干货大分享!带你了解数栈批流统一的高效数据同步插件—FlinkX
一、什么是FlinkX
FlinkX是一款基于Flink的分布式离线/实时数据同步插件,可实现多种异构数据源高效的数据同步,其由袋鼠云于2016年初步研发完成,目前有稳定的研发团队持续维护,已在Github上开源(开源地址详见文章末尾),并维护该开源社区。目前已完成批流统一,离线计算与流计算的数据同步任务都可基于FlinkX实现。
FlinkX将不同的数据源库抽象成不同的Reader插件,目标库抽象成不同的Writer插件,具有以下特点:
- 基于Flink开发,支持分布式运行;
- 双向读写,某数据库既可以作为源库,也可以作为目标库;
- 支持多种异构数据源,可实现MySQL、Oracle、SQLServer、Hive、Hbase等20多种数据源的双向采集。
- 高扩展性,强灵活性,新扩展的数据源可与现有数据源可即时互通。
二、FlinkX应用场景
FlinkX数据同步插件主要应用于大数据开发平台的数据同步/数据集成模块,通常采用将底层高效的同步插件和界面化的配置方式相结合的方式,使大数据开发人员可简洁、快速的完成数据同步任务开发,实现将业务数据库的数据同步至大数据存储平台,从而进行数据建模开发,以及数据开发完成后,将大数据处理好的结果数据同步至业务的应用数据库,供企业数据业务使用。
三、FlinkX工作原理详解
linkX基于Flink实现,其选型及优势详见
https://mp.weixin.qq.com/s/uQbGLY3_cj0h2H_PZZFRGw。FlinkX数据同步任务的本质是一个Flink程序,读出写入的数据同步任务会被翻译成StreamGraph在Flink执行,FlinkX开发者只需要关注InputFormat和OutputFormat接口实现即可。工作原理如下:
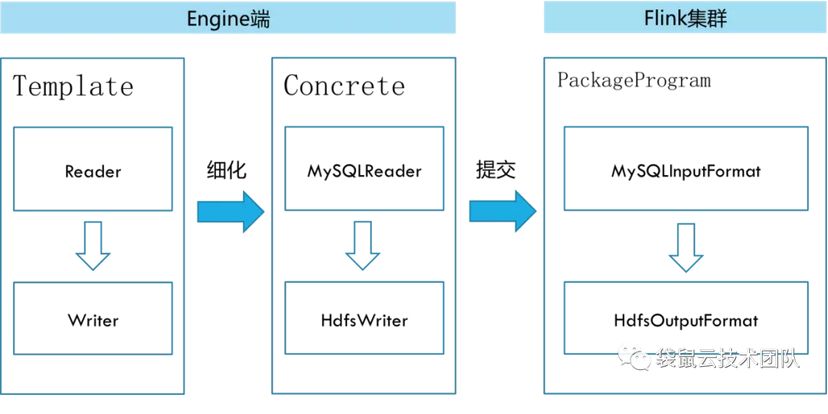
Engine是袋鼠云封装的任务调度引擎,WEB端配置好的数据同步任务首先会提交至任务调度引擎,Template模块根据同步任务的配置信息加载源数据库和目标数据库对应的Reader和Writer插件,Reader插件实现InputFormat接口,从数据库获取DataStream对象,Writer插件实现OutFormat接口,将目标数据库与DataStream对象相关联,从而通过DataStream对象将读出写入串接在一起,组装成一个Flink任务提交至Flink集群上进行运行。
之前基于Flink的分片、累加器特性,解决了数据同步过程中的增量同步、多通道控制、脏数据管理与错误管理等场景。19年基于Flink的checkpoint机制,实现了断点续传、流数据续跑等功能,来了解一下它的新特性吧。
(1)断点续传
数据同步过程中,假如一个任务要同步500G的数据到目标库,已经跑了15min,但到400G的时候由于集群资源不够、网络等因素数据同步失败了,若需要重头跑此任务,想必该同学要抓狂了。FlinkX基于checkpoin机制可支持断点续传,当同步任务由于上述原因失败时,不需要重跑任务,只需从断点继续同步,节省重跑时间和集群资源。
Flink的Checkpoint功能是其实现容错的核心功能,它能够根据配置周期性地对任务中的Operator/task的状态生成快照,将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
并且断点续传可和任务失败重试机制配合,即当任务执行失败,系统会自动进行重试,若重试成功则系统会接着断点位置继续同步,从而减少人为运维。
(2)实时采集与续跑
