利用pyltp进行实体识别
一.实体识别作为信息抽取中基础的也是重要的一步,其技术可以分为三类,分别是其于规则的方法、其于统计模型的方法以及基于深度学习的方法。
基于规则的方法,主要依靠构建大量的实体抽取规则,一般由具有一定领域知识的专家手工构建。然后将规则与文本进行匹配,识别出实体。
基于统计的方法,需要一定的标注语料进行训练,采用的基本模型有马尔可夫HMM、条件马尔可夫CMM、最大熵ME以及条件随机场CRF等,这此方法作为序列标注问题进行处理,主要涉及步骤有语料标注、特征定义和模型训练。
基于深度的方法,也是目前比较大热的研究方向。最常用的也是大家熟悉的模型有LSTM-CRF、LSTM-CNN-CRF以及基于attention注意力机制的方法等。
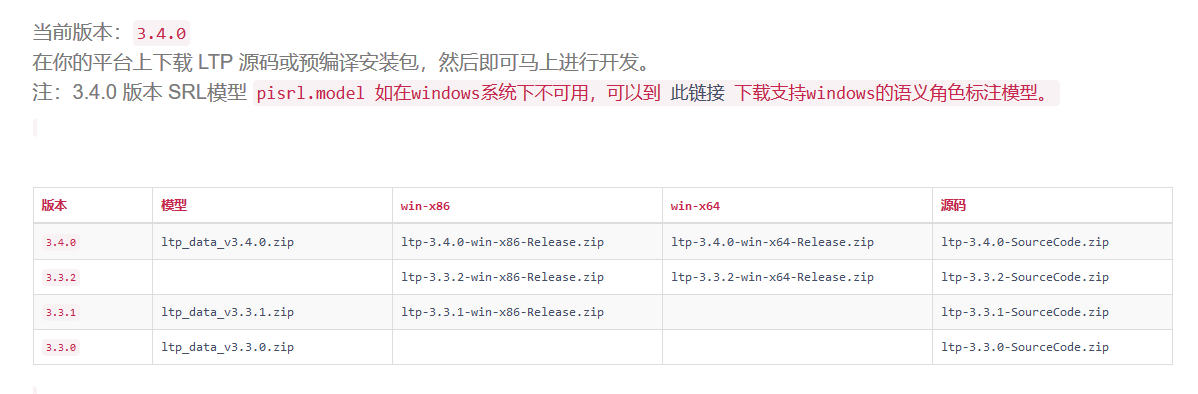
下面初步使用哈工大的pyltp进行实体识别的程序,程序开始前需要下载官方的一些模型有分词模型“cws.model”,词性标注模型“pos.model”以及实体识别模型“ner.model“。
下面是pyltp官网的模型下载页面,地址是http://ltp.ai/download.html。
二.程序
# -*- coding: utf-8 -*-
import os
from pyltp import Segmentor, Postagger, Parser, NamedEntityRecognizer
from collections import OrderedDict class LtpParser():
def __init__(self):
LTP_DIR = "../ltp_model"
self.segmentor = Segmentor()
self.segmentor.load_with_lexicon(os.path.join(LTP_DIR, "cws.model"), os.path.join(LTP_DIR, "word_dict.txt")) #加载外部词典 self.postagger = Postagger()
self.postagger.load_with_lexicon(os.path.join(LTP_DIR, "pos.model"), os.path.join(LTP_DIR, "n_word_dict.txt")) #加载外部词典 # self.parser = Parser()
# self.parser.load(os.path.join(LTP_DIR, "parser.model")) #依存句法分析 self.recognizer = NamedEntityRecognizer()
self.recognizer.load(os.path.join(LTP_DIR, "ner.model"))#实体识别 # #加载停词
# with open(LTP_DIR + '/stopwords.txt', 'r', encoding='utf8') as fread:
# self.stopwords = set()
# for line in fread:
# self.stopwords.add(line.strip()) '''把实体和词性给进行对应'''
def wordspostags(self, name_entity_dist, words, postags):
pre = ' '.join([item[0] + '/' + item[1] for item in zip(words, postags)])
post = pre
for et, infos in name_entity_dist.items():
if infos:
for info in infos:
post = post.replace(' '.join(info['consist']), info['name'])
post = [word for word in post.split(' ') if len(word.split('/')) == 2 and word.split('/')[0]]
words = [tmp.split('/')[0] for tmp in post]
postags = [tmp.split('/')[1] for tmp in post] return words, postags '''根据实体识别结果,整理输出实体列表'''
def entity(self, words, netags, postags):
'''
:param words: 词
:param netags: 实体
:param postags: 词性
:return:
'''
name_entity_dict = {}
name_entity_list = []
place_entity_list = []
organization_entity_list = []
ntag_E_Nh = ""
ntag_E_Ni = ""
ntag_E_Ns = ""
index = 0
for item in zip(words, netags):
word = item[0]
ntag = item[1]
if ntag[0] != "O":
if ntag[0] == "S":
if ntag[-2:] == "Nh":
