filebeat的层次架构图和配置部署 -- 不错的文档 - elasticsearch 性能调优 + Filebeat配置
1.fielbeat的组件架构-看出层次感
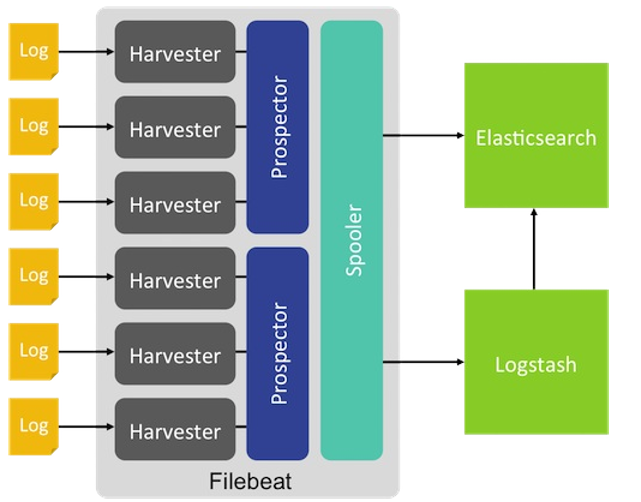
2.工作流程:每个harvester读取新的内容一个日志文件,新的日志数据发送到spooler(后台处理程序),它汇集的事件和聚合数据发送到你已经配置了Filebeat输出。
参考:https://blog.csdn.net/gamer_gyt/article/details/52688636
3.安装配置
tar xvf filebeat-6.4.-linux-x86_64.tar.gz
cp /usr/local/src/filebeat-6.4.-linux-x86_64/filebeat.yml /usr/local/src/filebeat-6.4.-linux-x8
6_64/filebeat.yml.default
cd /usr/local/src/filebeat-6.4.-linux-x86_64/
[root@VM_0_6_centos filebeat-6.4.-linux-x86_64]# cat filebeat.yml
filebeat.inputs:
- type: log enabled: true paths:
- /tmp/messages
fields_under_root: true filebeat.config.modules: path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.elasticsearch:
hosts: ["10.0.0.92:9200"]
4. 报错
Filebeat配置检测报 “setup.template.name and setup.template.pattern have to be set if index name is modified” 错误
解决方案:这个错误本身提示很明显,只要我们配置了索引名格式,就必须要同时配置setup.template.name 和setup.template.pattern,但是,我配置了这两项怎么还是不行呢,还是同样的错误,重点来了:这两项的配置必须要顶格配置,不可以和index对齐写到一个缩进级别!这个是很容易写错的,大家注意!正确的写法:
--------------------- index默认就可以了,不用配置
原文:https://blog.csdn.net/yk20091201/article/details/90756738
别人的配置文件
filebeat.inputs:
- type: log enabled: true
paths:
- /usr/local/analyzer/test.log
json.keys_under_root: true
json.add_error_key: true
json.overwrite_keys: true
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["192.168.0.81:9200"]
index: "filebeat-testindex-%{+yyyy.MM.dd}"
setup.template.name: "filebeattest"
setup.template.pattern: "filebeattest-*" 原文:https://blog.csdn.net/yk20091201/article/details/90756738
#############################################
不错的文档
https://www.cnblogs.com/cjsblog/p/9517060.html
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
# 要抓取的文件路径
paths:
- /data/logs/oh-coupon/info.log
- /data/logs/oh-coupon/error.log
# 添加额外的字段
fields:
log_source: oh-coupon
fields_under_root: true
# 多行处理
# 不以"yyyy-MM-dd"这种日期开始的行与前一行合并
multiline.pattern: ^\d{}-\d{,}-\d{,}
multiline.negate: true
multiline.match: after # 5秒钟扫描一次以检查文件更新
scan_frequency: 5s
# 如果文件1小时都没有更新,则关闭文件句柄
close_inactive: 1h
# 忽略24小时前的文件
#ignore_older: 24h - type: log
enabled: true
paths:
- /data/logs/oh-promotion/info.log
- /data/logs/oh-promotion/error.log
fields:
log_source: oh-promotion
fields_under_root: true
multiline.pattern: ^\d{}-\d{,}-\d{,}
multiline.negate: true
multiline.match: after
scan_frequency: 5s
close_inactive: 1h
ignore_older: 24h #================================ Outputs ===================================== #-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"] # Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme" #----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"] # Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
filebeat的层次架构图和配置部署 -- 不错的文档 - elasticsearch 性能调优 + Filebeat配置的更多相关文章
- tomcat7性能调优与配置(以windows版为例)
一.配置tomcat服务状态查看帐号(E:\Tomcats\apache-tomcat-7.0.73Test\conf下面的tomcat-users.xml中)加入:<user username ...