19年6月份,袋鼠云数栈研发团队基于FlinkX实现批流数据采集统一,可对MySQL Binlog、Filebeats、Kafka等数据源进行实时采集,并可写入Kafka、Hive、HDFS、Greenplum等数据源,采集任务也支持作业并发数与作业速率的限制,以及脏数据管理。并基于checkpoint机制,可实现实时采集任务的续跑。当产生业务数据或Flink程序引起的采集进程中断时,可基于Flink定期存储的快照,对流数据的读取节点进行保存,从而在进行故障修复时,可选择历史保存的数据断点进行续跑操作,保证数据的完整性。此功能在袋鼠云的StreamWorks产品中实现,欢迎大家了解。
(3)流数据的脏数据管理
之前在BatchWorks离线计算产品中,已实现离线数据同步的脏数据管理,并基于Flink的累加器实现脏数据的错误管理,当错误量达到配置时,置任务失败。目前流数据实时采集也支持了此功能,即在将源库数据写入目标库的过程中,将错误记录进行存储,以便后续分析数据同步过程中的脏数据,并进行处理。但由于是流数据采集,任务具有不间断性,没有进行错误数记录达到阈值的触发任务停止操作,待后续用户自行对脏数据分析,进行处理。
(4)数据写入至Greenplum、OceanBase数据源
Greenplum是基于PostgreSQL的MPP数据库,支持海量数据的存储与管理,目前在市场上也被很多企业采用。于最近,数栈基于FlinkX实现多类型数据源写入Greenplum,除全量同步外,也支持部分数据库增量同步写入。OceanBase是阿里研发的一款可扩展的金融领域关系型数据库,其用法与MySQL基本一致,实现OceanBase的数据读入写出也是基于jdbc的连接方式,进行数据表与字段的同步与写入,也支持对OceanBase进行增量写入,以及作业同步通道、并发的控制。
写入Greenplum等关系数据库时,默认是不使用事务的,因为数据量特别大的情况下,一旦任务失败,就会对业务数据库产生巨大的影响。但是在开启断点续传的时候必须开启事务,如果数据库不支持事务,则无法实现断点续传的功能。开启断点续传时,会在Flink生成快照的时候提交事务,把当前的数据写入数据库,如果两次快照期间任务失败了,则这次事务里的数据不会写入数据库,任务恢复时从上一次快照记录的位置继续同步数据,这样就可以做到任务多次失败续跑的情况下准确的同步数据。
四、写在后面
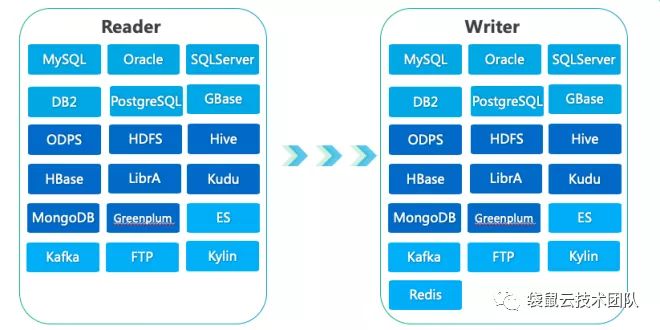
FlinkX经过袋鼠云内部使用以及在大量的数据中台项目中实践,支持以下数据源。且在FlinkX的高扩展特性下,将持续支撑更多的数据源。
本文首发于:数栈研习社
数栈是云原生—站式数据中台PaaS,我们在github上有一个有趣的开源项目:FlinkX。FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,比如MySQL,HDFS等,也可以采集实时变化的数据,比如MySQL binlog,Kafka等,是全域、异构、批流一体的数据同步引擎,大家如果有兴趣,欢迎来github社区找我们玩~
干货大分享!带你了解数栈批流统一的高效数据同步插件—FlinkX的更多相关文章
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 增量数据同步中间件DataLink分享(已开源)
项目介绍 名称: DataLink['deitə liŋk]译意: 数据链路,数据(自动)传输器语言: 纯java开发(JDK1.8+)定位: 满足各种异构数据源之间的实时增量同步,一个分布式.可扩展 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 【转】JS大总结(带实例)
JS大总结(带实例) JavaScript事务查询综合click() 对象.click() 使对象被点击.closed 对象.closed 对象窗口是否已封闭true/falseclearTimeou ...