name_entity_list.append(word + '_%s ' % index)
elif ntag[-2:] == "Ni":
organization_entity_list.append(word + '_%s ' % index)
else:
place_entity_list.append(word + '_%s ' % index)
elif ntag[0] == "B":
if ntag[-2:] == "Nh":
ntag_E_Nh = ntag_E_Nh + word + '_%s ' % index
elif ntag[-2:] == "Ni":
ntag_E_Ni = ntag_E_Ni + word + '_%s ' % index
else:
ntag_E_Ns = ntag_E_Ns + word + '_%s ' % index
elif ntag[0] == "I":
if ntag[-2:] == "Nh":
ntag_E_Nh = ntag_E_Nh + word + '_%s ' % index
elif ntag[-2:] == "Ni":
ntag_E_Ni = ntag_E_Ni + word + '_%s ' % index
else:
ntag_E_Ns = ntag_E_Ns + word + '_%s ' % index
else:
if ntag[-2:] == "Nh":
ntag_E_Nh = ntag_E_Nh + word + '_%s ' % index
name_entity_list.append(ntag_E_Nh)
ntag_E_Nh = ""
elif ntag[-2:] == "Ni":
ntag_E_Ni = ntag_E_Ni + word + '_%s ' % index
organization_entity_list.append(ntag_E_Ni)
ntag_E_Ni = ""
else:
ntag_E_Ns = ntag_E_Ns + word + '_%s ' % index
place_entity_list.append(ntag_E_Ns)
ntag_E_Ns = ""
index += 1
name_entity_dict['nhs'] = self.modify(name_entity_list, words, postags, 'nh')
name_entity_dict['nis'] = self.modify(organization_entity_list, words, postags, 'ni')
name_entity_dict['nss'] = self.modify(place_entity_list, words, postags, 'ns')
return name_entity_dict def modify(self, entity_list, words, postags, tag):
modify = []
if entity_list:
for entity in entity_list:
entity_dict = {}
subs = entity.split(' ')[:-1]
start_index = subs[0].split('_')[1]
end_index = subs[-1].split('_')[1]
entity_dict['stat_index'] = start_index
entity_dict['end_index'] = end_index
if start_index == entity_dict['end_index']:
consist = [words[int(start_index)] + '/' + postags[int(start_index)]]
else:
consist = [words[index] + '/' + postags[index] for index in
range(int(start_index), int(end_index) + 1)]
entity_dict['consist'] = consist
entity_dict['name'] = ''.join(tmp.split('_')[0] for tmp in subs) + '/' + tag
modify.append(entity_dict)
return modify '''词性和实体'''
def post_ner(self, words):
postags = list(self.postagger.postag(words))
# words_filter =[]
# postags = []
# for word, postag in zip(words, self.postagger.postag(words)):
# if 'n' in postag:
# postags.append(postag)
# words_filter.append(word)
nerags = self.recognizer.recognize(words, postags)
return postags, nerags def parser_process(self, sentence):
words = list(self.segmentor.segment(sentence))
