ehcache做二级缓存
4》二级缓存的并发访问策略:
1):事务(Transaction)仅在受管理的环境中可用。它保证可重读的事务隔离级别,可以对读/写比例高,很少更新的数据采用该策略。
2):读写(read-write)使用时间戳机制维护读写提交事务隔离级别。可以对读/写比例高,很少更新的数据采用该策略。
3):非严格读写(notstrict-read-write)不保证Cache和数据库之间的数据库的一致性。使用此策略时,应该设置足够的缓存过期时间,否则可能从缓存中读出脏数据。当一些数据极少改变,并且当这些数据和数据库有一部份不量影响不大时,可以使用此策略。
4):只读(read-only)当确保数据永不改变时,可以使用此策略。
===============================================================
9.hibernate的查询缓存你知道么?
1》查询缓存默认情况下是关闭的
2》查询缓存是为了提高批量查询的效率,而get/load的缓存则是提高单条查询的效率
3》查询缓存中key是hql/sql查询语句,值是满足条件的主键的结果集,而不是缓存所有字段值
4》查询缓存只对list起作用,对iterator没用。
5》开启查询缓存的情况下,必须开启二级缓存,否则无用
拓展:list()和iterator()区别
(1) 从上面的执行结果可以看出获取的方式不一样
List的获取方式为:List<Customers> list = query.list();
Iterator的获取方式:Iterator<Customers> it = query.iterate();
(2)从执行结果可以看出list输出一条语句,而iterator输出的是两条sql语句,我们可想一下,为什么会输出这样的效果?
因为他们获取数据的方式不一样,list()会直接查询数据库,iterator()会先到数据库中把id都取出来,然后真正要遍历某个对象的时候先到缓存中找,如果找不到,
以id为条件再发一条sql到数据库,这样如果缓存中没有数据,则查询数据库的次数为n+1次
(3)list只查询一级缓存,而iterator会从二级缓存中查
(4)list方法返回的对象都是实体对象,而iterator返回的是代理对象
(5) session中list第二次发出,仍会到数据库査询
(6) iterate 第二次,首先找session 级缓存
===============================================================
10.hibernate为什么要求在实体类中需要提供一个无参的构造器?
因为hibernate要使用反射机制来创建实体类的实例。所以需要无参的构造器。
拓展:为什么反射机制需要无参的构造方法?
一般来说反射是这样实现的:
Class class = Class.forName(className);
Object object = class.newInstance(); // 只能调用无参构造函数
因此需要提供无参的构造方法。
===============================================================
11.hibernate中关于事务你知道多少?
数据库事务隔离级别:
1》读未提交--一个事务读到另一个事务未提交的数据。3个问题,0个解决
2》读已提交--一个事务读到另一个事务已提交的数据。2个问题,1个解决【脏读问题】
3》可重复读--一个事务内重复读取数据是一致的,即使另一个事务在这个过程中提交了更改的新数据。1个问题,2个解决【脏读问题,不可重复读问题】
4》串行化的--同时只允许一个事务操作,其他事务暂时挂起等待。0个问题,3个解决【脏读问题,不可重复读问题,虚读(幻读)问题】
mysql默认的数据库事务隔离级别是 可重复读。
拓展:【脏读】/【不可重复读】/【幻读】区别
1》脏读:一个事务可以读取到另一个事务还没有提交的数据,叫脏读
2》不可重复读:一个事务在一段时间内两次相同的读取数据操作,但是第二次读取到的数据和第一次读取到的数据不一样。多因为另一个事务对这条数据的更新操作。
3》幻读(虚读):一个事务在一段时间内两次读取数据的条数不同。多因为另一个数据新增了数据或者删除了数据。
【面试 hibernate】【第二篇】hibernate相关问题的更多相关文章
- Hibernate第二篇【API讲解、执行流程图】
前言 从上一篇中已经大致介绍了Hibernate并且有了一个快速入门案例的基础了,-.本博文主要讲解Hibernate API 我们看看快速入门案例的代码用到了什么对象吧,然后一个一个讲解 publi ...
