笔记-4:python组合数据类型
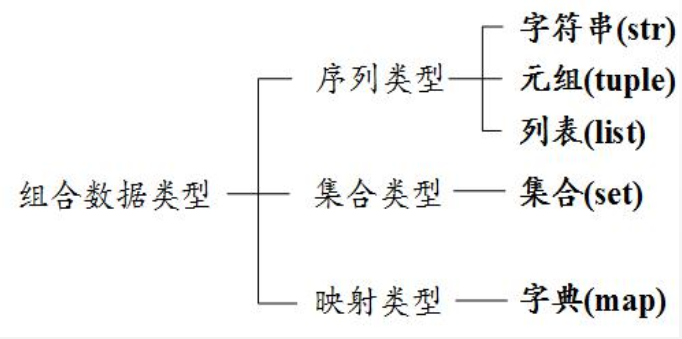
1.字符串(str)
- 字符串是字符的序列表示, 根据字符串的内容多少分为单行字符串和多行字符串。
- 单行字符串可以由一对单引号(') 或双引号(")作为边界来表示, 单引号和双引号作用相同。
- 多行字符串可以由一对三单引号(''') 或三双引号(""") 作为边界来表示, 两者作用相同。
print('这是"单行字符串"')
print("这是'单行字符串'")
print("""这是'多行字符串'的第一行
这是'多行字符串'的第二行""")
print('''这是"多行字符串"的第一行
这是"多行字符串"的第二行''')
- python转义符:
| 转义符 | 作用 |
| \n | 换行 |
| \ | 反斜杠 |
| \‘ | 单引号 |
| \" | 双引号 |
| \t | 制表符 |
1.1 字符串的索引

字符串最左端位置标记为0, 依次增加。 对字符串中某个字符的检索被称为索引。
如果字符串长度为L, 正向递增需要以最左侧字符序号为0,向右依次递增, 最右侧字符序号为L-1;
反向递减序号以最右侧字符序号为-1, 向左依次递减, 最左侧字符序号为-L。
字符串以Unicode编码存储, 字符串的英文字符和中文字符都算作1个字符。
<字符串或字符串变量>[序号]
# 正数索引取值从左到右,下标从0开始
# 负数索引取值从右到左,下标从-1开始 a = 'HelloWorld'
print(a[0])
1.2 字符串的切片
- 对字符串中某个子串或区间的检索被称为切片。
<字符串或字符串变量>[N: M]
# [N: M]--->左闭右开 a = '青青子衿,悠悠我心'
print(a[:4])
print(a[0:5])
print(a[5:])
print(a[-1:])
print(a[5:-1])
1.3 字符串的操作符
# 字符串相加
x + y # 复制n次字符串x
x * n或n * x # 如果x是s的子串,返回True,否则返回False
x in s
1.4 字符串的处理函数
# len(x):返回字符串x的长度,也可以返回其他数据类型的元素个数。
print(len('Hello World')) # str(x):返回任意类型x所对应的字符串形式。
print(str('helloworld')) # chr(x):返回Unicode编码x对应的单字符
print(chr(10000)) # ord(x):返回单字符x表示的Unicode编码
print(ord('✐')) # hex(x):返回整数x对应的十六进制数的小写形式字符串。
print(hex(10020)) # oct(x):返回整数x对应八进制数的小写形式字符串
print(oct(10020))
1.5 字符串的处理方法
# str.lower():将字符串全部小写。
str = 'HelloWorld'
print(str.lower()) # str.upper():就字符串全部大写。
str = 'HelloWorld'
print(str.upper()) # str.split(sep=None):分割字符串,返回一个列表。
str = 'Hello World'
print(str.split(sep=' ')) # str.count(sub):返回sub子串出现的次数。
str = 'Hello World'
print(str.count('l')) # str.replace(old,new):将old子串被替换为new。
str = 'Hello World'
print(str.replace('l','o')) # str.center(width,fillchar):字符串居中函数, fillchar参数可选。
str = 'HelloWorld'
print(str.center(20, '=')) # str.strip(chars):从字符串str中去掉在其左侧和右侧chars中列出的字符。
str = ' ==python== '
print(str.strip(' '))
str = ' ==python== '
print(str.strip(' =')) # str.join(iter):将iter变量的每一个元素后增加一个str字符串。
