Python获取 东方财富 7x24小时全球快讯
本文使用的IDE为PyCharm。
1.第三方库
(1)selenium
selenium用来做浏览器自动化,因为这部分信息是动态加载的,不用这种方法读取不到相关数据。
安装:
pip3 install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
然后下载与自己浏览器对应的驱动
火狐浏览器驱动,其下载地址是:https://github.com/mozilla/geckodriver/releases
谷歌浏览器驱动,其下载地址是:http://chromedriver.storage.googleapis.com/index.html?path=2.33/
opera浏览器驱动,其下载地址是:https://github.com/operasoftware/operachromiumdriver/releases
以上是网上有大佬贴出来的下载地址,实际使用需要根据自己电脑上的浏览器版本下载对应的驱动,比如我用的谷歌浏览器,驱动版本不对应会报如下错误:
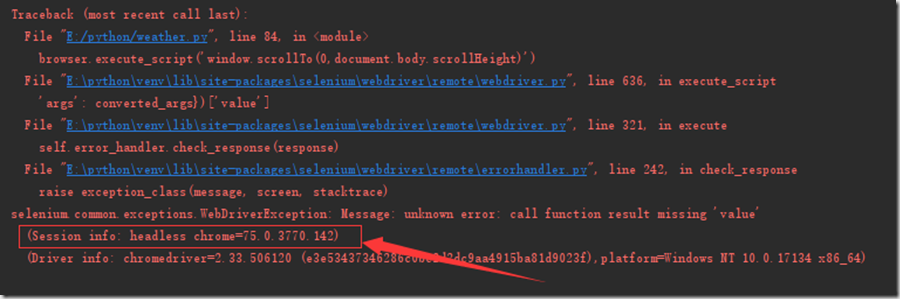
这个时候,我们根据这里报的 chrome=75.0.3770.142去查找对应的驱动版本。驱动版本可到 http://npm.taobao.org/mirrors/chromedriver/ 下载。
我的驱动直接放在文件同目录了:
(2)BeautifulSoup
pip3 install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple
2.网页分析
东方财富 7x24小时全球快讯 的网址是 http://m.eastmoney.com/kuaixun ,这里我想获取三项内容,新闻时间,新闻简介和新闻的链接。
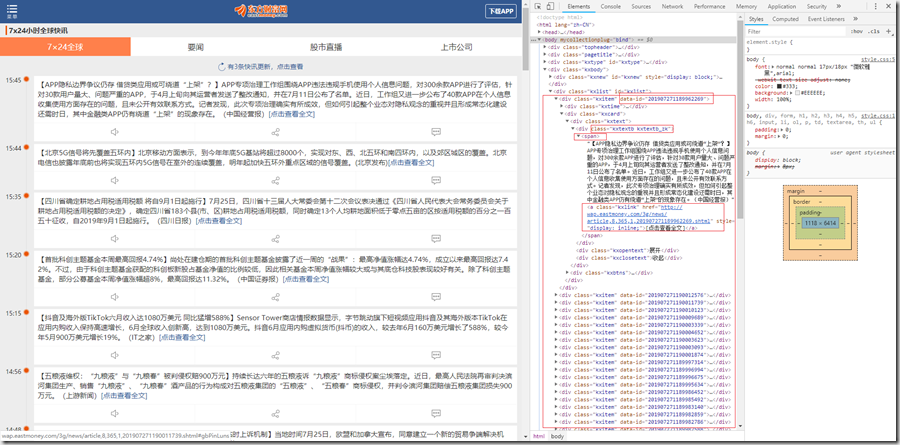
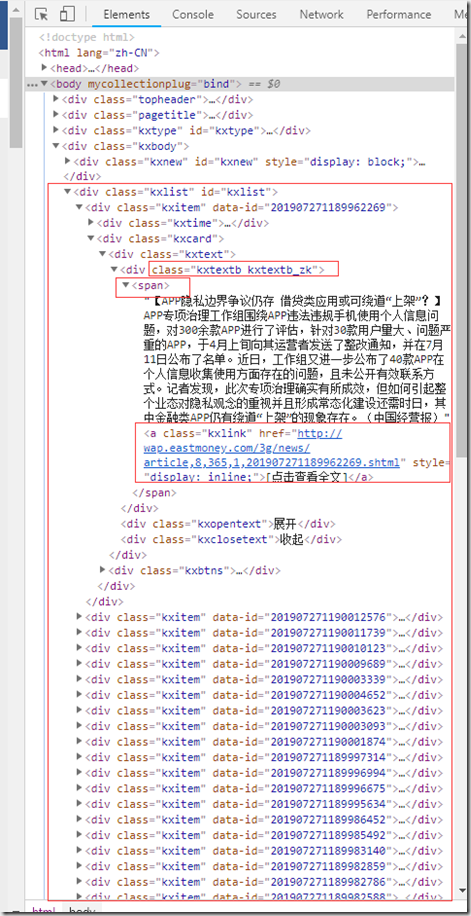
3.代码实现及效果
代码中关键的地方都已经写在注释里面了。
from bs4 import BeautifulSoup
import time;
from selenium import webdriver
from selenium.webdriver.chrome.options import Options chrome_options = Options()
# 设置chrome浏览器无界面模式,不然每运行一次都会弹出来谷歌浏览器界面
# 不过弹出谷歌界面有助于理解为什么下面会有个页面滚动
chrome_options.add_argument('--headless')
# executable_path为驱动地址
browser = webdriver.Chrome(executable_path='./chromedriver.exe', chrome_options=chrome_options)
url = "http://m.eastmoney.com/kuaixun"
browser.get(url)
# 模仿浏览器往下滚动的页面,获取更多的数据
for i in range(1, 5):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(1)
html = BeautifulSoup(browser.page_source, "lxml")
# 退出浏览器
browser.quit()
# print(html)
news_list = html.find_all('div', class_='kxitem')
# print(news_list)
for news in news_list:
print(news['data-id'])
news_text = news.find('span')
news_href = news.find('a')
for s in news_text("a"):
# 去掉span标签中的链接标签
s.extract()
print(news_text.get_text())
print(news_href['href'])
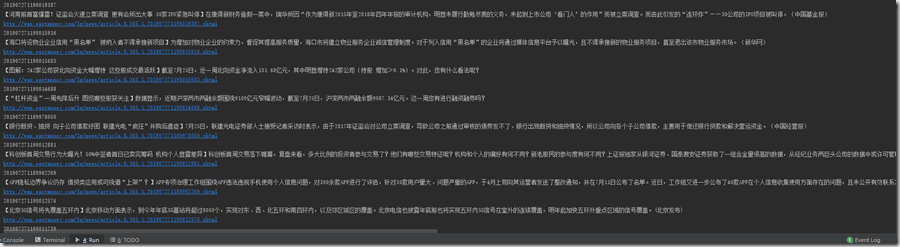
效果:
Python获取 东方财富 7x24小时全球快讯的更多相关文章
- Python Elasticsearch api,组合过滤器,term过滤器,正则查询 ,match查询,获取最近一小时的数据
Python Elasticsearch api 描述:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.下 ...
