大数据测试类型&大数据测试步骤
一、什么是大数据?
大数据是一个大的数据集合,通过传统的计算技术无法进行处理。这些数据集的测试需要使用各种工具、技术和框架进行处理。大数据涉及数据创建、存储、检索、分析,而且它在数量、多样性、速度方法都很出色。
二、大数据测试类型
测试大数据应用程序更多的是验证其数据处理,而不是测试软件产品的个别功能。当涉及到大数据测试时,性能和功能测试是关键。
在大数据测试中,QA工程师使用集群和其他组件来验证对TB级数据的成功处理。因为处理非常快,所以它需要高水平的测试技能。处理可以是三种类型:批量、实时、交互。
与此同时,数据质量也是大数据测试的一个重要因素。在测试应用程序之前,有必要检查数据的质量,并将其视为数据库测试的一部分。它涉及检查各种字段,如一致性,准确性,重复,一致性,有效性,数据完整性等。
三、大数据测试步骤
下图给出了测试大数据应用程序阶段的高级概述:
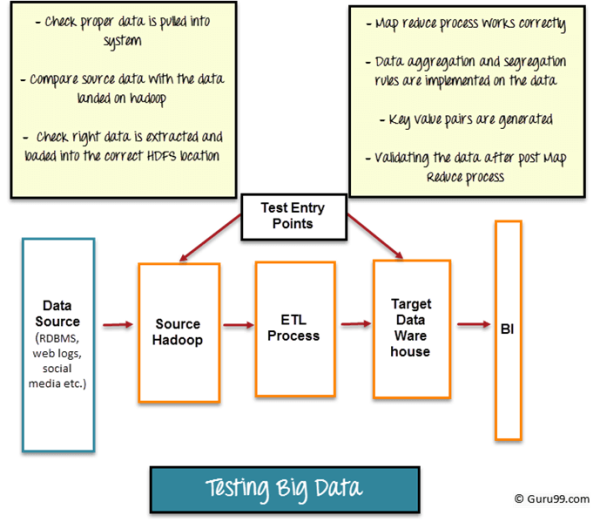
大数据测试实现被分成三个步。
Step 1:数据阶段验证
大数据测试的第一步,也称作pre-hadoop阶段该过程包括如下验证:
1、来自各方面的数据资源应该被验证,来确保正确的数据被加载进系统
2、将源数据与推送到Hadoop系统中的数据进行比较,以确保它们匹配
3、验证正确的数据被提取并被加载到HDFS正确的位置
该阶段可以使用工具Talend或Datameer,进行数据阶段验证。
Step 2:"MapReduce"验证
大数据测试的第二步是MapReduce的验证。在这个阶段,测试者在每个节点上进行业务逻辑验证,然后在运行多个节点后验证它们,确保如下操作的正确性:
1、Map与Reduce进程正常工作
2、在数据上实施数据聚合或隔离规则
3、生成键值对
4、在执行Map和Reduce进程后验证数据
Step 3:输出阶段验证
大数据测试的最后或第三阶段是输出验证过程。生成输出数据文件,同时把文件移到一个EDW(Enterprise Data Warehouse:企业数据仓库)中或着把文件移动到任何其他基于需求的系统中。在第三阶段的活动包括:
1、检查转换(Transformation)规则被正确应用
2、检查数据完整性和成功的数据加载到目标系统中
3、通过将目标数据与HDFS文件系统数据进行比较来检查没有数据损坏
四、架构测试
Hadoop处理大量的数据,并且是非常耗费资源的。因此,架构测试对于确保您的大数据项目的成功至关重要。系统设计不当或设计不当可能导致性能下降,系统不能满足要求。至少,性能和故障转移测试服务应该在Hadoop环境中完成。
性能测试包括测试作业完成时间,内存使用率,数据吞吐量和类似的系统指标。而故障转移测试服务的动机是为了验证在数据节点发生故障的情况下数据处理是否无缝地发生
五、性能测试
大数据性能测试包括两个主要的行动
数据采集和整个过程:在这个阶段,测试人员验证快速系统如何消耗来自各种数据源的数据。测试涉及识别队列在给定时间框架内可以处理的不同消息。它还包括如何快速将数据插入到底层数据存储中,例如插入到Mongo和Cassandra数据库中。
- 数据处理:它涉及验证执行查询或映射缩减作业的速度。它还包括在底层数据存储填充到数据集中时独立测试数据处理。例如,在底层HDFS上运行Map Reduce作业