print(','.join(''))
print(','.join(['','','','']))
1.6 format()方法的基本使用
基本使用格式:
<模板字符串>.format(<逗号分隔的参数>)
# 模板字符串是一个由字符串和槽组成的字符串, 用来控制字符串和变量的显示效果。槽用大括号({})表示, 对应format()方法中逗号分隔的参数。
print("{}曰: 学而时习之, 不亦说乎。 ".format("孔子"))
# 如果模板字符串有多个槽, 且槽内没有指定序号,则按照槽出现的顺序分别对应.format()方法中的不同参数。
print("{}曰: 学而时习之, 不亦{}。 ".format("孔子","说乎"))
# 通过format()参数的序号在模板字符串槽中指定参数的使用, 参数从0开始编号
print("{1}曰: 学而时习之, 不亦{0}。 ".format("说乎","孔子"))
format()方法的格式控制:{<参数序号>:<格式控制标记>}
# 左对齐(默认):<
print("{:<10}".format("好好学习"))
# 居中对齐:^
print("{:^10}".format("好好学习"))
# 右对齐:>
print("{:>10}".format("好好学习"))
# 居中对齐且填充*号
print("{:*^25}".format("好好学习"))
# 居中对齐且填充+号
print("{:+^25}".format("好好学习"))
# 保留小数点后2位
print("{:.2f}".format(12345.67890))
# 右对齐保留小数点后3位
print("{:>25.3f}".format(12345.67890))
# 取字符串的前5位
print("{:.5}".format("全国计算机等级考试"))
# b: 输出整数的二进制方式;
# c: 输出整数对应的Unicode字符;
# d: 输出整数的十进制方式;
# o: 输出整数的八进制方式;
# x: 输出整数的小写十六进制方式;
# X: 输出整数的大写十六进制方式;
print("{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425))
# e: 输出浮点数对应的小写字母e的指数形式;
# E: 输出浮点数对应的大写字母E的指数形式;
# f: 输出浮点数的标准浮点形式;
# %: 输出浮点数的百分形式。
print("{0:e},{0:E},{0:f},{0:%}".format(3.14))
2.元组(tuple)
- 元组类型用小括号()表示,也可以通过tuple(x)函数将字符串或列表转换成为元组类型。
- 元组是不可变序列类型,不能修改元组中的元素,因此元组没有增加元素,修改元素,删除元素相关的方法。
- 如果需要增加,修改,删除元素,可以先将其转换为列表。
print((1,)) # 定义一个唯一元素的元组,需要在元素后面加一个','
print((1,2,'Hello','你好','='))
2.1 元组的索引
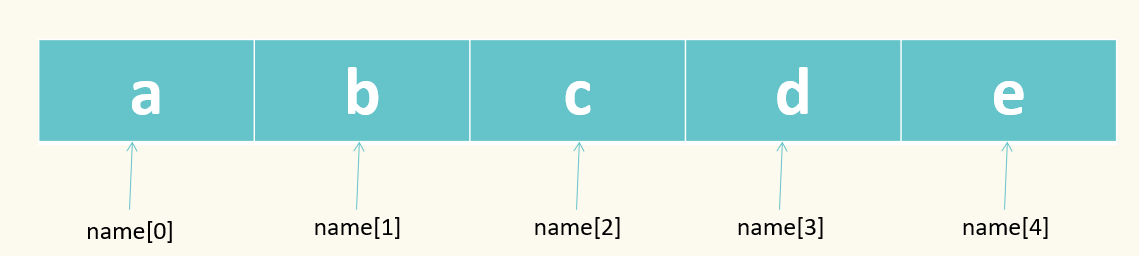
a=(1,2,'你好','HelloWorld')
b=a[0]
print(b)
r = (1,2,'Hello','你好','=')
print(type(r))
for i in r:
print(i)
2.2 元组的切片
a=(1,2,4,5,'你好','HelloWorld')
print(a[0:5:2])
(1, 4, '你好')
2.3 元组的操作函数和方法
a_tuple = (1,2,3,4,1) # a.count(x):查询元组a中元素x的个数
print(a_tuple.count(1)) # a.index(x):查询元组a中元素x的下标
print(a_tuple.index(1)) # a.index(x,start,end:查询元组a中[start,end]区间的元素x的下标
print(a_tuple.index(2,0,2)) # a.index(x,x):查询元组a中两个相同元素之间最后一个元素x的下标
print(a_tuple.index(1,1)) # len(a):查询元组的长度
print(len(a_tuple)) # max(a):查询元组a中元素的最大值