- python获取时间————前一天后一天前一小时后一小时前一分钟后一分钟
获取当天日期 一: import time print(time.strftime("%Y-%m-%d")) #输出当前日期 2018-05-01 二: import dateti ...
- python 获取日期
转载 原文:python 获取日期 作者:m4774411wang python 获取日期我们需要用到time模块,比如time.strftime方法 time.strftime('%Y-%m-% ...
- Python 获取时间戳
Python 获取时间通过 time 模块 如下代码,是通过获取当前的时间,按照格式输出 Python默认获取当前的时间返回的都是时间的元组,下面是元组的,字符串时间的一个转换输出 # -*- cod ...
- 用 Python 获取 B 站播放历史记录
用 Python 获取 B 站播放历史记录 最近 B 站出了一个年度报告,统计用户一年当中在 B 站上观看视频的总时长和总个数.过去一年我居然在 B 站上看了2600+个视频,总计251个小时,居然花 ...
- python 获取当前时间(关于time()时间问题的重要补充)
python 获取当前时间 我有的时候写程序要用到当前时间,我就想用python去取当前的时间,虽然不是很难,但是老是忘记,用一次丢一次,为了能够更好的记住,我今天特意写下python 当前时间这 ...
- Python获取当前系统时间
Python获取当前系统时间 import time #返回当前时间 def GetNowTime(): return time.strftime("%Y-%m-%d %H:%M:% ...
- Python获取当前时间_获取格式化时间_格式化日期
Python获取当前时间_获取格式化时间: Python获取当前时间: 使用 time.time( ) 获取到距离1970年1月1日的秒数(浮点数),然后传递给 localtime 获取当前时间 #使 ...
- python获取当前时间、今天零点、235959点、昨天当前时间、明天的当前时间
python获取当前时间.今天零点.23:59:59点.昨天当前时间.明天的当前时间. 关注公众号"轻松学编程"了解更多. 获取当前时间.今天零点 使用timedalte. tim ...
随机推荐
- C# 委托实现冒泡排序
委托实现员工根据工资升序排列 首先定义员工类 class Employee { public string Name { get; private set; } public decimal Sala ...
- js原生ajax与jquery的ajax的用法区别
什么是ajax和原理? AJAX 是一种用于创建快速动态网页的技术. 通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据 XMLHttpRequest对象的基本属性: onre ...
- java 内部类简单总结
在java中,一个类可以放在另一个类的内部,称之为内部类,相对而言,包含它的类称之为外部类.不过对于Java虚拟机而言,它是不知道内部类这回事的, 每个内部类最后都会被编译为一个独立的类,生成一个独立 ...
- 【原创】go语言学习(一)
一.go发展历史 1.1诞生历史 1.诞生于2006年1月下午15点4分5秒 2.2009发布并正式开园 3.2012年第一个正式版本Go1.0发布 4.截止2019年10月8日,Go1.13.1 1 ...
- MySQL数据分析-(2)数据库的底层逻辑
(一) 数据库存在的逻辑 1.案例开篇-大部分公司对于数据和数字的管理都是低效率的 我们要学习数据库,就必须要搞清楚数据库是在什么样的情景下发明并流行的?学习新知识就要搞清楚每个知识点的来龙去脉,这样 ...
- python 识别图片中的汉字
我们就识别上面的汉字. 安装软件tesseract和python库 https://www.cnblogs.com/sea-stream/p/10961580.html 然后新建一个文件夹test,把 ...
- Django基础之form表单的补充进阶
1. 应用Bootstrap样式 <!DOCTYPE html> <html lang="en"> <head> <meta charse ...
- ORM SQLAlchemy - 建立一个关系 relationship
relationship函数是sqlalchemy对关系之间提供的一种便利的调用方式, backref参数则对关系提供反向引用的声明 1 背景 如没有relationship,我们只能像下面这样调用关 ...
- CISCO实验记录十:switch基本配置
1.交换机IP配置 2.配置telnet 1.交换机IP配置 #interface vlan 1 #ip address 192.168.0.3 255.255.255.0 #no shutdown ...
- ScvQ常用的网站(持续更新...)
GitHub:https://github.com/ScvQ 幕课网:https://www.imooc.com/u/4659537/courses 免费的SS:https://global.isha ...