- 转【Zabbix性能调优:配置优化】
转载:https://sre.ink/zabbix-turn-conf/ #通过日志可以分析当前服务状态.LogFile=/tmp/zabbix_server.log #日志文件路径.LogFileS ...
- PHP性能调优---PHP-FPM配置及使用总结
PHP-FPM配置及使用总结: php-FPM是一个PHP FastCGI的管理器,它实际上就是PHP源代码的补丁,旨在将FastCGI进程管理引进到PHP软件包中,我们必须将其patch到PHP源代 ...
- MySQL架构优化实战系列2:主从复制同步与查询性能调优
- MySQL性能调优与架构设计——第 17 章 高可用设计之思路及方案
第 17 章 高可用设计之思路及方案 前言: 数据库系统是一个应用系统的核心部分,要想系统整体可用性得到保证,数据库系统就不能出现任何问题.对于一个企业级的系统来说,数据库系统的可用性尤为重要.数据库 ...
- MySQL性能调优与架构设计——第 18 章 高可用设计之 MySQL 监控
第 18 章 高可用设计之 MySQL 监控 前言: 一个经过高可用可扩展设计的 MySQL 数据库集群,如果没有一个足够精细足够强大的监控系统,同样可能会让之前在高可用设计方面所做的努力功亏一篑.一 ...
- MySQL性能调优与架构设计——第4章 MySQL安全管理
第4章 MySQL安全管理 前言 对于任何一个企业来说,其数据库系统中所保存数据的安全性无疑是非常重要的,尤其是公司的有些商业数据,可能数据就是公司的根本,失去了数据的安全性,可能就是失去了公司的一切 ...
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
- MySQL性能调优与架构设计——第 16 章 MySQL Cluster
第 16 章 MySQL Cluster 前言: MySQL Cluster 是一个基于 NDB Cluster 存储引擎的完整的分布式数据库系统.不仅仅具有高可用性,而且可以自动切分数据,冗余数据等 ...
随机推荐
- 51nod 1172 Partial Sums V2
题目 给出一个数组A,经过一次处理,生成一个数组S,数组S中的每个值相当于数组A的累加,比如:A = {1 3 5 6} => S = {1 4 9 15}.如果对生成的数组S再进行一次累加操作 ...
- 对Sting类型的探讨
string类型经常和基本数据类型一起被我们熟练运用,但却不被归为基本数据类型,他是特殊的引用类型.引用数据类型还有类,接口.数组.枚举类型和注解类型. 我们来看下jdk对他的解释: String是在 ...
- SpringMVC——入门
一.SpringMVC介绍: Spring Web MVC是一种基于Java的实现了Web MVC设计模式的请求驱动类型的轻量级Web框架,即使用了MVC架构模式的思想,将web层进行职责解耦,基于请 ...
- Android学习_Selector
Selector 实现组件在不同状态下不同的文字颜色.背景颜色或图片的切换,使用十分方便. 1. 创建方法 第一种:在XML中直接创建selector的XML文件,容易掌握,简单但是不灵活,较为常用. ...
- smarty逻辑运算符
smarty逻辑运算符 eq equal : 相等 neq not equal:不等于 gt greater than:大于 lt less th ...
- readerwriterqueue 一个用 C++ 实现的快速无锁队列
https://www.oschina.net/translate/a-fast-lock-free-queue-for-cpp?cmp&p=2 A single-producer, sing ...
- HearthBuddy卡组
偶数萨 手打两天已上传说,各位加油 欧洲牧羊人 ### 火元素换艾雅# 职业:萨满祭司# 模式:狂野模式## 2x (2) 图腾魔像 # 2x (2) 大漩涡传送门 # 2x (2 ...
- vue 指示点的疑点拓展
1. 为什么 vue 组件中的 data 是一个函数 1. 为了保证组件的独立性和可复用性,data 是一个函数,组件实例的时候,这个函数将会被调用,返回一个对象,计算机会给这个对象分配一个内存地址, ...
- tomcat8踩坑:url包含|等特殊字符报错400的问题
这个问题纠缠了我很久了,终于在今天早上解决了,感谢自己的不放弃和不断尝试的决心,我坚信,我可以找到解决方式!! 项目用的spring boot+spring security框架,关于统一错误页面在开 ...
- Service-stack.redis 使用PooledRedisClientManager 速度慢的原因之一
现在越来越多的开发者使用service-stack.redis 来进行redis的访问,但是获取redisclient的方式有多种方式,其中有一种从缓冲池获取client的方式很是得到大家的认可. L ...