11.Java SDK源码分析系列笔记-Hashtable
1. 是什么
线程安全的hashmap
2. 如何使用
public class HashtableTest
{
public static void main(String[] args) throws InterruptedException
{
Hashtable<Integer, Integer> map = new Hashtable<>();
Thread thread1 = new Thread(()->{
for (int i = 0; i < 100000; i++)
{
map.put(i, i);
}
});
Thread thread2 = new Thread(()->{
for (int i = 100000; i < 200000; i++)
{
map.put(i, i);
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(map);
System.out.println(map.size());
for (int i = 0; i < 200000; i++)
{
if (!map.contains(i))
{
throw new RuntimeException("并发put有问题");//不会抛出异常说明并发put没问题
}
System.out.println(map.remove(i));
}
}
}
3. 原理分析
3.1. uml
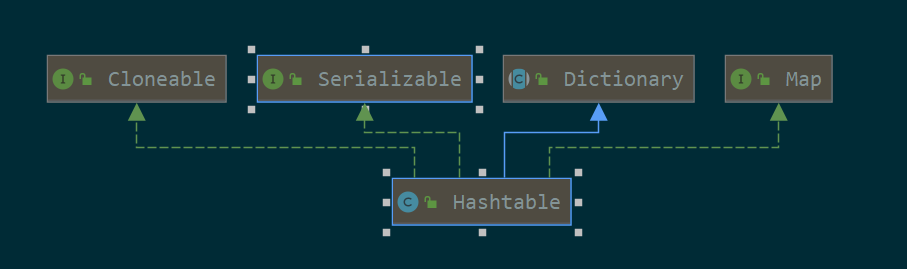
可克隆,可序列化,实现了Map接口
3.2. 构造方法
使用链地址法(单链表)解决Hash冲突
初始化容量为11,默认的加载因子为0.75
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
//使用Entry数组实现
private transient Entry<?,?>[] table;
//map中实际元素的个数
private transient int count;
//以下两个决定了什么时候扩容
private int threshold;
private float loadFactor;
private transient int modCount = 0;
public Hashtable() {
//初始化容量为11,加载因子为0.75
this(11, 0.75f);
}
public Hashtable(int initialCapacity, float loadFactor) {
//检查参数合法
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
//创建table数组
table = new Entry<?,?>[initialCapacity];
//threshold取int MAX_ARRAY_SIZE = Integer.MAX_VALUE 8和initialCapacity * loadFactor中的小者
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
}
3.3. put方法
//加了synchronized
public synchronized V put(K key, V value) {
// Make sure the value is not null
//与HashMap不同,这里value不能为null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//计算下标
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
//遍历链表直到找到相等的节点或者到末尾
for(; entry != null ; entry = entry.next) {
//找到了,替换value
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//没有找到,新建节点加入链表
addEntry(hash, key, value, index);
return null;
}
3.3.1. 使用synchronized加锁
public synchronized V put(K key, V value) {
//...
}
3.3.2. 计算key落在entry数组中的哪个位置【或者说哪个链表】
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//计算下标
//计算index是通过对数组长度取模而不是使用与操作
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
3.3.3. 遍历链表直到找到相等的节点或者到末尾
//遍历链表直到找到相等的节点或者到末尾
for(; entry != null ; entry = entry.next) {
//找到了,替换value
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
3.3.4. 没有找到,新建节点加入链表头部
- addEntry方法
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
//判断是否需要扩容
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
//新建节点并且直接放入数组相应位置
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
3.3.4.1. 扩容
- rehash方法
@SuppressWarnings("unchecked")
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflowconscious code
//新capacity=旧capacity*2+1
int newCapacity = (oldCapacity << 1) + 1;
//如果容量超过了MAX_ARRAY_SIZE(int MAX_ARRAY_SIZE = Integer.MAX_VALUE 8),那么以MAX_ARRAY_SIZE为准
if (newCapacity MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
//以新capacity创建新数组
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
//由后往前遍历entry数组
for (int i = oldCapacity ; i > 0 ;) {
//从头到尾遍历链表
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
//e表示此次要迁移的节点,old表示下一个要迁移的节点
Entry<K,V> e = old;
old = old.next;
//计算e在新entry数组中的位置
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
//把e的next指向新entry数组中的位置(链表的头节点)
e.next = (Entry<K,V>)newMap[index];
//再把新entry数组中的位置赋值为e
//等于就是头插法
newMap[index] = e;
}
}
}
3.4. get方法
//加了synchronized
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//计算在那个链表中
int index = (hash & 0x7FFFFFFF) % tab.length;
//遍历链表找到相等的节点
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
3.4.1. 使用synchronized加锁
public synchronized V get(Object key) {
}
3.4.2. 计算key落在entry数组中的哪个位置【或者说哪个链表】
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//计算在那个链表中
int index = (hash & 0x7FFFFFFF) % tab.length;
3.4.3. 遍历链表直到找到相等的节点或者到末尾
//遍历链表找到相等的节点
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
3.5. remove方法
使用synchronized修饰
同get方法找到节点,删除的操作就是链表节点的删除操作
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
//不是头节点
prev.next = e.next;
} else {
//头节点
tab[index] = e.next;
}
count;
//help GC
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
3.5.1. 使用synchronized加锁
public synchronized V remove(Object key) {
}
3.5.2. 计算key落在entry数组中的哪个位置【或者说哪个链表】
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
3.5.3. 遍历链表直到找到相等的节点或者到末尾,把value置为null
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
//不是头节点
prev.next = e.next;
} else {
//头节点
tab[index] = e.next;
}
count;
//help GC
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
3.6. containsKey方法
//加了synchronized
public synchronized boolean containsKey(Object key) {
//以下逻辑同get方法
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
3.6.1. 使用synchronized加锁
public synchronized boolean containsKey(Object key) {
}
3.6.2. 计算key落在entry数组中的哪个位置【或者说哪个链表】
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
3.6.3. 遍历链表直到找到相等的节点或者到末尾
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
11.Java SDK源码分析系列笔记-Hashtable的更多相关文章
- spring源码分析系列 (8) FactoryBean工厂类机制
更多文章点击--spring源码分析系列 1.FactoryBean设计目的以及使用 2.FactoryBean工厂类机制运行机制分析 1.FactoryBean设计目的以及使用 FactoryBea ...