- SSH框架之Hibernate第二篇
1.1 持久化类的编写规则 1.1.1 什么是持久化类? 持久化类 : 与表建立了映射关系的实体类,就可以称之为持久化类. 持久化类 = Java类 + 映射文件. 1.1.2 持久化类的编写规则 ( ...
- Flask第二篇——服务器相关
web服务器.应用服务器和web应用框架 web服务器:负责处理http请求.响应静态文件,常见的有Apache,Nginx以及微软的IIS 应用服务器:负责处理逻辑的服务器.比如php.python ...
- 【SSH三大框架】Hibernate基础第二篇:编写HibernateUtil工具类优化性能
相对于上一篇中的代码编写HibernateUtil类以提高程序的执行速度 首先,仍然要写一个javabean(User.java): package cn.itcast.hibernate.domai ...
- Hibernate 系列 04 - Hibernate 配置相关的类
引导目录: Hibernate 系列教程 目录 前言: 通过上一篇的增删改查小练习之后,咱们大概已经掌握了Hibernate的基本用法. 我们发现,在调用Hibernate API的过程中,虽然Hib ...
- Hibernate日常应用的相关问题
1.在控制台中显示Hibernate打印的SQL中的参数 默认情况下,hibernate的sql中都是以问号代表参数,并没有显示参数的真实值,但是也不是做不到,只需要两步配置就可以显示出参数的真实值了 ...
- SSH之Hibernate总结篇
Hibernate hibernate 简介: hibernate是一个开源ORM(Object/Relationship Mipping)框架,它是对象关联关系映射的持久层框架,它对JDBC做了轻量 ...
- Hibernate.基础篇《二》. getOpenSession() 和 getCurrentSession() - 1
Hibernate.基础篇<二>. getOpenSession() 和 getCurrentSession() - 1 说明: 在Hibernate应用中,Session接口的使用最为广 ...
- (Hibernate进阶)Hibernate系列——总结篇(九)
这篇博文是hibernate系列的最后一篇,既然是最后一篇,我们就应该进行一下从头到尾,整体上的总结,将这个系列的内容融会贯通. 概念 Hibernate是一个对象关系映射框架,当然从分层的角度看,我 ...
- Hibernate第一篇【介绍Hibernate,简述ORM,快速入门】
前言 前面已经学过了Struts2框架了,紧接着就是学习Hibernate框架了-本博文主要讲解介绍Hibernate框架,ORM的概念和Hibernate入门 什么是Hibernate框架? Hib ...
随机推荐
- LeetCode 数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素.请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素. 示例 1: 输入: [3,2,1,5,6,4] 和 k = 2 输出: 5 ...
- perl学习之:函数总结
一.进程处理函数 1.进程启动函数 函数名 eval 调用语法 eval(string) 解说 将string看作Perl语句执行.正确执行后,系统变量$@为空串,如果有错误,$@中为错误信息. 例子 ...
- python中 “==”和"is"的区别
python中 "=="是相等性比较,比较的是两个对象中的值是否相等,而“is”是一致性比较,比较的是两个对象中的内存地址 a = [1, 2, 3] b = a 此时, a == ...
- i.mx53开发的一些问题
i.mx53开发的一些问题 转载于此:http://blog.csdn.net/shell_albert/article/details/8242288 原来i.mx53上4GB的Nand Fla ...
- Hive 启动报错,需先启动元数据
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable ...
- Hive 执行sql命令报错
Failed with exception java.io.IOException:java.lang.IllegalArgumentException: java.net.URISyntaxExce ...
- 00036_private
1.私有private 描述人.Person: 属性:年龄: 行为:说话:说出自己的年龄. class Person { int age; String name; public void show( ...
- joyoi1935 「Poetize3」导弹防御塔
#include <iostream> #include <cstring> #include <cstdio> #include <queue> #i ...
- swift final关键字、?、!可选与非可选符
?符号: 可选型 在初始化时可以赋值为nil !符号: 隐形可选型 类型值不能为nil,如果解包后的可选类型为nil会报运行时错误,主要用在一个变量/常量在定义瞬间完成之后值一定会存在的情况.这主要 ...
- 九度oj 题目1012:畅通工程
题目描述: 某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇.省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路 ...