print(max(a_tuple)) # min(a):查询元组a中元素的最小值
print(min(a_tuple)) # sum(a):求和
print(sum(a_tuple))
# 如果需要对元组进行排序,只能使用内置函数sorted(tupleObj),生成新的列表对象,从而进行排序
a = (1,2,3,4,1)
print(sorted(a))
3.列表(list)
列表类型用中括号([]) 表示, 也可以通过list(x)函数将集合或字符串类型转换成列表类型 。
列表没有长度限制, 元素类型可以不同, 不需要预定义长度 。
列表可以由字符串生成。
列表属于序列类型, 所以列表类型支持序列类型对应的操作 。
print([1,2,3,4])
print(list('列表可以由字符串生成'))
3.1 列表的索引
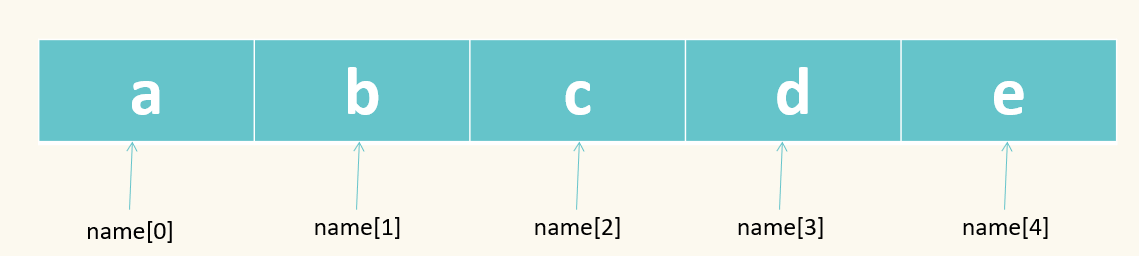
# 索引是列表的基本操作, 用于获得列表的一个元素。 使用中括号作为索引操作符。
r = [1010, "", [1010, ""], 1010]
print(r[3])
print(r[-2])
# 使用遍历循环对列表类型的元素进行遍历操作。
for <循环变量> in <列表变量>:
<语句块> r = [1010, "", [1010, ""], 1010]
for i in r:
print(i)
3.2 列表的切片
# 切片是列表的基本操作, 用于获得列表的一个片段, 即获得一个或多个元素。
<列表或列表变量>[N: M]
或
<列表或列表变量>[N: M: K] # 切片获取列表类型从N到M(不包含M) 的元素组成新的列表。
# 当K存在时,切片获取列表类型从N到M(不包含M) 以K为步长所对应元素组成的列表。
ls = [1010, "", [1010, ""], 1010]
print(ls[1:4])
print(ls[-1:-3])
print(ls[0:4:2])
3.3 列表的操作函数
s = [1, 2, 3, 4, 5, 6] # len(s):列表s的元素个数(长度)
print(len(s)) # min(s):列表s的最小元素
print(min(s)) # max(s):列表s的最大元素
print(max(s)) # list(x):将x转换为列表类型
x = 'abc'
print(list(x))
3.4 列表的操作方法
ls = [1,2,5,9,40] # ls.append(x):在列表ls最后增加一个元素x。
ls.append('') # ls.insert(i,x):在列表ls第i位增加一个元素x。
ls.insert(1,10) # ls.clear():删除ls中所有的元素
ls.clear() # ls.pop(i):将列表ls中第i项元素取出并删除该元素。
ls.pop(0) # ls.remove(x):将列表中出现的第一个x元素删除
ls.remove(1) # ls.reverse():列表ls中元素反转。
ls.reverse() # ls.copy():生成一个新列表,复制ls中所有的元素
ls.copy()
# 使用del对列表元素或片段进行删除
del <列表变量>[<索引序号>]
或
del <列表变量>[<索引起始>: <索引结束>] lt = ["", "10.10", "Python"]
del lt[1]
del lt[1:]
# 使用索引配合等号(=) 可以对列表元素进行修改。
lt = ["", "10.10", "Python"]
lt[1] = 100
4.集合(set)
集合是无序组合, 用大括号({}) 表示, 它没有索引和位置的概念, 集合中元素可以动态增加或删除 。
集合中元素不可重复, 元素类型只能是固定数据类型。整数、 浮点数、 字符串、 元组等, 列表、 字典和 集合类型本身都是可变数据类型, 不能作为集合的元素出现。
由于集合元素是无序的, 集合的打印效果与定义顺序可以不一致。
由于集合无序且唯一,所以使用集合类型能够过滤掉重复元素。
T = {1010, "", 12.3, 1010, 1010}
print(T)
4.1 集合类型操作符
- 集合类型有4个操作符, 交集(&) 、 并集(|) 、 差集(-) 、 补集(^)
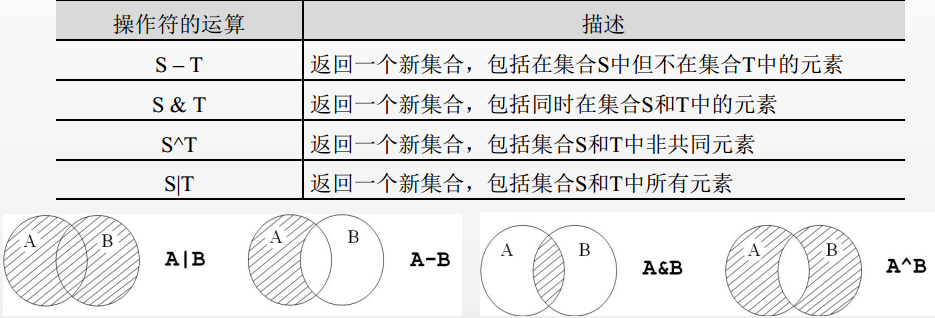