- Spring mvc源码分析系列--Servlet的前世今生
Spring mvc源码分析系列--Servlet的前世今生 概述 上一篇文章Spring mvc源码分析系列--前言挖了坑,但是由于最近需求繁忙,一直没有时间填坑.今天暂且来填一个小坑,这篇文章我们 ...
- jQuery源码分析系列
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 版本截止到2013.8.24 jQuery官方发布最新的的2.0.3为准 附上每一章的源码注释分析 :https://git ...
- MyCat源码分析系列之——结果合并
更多MyCat源码分析,请戳MyCat源码分析系列 结果合并 在SQL下发流程和前后端验证流程中介绍过,通过用户验证的后端连接绑定的NIOHandler是MySQLConnectionHandler实 ...
- MyCat源码分析系列之——BufferPool与缓存机制
更多MyCat源码分析,请戳MyCat源码分析系列 BufferPool MyCat的缓冲区采用的是java.nio.ByteBuffer,由BufferPool类统一管理,相关的设置在SystemC ...
- jquery2源码分析系列
学习jquery的源码对于提高前端的能力很有帮助,下面的系列是我在网上看到的对jquery2的源码的分析.等有时间了好好研究下.我们知道jquery2开始就不支持IE6-8了,从jquery2的源码中 ...
- [Tomcat 源码分析系列] (二) : Tomcat 启动脚本-catalina.bat
概述 Tomcat 的三个最重要的启动脚本: startup.bat catalina.bat setclasspath.bat 上一篇咱们分析了 startup.bat 脚本 这一篇咱们来分析 ca ...
- [转]jQuery源码分析系列
文章转自:jQuery源码分析系列-Aaron 版本截止到2013.8.24 jQuery官方发布最新的的2.0.3为准 附上每一章的源码注释分析 :https://github.com/JsAaro ...
- MyBatis 源码分析系列文章导读
1.本文速览 本篇文章是我为接下来的 MyBatis 源码分析系列文章写的一个导读文章.本篇文章从 MyBatis 是什么(what),为什么要使用(why),以及如何使用(how)等三个角度进行了说 ...
- spring源码分析系列
spring源码分析系列 (1) spring拓展接口BeanFactoryPostProcessor.BeanDefinitionRegistryPostProcessor spring源码分析系列 ...
随机推荐
- CompletableFuture原理及应用场景详解
1.应用场景 现在我们打开各个APP上的一个页面,可能就需要涉及后端几十个服务的API调用,比如某宝.某个外卖APP上,下面是某个外卖APP的首页.首页上的页面展示会关联很多服务的API调用,如果使用 ...
- ORA-28001:口令已经失效
Oracle用户口令默认的有效期导致的一个异常,留爪. Oralce11G下,创建的用户及口令,也就是用户密码默认会有个180天的过期时间, 如果超过180天用户口令未做修改,则该用户口令失效,也就是 ...
- datasnap的监督功能【2】-管理Session
1.服务端的Session是有TDSSession定义的.TDSSession提供了许多有用的方法和特性,再开发室取得服务or重要信息. 如Session状态.安排Session独享定时or自动执行工 ...
- Eclipse 配置maven默认源及本地仓库
1.window->Preferences 2.Maven-> User Setting 3.全局配置Global Settings/用户配置 User Settings 修改为自己的配 ...
- vue3在构建时,使用魔法糖语法时defineProps和defineEmits的注意事项
在 Vue 3.2+ 版本中,可以使用 <script setup> 替代传统的 script标签来编写组件,它提供了更简洁的语法来编写 Composition API 代码. 在 < ...
- Asp.net core 少走弯路系列教程(七)WebApi 学习
前言 新人学习成本很高,网络上太多的名词和框架,全部学习会浪费大量的时间和精力. 新手缺乏学习内容的辨别能力,本系列文章为新手过滤掉不适合的学习内容(比如多线程等等),让新手少走弯路直通罗马. 作者认 ...
- PLSQL中&符号处理
在SQL语句中的字符串中出现了&符号,当执行的时候会被认为是参数需要传递,如update product set brand = 'D&G'; 解决办法是把语句改为:update pr ...
- .net core workflow流程定义
.net core workflow流程定义 WikeFlow官网:http://www.wikesoft.com WikeFlow学习版演示地址:http://workflow.wikesoft.c ...
- codeup之查找
Description 输入数组长度 n 输入数组 a[1-n] 输入查找个数m 输入查找数字b[1-m] 输出 YES or NO 查找有则YES 否则NO . Input 输入有多组数据. 每组输 ...
- Third Maximum Number——LeetCode⑬
//原题链接https://leetcode.com/problems/third-maximum-number/ 题目描述 Given a non-empty array of integers, ...