post, ner = self.post_ner(words) # 词性和实体
name_entity_dist = self.entity(words, ner, post)
words, postags = self.wordspostags(name_entity_dist, words, post)
return words, postags if __name__ == '__main__':
content_1 = '提起本山传媒,相信大家应该再熟悉不过了。近日,文化产业新闻查询资料显示,赵本山旗下的本山传媒有限公司,在今年的8月1号已经改名,改成了辽宁民间艺术团有限公司,去掉了赵本山的效应。而此前很多以赵本山名字冠名的组织,也已经更名了。 此前在2015年6月9日,辽宁大学官宣将辽宁大学本山艺术学院更名为辽宁大学艺术学院。 其实,公司改名也早有预料,这几年本山传媒的演员参加《欢乐喜剧人》《喜剧总动员》等综艺节目时,一直都宣称来自辽宁民间艺术团,杨树林更是以团长自居。 据文化产业新闻查询,本山传媒是以辽宁民间艺术团为核心组建成的大型文化产业集团,由表演艺术家赵本山任集团董事长。被文化部授予“文化企业三十强”。本山传媒前身为辽宁民间艺术团,成立于2003年,是辽宁省文化厅直属的民营文化企业。 本山传媒是集演艺、影视、艺术教育于一身的大型文化产业集团。2004年,被文化部授予首批“文化产业示范基地”;2010年,“刘老根大舞台”被文化部、国家旅游局联合评为首批“国家文化旅游重点项目”;2010年起连续三年被中宣部评为“全国文化企业三十强”。 本山传媒拍摄有“刘老根”“乡村爱情故事”“马大帅”等享誉全国的优秀影视作品。 改名后的“本山传媒”股东结构如何? 虽然改名了,但持股人都是赵本山和马立娟,实打实的肥水不流外人田。 通过股份占有树状图可以看到,股东分别是本山控股有限公司、赵本山及其妻子马立娟。 其中,本山控股有限公司占股60%、赵本山和马立娟分别占19.6%、20.4%,马丽娟是疑似实际控制人,但最终受益人仍是赵本山和马丽娟夫妻二人,没有第三者,可以说是实打实的“自家产业”了。 为何“去本山化” 赵本山之所以将公司改名,肯定不只是因为好听,还有更深的意义! 一方面是为了更进一步的“去本山化”。这几年本山传媒公司一直在努力的“去本山化”,为的当然就是摆脱对赵本山个人名望的依赖。 之前,杨树林等人在进行活动的时候,就介绍自己是辽宁民间艺术团,实质就已经在为人气和知名度做出了一定的铺垫,毕竟到了一定程度,公司也是需要转型的。 值得一提的是,其实本山传媒的前身是辽宁民间艺术团,但在赵本山事业鼎盛时期接受了他,并用自己的名字来命名,可以看出是为了打造一定的知名度。尽管现在培育出的人才众多,但是被大家熟知的却极少,因此“去本山化”可谓是迟早的事情。 随着本山传媒的更名,很多网友不禁感叹,这是一个时代的结束。 这几年本山传媒是在走下坡路。不但赵本山自己也不上春晚了,就连徒弟们也相继淡出大家的视野。以前上过春晚的丫蛋,小沈阳等,现在已经沦为十八线明星了。就连曾经和马云拍过小品的宋小宝近年来也消声灭迹了。 这次本山传媒更名,大众认为去本山化倾向明显,回望本山传媒早期,是依靠赵本山老师一个人的知名度去闯天地。但是,随着现代文化公司运营的逐渐正规化,越来越多的文化公司开始注重打造公司品牌而不再注重个人品牌效应,所以这一次公司的改名,是对现代文化公司商业运营的重大转变。 仓促中拟写此文,纪念本山传媒,纪念本山时代。'
ltp = LtpParser()
words, postags = ltp.parser_process(content_1) NER_1 = OrderedDict()
for index, tag in enumerate(postags):
if tag == 'ni' and len(words[index]) > 1: #组织名
NER_1.setdefault('ORG', set()).add(words[index])
elif tag == 'nh' and len(words[index]) > 1:#人名
NER_1.setdefault('PER', set()).add(words[index])
elif tag == 'ns' and len(words[index]) > 1:#地名
NER_1.setdefault('LOC', set()).add(words[index])
print(NER_1)
三.结果
OrderedDict([('LOC', {'赵本山', '辽宁省', '本山', '沈阳'}), ('PER', {'赵本山', '马丽娟', '本山', '马立娟', '杨树林', '刘老根', '宋小宝', '官宣'}), ('ORG', {'国家旅游局', '辽宁民间艺术团有限公司', '本山传媒有限公司', '辽宁民间艺术团', '文化部', '辽宁大学', '本山传媒公司', '中宣部'})])
结果中把''赵本山‘,’本山‘当作LOC了。这里可以引入外部词典解决。
利用pyltp进行实体识别的更多相关文章
- 命名实体识别,使用pyltp提取文本中的地址
首先安装pyltp pytlp项目首页 单例类(第一次调用时加载模型) class Singleton(object): def __new__(cls, *args, **kwargs): if n ...
