如何利用1%的数据优化特定领域LLM预训练? | EMNLP'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Target-Aware Language Modeling via Granular Data Sampling

创新点
- 提出了一种将预先训练好的标记符与多粒度标记符合并的算法,生成高效的
n-gram特征,而且与下游任务的性能有很高的相关性。 - 利用上述研究成果,改进了基于重要性的数据采样技术,将通用词汇集调整为目标词汇集。这样就能更好地代表数据,提高模型在目标任务中的性能,同时在非目标任务中保持良好的性能。
内容概述
语言模型的预训练通常针对广泛的使用场景,并结合来自多种来源的数据。然而,有时模型需要在特定领域中表现良好,同时又不影响其他领域的性能。这就需要使用数据选择方法来确定潜在核心数据,以及如何有效地对这些选定数据进行抽样训练。
论文使用由多粒度标记组成的n-gram特征进行重要性抽样,这在句子压缩和表征能力之间取得了良好的平衡。抽样得到的数据与目标下游任务性能之间有很高的相关性,同时保留了其在其他任务上的有效性,使得语言模型可以在选定文档上更高效地进行预训练。
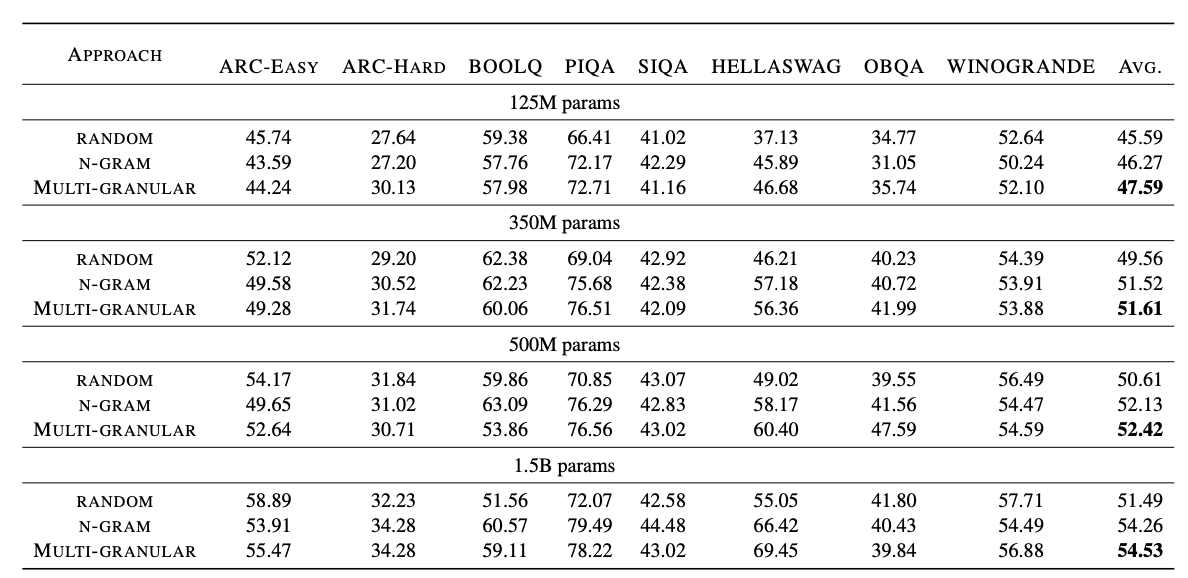
在八个基准测试中,在使用约1%的数据时,预训练模型的表现与完整的RefinedWeb数据相当,并且在模型规模范围为125M到1.5B时,超越了随机选择的样本。
方法
从大规模数据集(如RefinedWeb)中选择样本是缓慢且昂贵的,一个可行的解决方案是使用容易计算的n-gram特征将每个文档编码为向量。
假设从目标分布 \(p\) 中获取了一小部分目标文本示例 \(D_{task}\) ,以及从分布 \(q\) 中获取的大量原始数据集 \(D_{raw}\) ,其中包含 \(N\) 个示例,目标是从原始数据集中选择 \(k\) 个示例( \(k \ll N\) ),这些示例与目标相似。
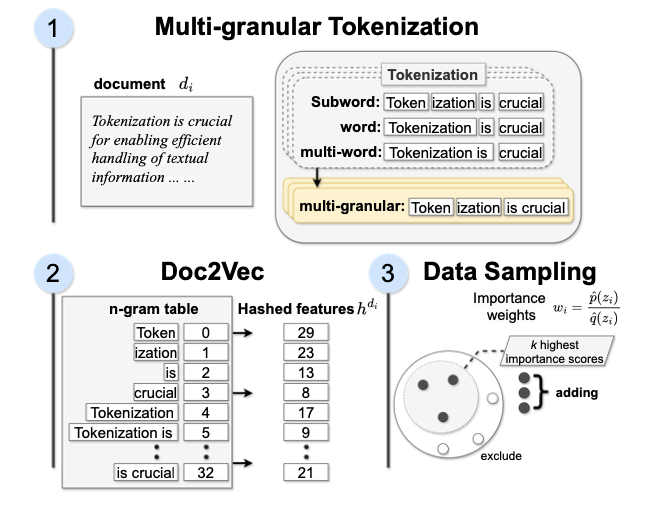
重要性采样
重要性采样技术选择与目标分布对齐的示例,为每个文本提供可处理的重要性估计,并在提供必要结构的特征空间 \({\mathbb{Z}}\) 上应用重要性采样。
特征提取器 \(h: {\mathbb{X}} \rightarrow {\mathbb{Z}}\) 用于转换输入为特征,得到的原始特征分布 \(q_{\text{feat}}\) 和目标特征分布 \(p_{\text{feat}}\) ,目标是选择特征与目标特征分布 \(p_{\text{feat}}\) 对齐的数据。
为了提取特征 \(q_{\text{feat}}\) 和 \(p_{\text{feat}}\),从每个分词文档中提取n-grams。每个n-gram被映射到哈希表中的一个键,每个键映射到n-gram计数。将从 \(N\) 个原始示例中获得的每个特征 \(z_i = h(x_i)\) 计算重要性权重,权重为 \(w_i = \frac{\hat{p}_{\text{feat}}(z_i)}{\hat{q}_{\text{feat}}(z_i)}\) 。
最后进行采样,从一个分布中选择 \(k\) 个示例,且不进行替换,其概率由 \(\frac{w_i}{\sum_{i=1}^N w_i}\) 给出。
分词器适配
为了推导目标词汇 \(V(t)\) ,使用Llama-3分词器的词汇 \(V_{start}\) 作为起点,并将 \(V_{start}\) 与从任务数据 \(D_{task}\) 中学习到的 \(V_{task}\) 合并。在构建 \(V_{task}\) 时,确保包含多粒度的标记(即单词和多词组合),然后将 \(V_{task}\) 与 \(V_{start}\) 合并形成 \(v(t - 1)\) 。
接下来,逐步从 \(v(t - 1)\) 中移除标记,以获得 \(v(t)\) ,在此过程中,最小化与原始词汇集的距离,以便提取更少偏倚的文档特征作为n-gram向量。