S = {1,5,9,10,20,30}
T = {2,10,20,30,40,50}
print(S - T)
print(T - S)
print(S & T)
print(S ^ T)
print(S | T)
4.2 集合的操作函数和方法
s = {1,5,9,10,20,30}
# s.add(x):如果数据项x不在集合s中,将增加x到s。
s.add(100)
# s.remove(x):如果x在集合s中,移除x;不在产生KeyError异常
s.remove(100)
# s.clear():移除集合s中所有的数据项。
s.clear()
# len(s):返回集合s元素个数。
len(s)
# x in s:如果x是S的元素, 返回True, 否则返回False
1 in s
# x not is s: 如果x不是S的元素, 返回True, 否则返回False
1 not is s
4.3 元素去重
s = set('知之为知之不知为不知')
for i in s:
print(i, end="")
5.字典(dict)
字典使用大括号{}建立, 每个元素是一个键值对 。
键和值通过冒号连接, 不同键值对通过逗号隔开。
键值对之间没有顺序且不能重复。
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
d = {"":"小明", "":"小红", "":"小白"}
print(d)
5.1 字典的索引
- 字典元素“键值对” 中键是值的索引, 因此, 可以直接利用键值对关系索引元素。
<值> = <字典变量>[<键>]
d = {"":"小明", "":"小红", "":"小白"}
print(d[201801])
- 利用索引和赋值(=) 配合, 可以对字典中每个元素进行修改。
d[""] = '新小红'
print(d)
- 使用大括号可以创建字典。 通过索引和赋值配合,可以向字典中增加元素。
t = {}
t[""] = "小小"
print(d)
5.2 字典的操作函数
# len(d):字典d的元素个数(长度)
print(len(d)) # min(d):字典d中键的最小值
print(min(d)) # max(d):字典d中键的最大值
print(max(d)) # dict():生成一个空字典
a = dict()
print(type(a))
5.3 字典的操作方法
# d.keys():返回所有的键信息
print(d.keys()) # d.values():返回所有的值信息
print(d.values()) # d.items():返回所有的键值对
print(d.items()) # d.get(key,default):键存在则返回相应值, 否则返回默认值
print(d.get(key,default)) # d.pop(key,default):键存在则返回相应值, 同时删除键值对, 否则返回默认值
print(d.pop(key,default)) # d.popitem():随机从字典中取出一个键值对, 以元组(key, value)形式返回
print(d.popitem()) # d.clear():删除所有的键值对
d.clear()
# 所有保留字del删除某一个元素
d = {"":"小明", "":"小红", "":"小白"}
del d[""]
# 使用保留字in,判断一个键是否在字典中。
d = {"":"小明", "":"小红", "":"小白"}
print("" in d)
5.4 字典的循环遍历
for <变量名> in <字典名>
<语句块> # for循环返回的变量名是字典的索引值。 如果需要获得键对应的值, 可以在语句块中通过get()方法获得。
d = {"":"小明", "":"小红", "":"小白"}
for k in d:
print("字典的键和值分别是: {}和{}".format(k, d.get(k)))
笔记-4:python组合数据类型的更多相关文章
- Python学习笔记(六)Python组合数据类型
在之前我们学会了数字类型,包括整数类型.浮点类型和复数类型,这些类型仅能表示一个数据,这种表示单一数据的类型称为基本数据类型.然而,实际计算中却存在大量同时处理多个数据的情况,这种需要将多个数据有效组 ...