- 子组件性能:这些系统由多个组件组成,而且必须单独测试每个组件。例如,消息的索引和消费速度有多快,mapreduce作业,查询性能,搜索等
六、性能测试方法
大数据应用性能测试涉及大量结构化和非结构化数据的测试,并且需要特定的测试方法来测试这些海量数据。
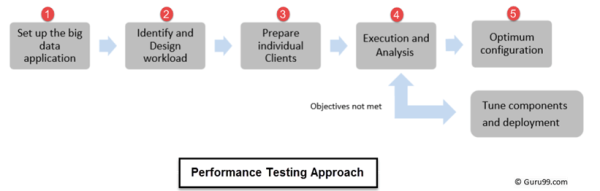
性能测试按此顺序执行
1、过程从设置要测试性能的大数据群集开始
2、确定和设计相应的工作量
3、准备个人客户(自定义脚本创建)
4、执行测试并分析结果(如果不满足目标,则调整组件并重新执行)
5、最佳配置
- 性能测试的参数
性能测试需要验证的各种参数
1、数据存储:数据如何存储在不同的节点中
2、提交日志:允许增长的提交日志有多大
3、并发性:有多少个线程可以执行写入和读取操作
4、缓存:调整缓存设置“行缓存”和“键缓存”。
5、超时:连接超时值,查询超时值等
6、JVM参数:堆大小,GC收集算法等
7、地图降低性能:排序,合并等
8、消息队列:消息速率,大小等
测试环境需求
测试环境需求取决于您正在测试的应用程序的类型。对于大数据测试,测试环境应该包含
1、它应该有足够的空间来存储和处理大量的数据
2、它应该有分布式节点和数据的集群
3、它应该有最低的CPU和内存利用率,以保持高性能

七、大数据测试面临的挑战
自动化
大数据的自动化测试需要具有技术专长的人员。另外,自动化工具不具备处理测试过程中出现的意外问题的能力
虚拟化
这是测试的一个不可缺少的阶段。虚拟机延迟会在实时大数据测试中造成计时问题。在大数据中管理图像也是一件麻烦事。
大数据集
1、需要验证更多的数据,并需要更快地完成
2、需要自动化测试工作
3、需要能够跨不同的平台进行测试
八、性能测试挑战
1、多种技术组合:每个子组件属于不同的技术,需要单独测试
2、不可用的特定工具:没有一个工具可以执行端到端的测试。例如,NoSQL可能不适合消息队列
3、测试脚本:需要高度的脚本来设计测试场景和测试用例
4、测试环境:数据量大,需要特殊的测试环境
5、监控解决方案:存在有限的解决方案,可以监控整个环境
6、诊断解决方案:需要定制解决方案来深入了解性能瓶颈区域
概要
1、随着数据工程和数据分析技术的不断进步,大数据测试是不可避免的。
2、大数据处理可以是批处理,实时或交互式处理
3、测试大数据应用程序的3个阶段是
- 数据分级验证
- “MapReduce”验证
- 输出验证阶段
4、架构测试是大数据测试的重要阶段,因为设计不佳的系统可能会导致前所未有的错误和性能下降
5、大数据的性能测试包括验证
- 数据吞吐量
- 数据处理
- 子组件性能
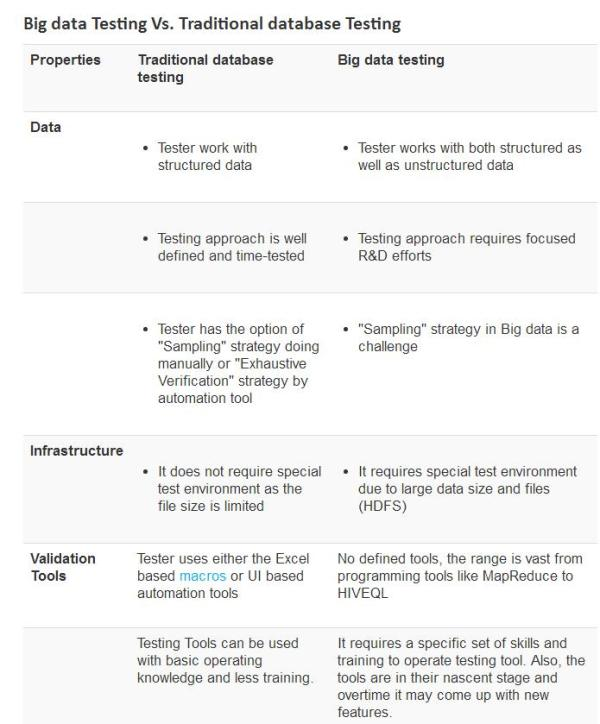
6、大数据测试与传统数据测试在数据,基础架构和验证工具方面有很大的不同
7、大数据测试挑战包括虚拟化,测试自动化和处理大型数据集。大数据应用程序的性能测试也是一个问题。
大数据测试类型&大数据测试步骤的更多相关文章
- 存储过程 分页【NOT IN】和【>】效率大PK 千万级别数据测试结果
use TTgoif exists (select * from sysobjects where name='Tonge')drop table Tongecreate table Tonge( I ...