- 【干货】分享总结:MySQL数据一致性 罗小波 星辉天拓
[干货]分享总结:MySQL数据一致性 罗小波 星辉天拓 http://mp.weixin.qq.com/s?__biz=MjM5NzAzMTY4NQ==&mid=2653928966&a ...
- Asp.Net上传大文件带进度条swfupload
Asp.Net基于swfupload上传大文件带进度条百分比显示,漂亮大气上档次,大文件无压力,先看效果 一.上传效果图 1.上传前界面:图片不喜欢可以自己换 2.上传中界面:百分比显示 3.上传后返 ...
- lintcode12 带最小值操作的栈
实现一个带有取最小值min方法的栈,min方法将返回当前栈中的最小值. 你实现的栈将支持push,pop 和 min 操作,所有操作要求都在O(1)时间内完成. 建一个栈helpStack,用来存放从 ...
- LintCode-12.带最小值操作的栈
带最小值操作的栈 实现一个带有取最小值min方法的栈,min方法将返回当前栈中的最小值. 你实现的栈将支持push,pop 和 min 操作,所有操作要求都在O(1)时间内完成. 注意事项 如果堆栈中 ...
- 全栈开发必备的10款 Sublime Text 插件
Sublime Text 具有漂亮的用户界面和强大的功能,例如代码缩略图,多重选择,快捷命令等.Sublime Text 更妙的是它的可扩展性.所以,这里挑选了全栈开发必备的10款 Sublime T ...
- 《浏览器工作原理与实践》 <12>栈空间和堆空间:数据是如何存储的?
对于前端开发者来说,JavaScript 的内存机制是一个不被经常提及的概念 ,因此很容易被忽视.特别是一些非计算机专业的同学,对内存机制可能没有非常清晰的认识,甚至有些同学根本就不知道 JavaSc ...
随机推荐
- SpringBoot+Thymeleaf渲染下拉框异常解决
常规方式 <select class="form-control" name="operationType" th:field="${itemT ...
- ingress配置https报错certificate.lua:259: call(): failed to set DER private key: d2i_PrivateKey_bio() failed, context: ssl_certificate_by_lua*
困扰我2天的报错问题:certificate.lua:259: call(): failed to set DER private key: d2i_PrivateKey_bio() failed, ...
- 【Linux】5.8 Shell流程控制
Shell 流程控制 1. 判断语句 1.1 if判断 if else-if else 语法格式: if condition1 then command1 elif condition2 then c ...
- [SDR] 蓝牙专项教程 —— 从 0 到 1 教小白基于 SDR 编写蓝牙协议栈
目录 前言 一.开题之作 二.动态发送 BLE 广播包 三.基于 PlutoSDR 实现 BLE 广播包的收发一体能力 四.基于 PlutoSDR 的 BLE 广播包的收发实现接入涂鸦智能 APP 教 ...
- Redis的淘汰机制
第一种情况:设置了过期时间的数据 a:挑选使用最少的数据淘汰 b:随机淘汰 c:选择时间快过期数据淘汰 第二种:没有设置过期时间的数据 a:挑选使用最少的数据淘汰 b:随机淘汰 第三种: a:禁止驱逐 ...
- Asp.net mvc基础(十五)EF原理及SQL监控
EF会自动把Where().OrderBy().Select()等这些编译成"表达式树",然后回把表达式树翻译成SQL语句,因此不是"把数据都取到内存中,然后使用集合的方 ...
- 2025dsfz集训Day8:线段树
Day8:线段树 前言:线段树听起来很高大尚,就是儿子节点表示法的树.几乎一样. \[Designed\ By\ FrankWkd\ -\ Luogu@Lwj54joy,uid=845400 \] 特 ...
- liunx git 免密码登录
vscode远程git或在linux环境使用git时,每次clone都要输入帐号密码,很不方便,可以使用下面一行命令,系统会记录你输入的下一次帐号密码.(明文记录,注意规避风险) # 执行 g ...
- ArcGIS Desktop 10.7 完美汉化安装教程
1,下载文件并解压缩,双击[Esri ArcGIS Desktop v10.7.0.exe] 2.在安装向导中选择[Next] 3.选中[I accept the master agreement]我 ...
- SQL Server 2025 中的改进
SQL Server 2025 中的改进 当我们接近 SQL Server 2025 的首次公开版本时,开始深入探究 Azure SQL DB 如今(已公布和未公布)但在 SQL Server 盒装产 ...