- python组合数据类型和数据结构
//2019.12-071.pyhton里面组合数据类型主要有三种:集合(set).序列(字符串str.列表list and 元组tuple)和映射(字典dic)2.集合类型一般使用大括号{}来进行表 ...
- [python学习手册-笔记]002.python核心数据类型
python核心数据类型 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明 ...
- 学习笔记28—Python 不同数据类型取值方法
1.array数据类型 1)-------> y[i,] 或者 y[i] 2.遍历目录下所有文件夹: def eachFile(filepath): pathDir = os.list ...
- python的组合数据类型及其内置方法说明
python中,数据结构是通过某种方式(例如对元素进行编号),组织在一起数据结构的集合. python常用的组合数据类型有:序列类型,集合类型和映射类型 在序列类型中,又可以分为列表和元组,字符串也属 ...
- Python编程从入门到实践笔记——变量和简单数据类型
Python编程从入门到实践笔记——变量和简单数据类型 #coding=gbk #变量 message_1 = 'aAa fff' message_2 = 'hart' message_3 = &qu ...
- Python Revisited Day 03 (组合数据类型)
目录 第三章 组合数据类型 3.1 序列类型 3.1.1 元组 3.1.2 命名的元组 (collections.nametuple()) 3.1.3 列表 (查询有关函数点这) 3.1.4 列表内涵 ...
- Python字符串、组合数据类型练习
一.Python字符串练习 1.http://news.gzcc.cn/html/2017/xiaoyuanxinwen_1027/8443.html 取得校园新闻的编号. (这个方法就很多了,一般方 ...
- Python组合类型笔记
Python中常用的三种组合数据类型,分别是: - 集合类型 - 序列类型 - 字典类型 1. 集合类型: -集合用大括号{}表示,元素间用逗号分隔 -建立集合类型用{}或set() -建立空集合类型 ...
随机推荐
- springboot 出现 org.hibernate.LazyInitializationException: could not initialize proxy
org.hibernate.LazyInitializationException: could not initialize proxy [com.example.shop.dataobject.U ...
- Hive-概述
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计. Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能. 本质是:将 ...
- MongoDB(mongodb-win32-x86_64-enterprise-windows-64-4.2.1-signed.msi)下载,启动和插入数据,查询
下载链接:https://pan.baidu.com/s/19lM5Q-_BaDbjaO1Pj0SbYg&shfl=sharepset 安装一路Next就行,安装完毕后,进入目录C:\Prog ...
- 文件转移 互联网组成 路由器 分组交换 交换机 冲突域 网卡 数据帧的发送与接收会带来CPU开销 CPU中断 双网卡切换
https://zh.wikipedia.org/zh-cn/网段 在以太网环境中,一个网段其实也就是一个冲突域(碰撞域).同一网段中的设备共享(包括通过集线器等设备中转连接)同一物理总线,在这一总线 ...
- vue常用的修饰符
v-model修饰符 <template> <div id="demo14"> <p>-----------------模板语法之修饰符---- ...
- C之堆栈
栈* 自动申请,自动释放* 大小固定,内存空间连续* 从栈上分配的内存叫静态内存 堆* 程序员自己申请* new/malloc* 大小取决于虚拟内存的大小,内存空间不连续* java中自动回收,C中需 ...
- 001-log-log体系-log4j、jul、jcl、slf4j,日志乱象的归纳与统一
一.概述 log4j→jul→jcl→slf4j之后就开始百花齐放[slf4j适配兼容新老用户] 1.1.log4j阶段 在JDK出现后,到JDK1.4之前,常用的日志框架是apache的log4j. ...
- Java实现ModbusTCP通信
一个项目,需要用Java实现使用ModbusTCP和硬件设备通信 资料 代码下载 本文的代码和仿真软件:蓝奏云下载 官网资料 Modbus官网 Modbus协议 Modbus技术资源 MODBUS T ...
- PAT 甲级 1028 List Sorting (25 分)(排序,简单题)
1028 List Sorting (25 分) Excel can sort records according to any column. Now you are supposed to i ...
- LeetCode_13. Roman to Integer
13. Roman to Integer Easy Roman numerals are represented by seven different symbols: I, V, X, L, C, ...