- 普通方式 分页【NOT IN】和【>】效率大PK 千万级别数据测试结果
首现创建一张表,然后插入1000+万条数据,接下来进行测试. use TTgoif exists (select * from sysobjects where name='Tonge')drop t ...
- long l=88;这个表达式是正确的,因为long比int类型大,会发生自动转换
long l=88;这个表达式是正确的,因为long比int类型大,会发生自动转换
- [原创]java WEB学习笔记81:Hibernate学习之路--- 对象关系映射文件(.hbm.xml):hibernate-mapping 节点,class节点,id节点(主键生成策略),property节点,在hibernate 中 java类型 与sql类型之间的对应关系,Java 时间和日期类型的映射,Java 大对象类型 的 映射 (了解),映射组成关系
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Atitit 提升开发进度大方法--高频功能与步骤的优化 类似性能优化
Atitit 提升开发进度大方法--高频功能与步骤的优化 类似性能优化 1. 通用功能又可以组合成crud模块1 1.1. 查询(包括步骤,发送查询dsl,通讯返回结果,绑定到表格控件)2 1.2. ...
- 【详细解析】MySQL索引详解( 索引概念、6大索引类型、key 和 index 的区别、其他索引方式)
[详细解析]MySQL索引详解( 索引概念.6大索引类型.key 和 index 的区别.其他索引方式) MySQL索引的概念: 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分 ...
- Atitit图像识别的常用特征大总结attilax大总结
Atitit图像识别的常用特征大总结attilax大总结 1.1. 常用的图像特征有颜色特征.纹理特征.形状特征.空间关系特征. 1 1.2. HOG特征:方向梯度直方图(Histogram of O ...
- BLOB:大数据,大对象,在数据库中用来存储超长文本的数据,例如图片等
将一张图片存储在mysql中,并读取出来(BLOB数据:插入BLOB类型的数据必须使用PreparedStatement,因为插入BLOB类型的数据无法使用字符串拼写): -------------- ...
- .git文件过大!删除大文件
在我们日常使用Git的时候,一般比较小的项目,我们可能不会注意到.git 这个文件. 其实, .git文件主要用来记录每次提交的变动,当我们的项目越来越大的时候,我们发现 .git文件越来越大. 很大 ...
随机推荐
- 火车购票问题(16年ccf)
火车购票问题(16年ccf) 问题描述 请实现一个铁路购票系统的简单座位分配算法,来处理一节车厢的座位分配. 假设一节车厢有20排.每一排5个座位.为方便起见,我们用1到100来给所有的座位编号,第一 ...
- Elasticsearch的安装入门
大纲: 一.简介 二.Logstash 三.Redis 四.Elasticsearch 五.Kinaba 一.简介 1.核心组成 ELK由Elasticsearch.Logstash和Kibana三部 ...
- 部署Hadoop-3.0-高性能集群
一.Hadoop概述: Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储.Hadoop的框 ...
- Python实现的计算马氏距离算法示例
Python实现的计算马氏距离算法示例 本文实例讲述了Python实现的计算马氏距离算法.分享给大家供大家参考,具体如下: 我给写成函数调用了 python实现马氏距离源代码: # encod ...
- java数据机构之自定义栈
一.栈的特点 1.线性数据结构 2.后进先出 二.使用数组来实现栈 //使用数组来实现栈 public class MyArrayStack<E> { //保存数据 private Obj ...
- 【HANA系列】SAP HANA SQL IFNULL和NULLIF用法与区别
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA SQL IFN ...
- 架构模式: API网关
模式: API网关 上下文 让我们假设您正在构建一个使用Microservice体系结构模式的在线商店,并且您正在实现产品详细信息页面.您需要开发产品详细信息用户界面的多个版本: 用于桌面和移动浏览器 ...
- matlab之编写函数m文件计算排列组合Cnm
function y=myfun(n) y=1; for i in 1:n; y=y*(m-i+1)/i; end 给y赋初值 给i遍历 计算每一项的乘积之和 注意:要保存函数的名字为myfun,因为 ...
- GitHub项目精选(持续更新)
![在这里插入图片描述](https://img-blog.csdnimg.cn/20190815110442972.jpg?x-oss-process=image/watermark,type_Zm ...
- 【并行计算-CUDA开发】浅谈GPU并行计算新趋势
随着GPU的可编程性不断增强,GPU的应用能力已经远远超出了图形渲染任务,利用GPU完成通用计算的研究逐渐活跃起来,将GPU用于图形渲染以外领域的计算成为GPGPU(General Purpose c ...