- NLP(二十四)利用ALBERT实现命名实体识别
本文将会介绍如何利用ALBERT来实现命名实体识别.如果有对命名实体识别不清楚的读者,请参考笔者的文章NLP入门(四)命名实体识别(NER) . 本文的项目结构如下: 其中,albert_ ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
- 学习笔记CB007:分词、命名实体识别、词性标注、句法分析树
中文分词把文本切分成词语,还可以反过来,把该拼一起的词再拼到一起,找到命名实体. 概率图模型条件随机场适用观测值条件下决定随机变量有有限个取值情况.给定观察序列X,某个特定标记序列Y概率,指数函数 e ...
- NLP入门(五)用深度学习实现命名实体识别(NER)
前言 在文章:NLP入门(四)命名实体识别(NER)中,笔者介绍了两个实现命名实体识别的工具--NLTK和Stanford NLP.在本文中,我们将会学习到如何使用深度学习工具来自己一步步地实现N ...
- 【转】基于VSM的命名实体识别、歧义消解和指代消解
原文地址:http://blog.csdn.net/eastmount/article/details/48566671 版权声明:本文为博主原创文章,转载请注明CSDN博客源地址!共同学习,一起进步 ...
- HMM(隐马尔科夫模型)与分词、词性标注、命名实体识别
转载自 http://www.cnblogs.com/skyme/p/4651331.html HMM(隐马尔可夫模型)是用来描述隐含未知参数的统计模型,举一个经典的例子:一个东京的朋友每天根据天气{ ...
- HMM与分词、词性标注、命名实体识别
http://www.hankcs.com/nlp/hmm-and-segmentation-tagging-named-entity-recognition.html HMM(隐马尔可夫模型)是用来 ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
随机推荐
- k8s-secret用法
创建username和password文件: $ echo -n "admin" > ./username $ echo -n "1f2d1e2e67df" ...
- ajax 请求二进制流 图片
<html xmlns="http://www.w3.org/1999/xhtml"><head runat="server"> ...
- Linux I2C核心、总线和设备驱动
目录 更新记录 一.Linux I2C 体系结构 1.1 Linux I2C 体系结构的组成部分 1.2 内核源码文件 1.3 重要的数据结构 二.Linux I2C 核心 2.1 流程 2.2 主要 ...
- vue组件常用传值
一.使用Props传递数据 在父组件中使用儿子组件 <template> <div> 父组件:{{mny}} <Son1 :mny="mny"&g ...
- react route使用HashRouter和BrowserRouter的区别-Content Security Policy img-src 404(Not found)
踩坑经历 昨天看了篇关于react-route的文章,说BrowserRouter比HashRouter好一些,react也是推荐使用BrowserRouter,毕竟自己在前端方面来说,就是个小白,别 ...
- Android SQLiteDatabase的使用
package com.shawn.test; import android.content.ContentValues; import android.content.Context; import ...
- SpringCloud之Eureka注册中心原理及其搭建
一.Eureka简介 Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的.SpringCl ...
- 5.API详解
Dao 中需要通过 SqlSession 对象来操作 DB.而 SqlSession 对象的创建, 需要其工厂对象 SqlSessionFactory.SqlSessionFactory 对象, 需要 ...
- 11.SSH整合
由于自己学习的版本比较落后,这里就不总结了 在我这个版本整合的过程中的几点问题: 1.在web.xml的配置过程中: <!-- 如果使用的是load获取数据,在jsp页面申请取得数据时才真正的执 ...
- str 文本函数的调用
方法 说明 S.isdigit() 判断字符串中的字符是否全为数字 S.isalpha() 判断字符串是否全为英文字母 S.islower() 判断字符串所有字符是否全为小写英文字母 S.isuppe ...