首先定义一个度量来衡量语料库中词汇集的质量,然后通过最大化词汇效用度量 ( \(\mathcal{H}_{v}\) ) 来学习最佳词汇,该度量的计算公式为:
\mathcal{H}_{v} = - \frac{1}{l_{v}}\sum_{j \in v } P(j)\log P(j),
\end{equation}
\]
其中, \(P(j)\) 是来自目标数据的标记 \(j\) 的相对频率,而 \(l_{v}\) 是词汇 \(v\) 中标记的平均长度。对于任何词汇,其熵得分 \(\mathcal{H}_{v}\) 基于其前一步的词汇进行计算,优化问题可以表述为:
\text{arg\ min}_{v(t-1), v(t)} \big [ \mathcal{H}{v(t)} - \mathcal{H}{v(t-1)} \big ]
\end{equation}
\]
其中, \(v(t)\) 和 \(v(t - 1)\) 是包含所有词汇的两个集合,大小的上限分别为 \(|v(t)|\) 和 \(|v(t - 1)|\) 。设置 \(|v(t)| = 10k\) ,其中 \(t=10\) ,而 \(|v(0)|\) 是默认的Llama-3 tokenizer的词汇大小。
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

如何利用1%的数据优化特定领域LLM预训练? | EMNLP'24的更多相关文章
- [2017-08-25]100行CSharp代码利用dynamic写个DSL(特定领域语言)
最近看<CLR via C#(第4版)> 读到第五章末尾dynamic基元类型时,看了下作者的一个利用dynamic动态调用string类型的Contains方法(静态方法)的实现,突然发 ...
- oracle12c中新能优化新特性之热度图和自动数据优化
1. Oracle12c热度图和自动数据优化 信息生命周期管理(ILM)是指在数据生命周期内管理它们的策略.依赖于数据的年龄和对应用的业务相关性,数据能被压缩,能被归档或移到低成本的存储上.简言之,I ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
- 基于特定领域国土GIS应用框架设计及应用
基于特定领域国土GIS应用框架 设计及应用 何仕国 2012年8月16日 摘要: 本文首先讲述了什么是框架和特定领域框架,以及与国土GIS 这个特定领 ...
- 【机器学习实战】第14章 利用SVD简化数据
第14章 利用SVD简化数据 SVD 概述 奇异值分解(SVD, Singular Value Decomposition): 提取信息的一种方法,可以把 SVD 看成是从噪声数据中抽取相关特征.从生 ...
- mysql查询优化之四:优化特定类型的查询
本文将介绍如何优化特定类型的查询. 1.优化count()查询count()聚合函数,以及如何优化使用了该函数的查询,很可能是mysql中最容易被误解的前10个话题之一 count() 是一个特殊的函 ...
- Android开发之利用SQLite进行数据存储
Android开发之利用SQLite进行数据存储 Android开发之利用SQLite进行数据存储 SQLite数据库简单介绍 Android中怎样使用SQLite 1 创建SQLiteOpenHel ...
- DSSA特定领域软件体系结构
一.何为DSSA 特定领域软件架构(Domain Specific Software Architecture,DSSA)是一种有效实现特定领域软件重用的手段.简单地说,DSSA就是在一个特定应用领域 ...
- [刘阳Java]_MySQL数据优化总结_查询备忘录
数据库优化是在后端开发中必备技能,今天写一篇MySQL数据优化的总结,供大家看看 一.MySQL数据库优化分类 我们通过一个图片形式来看看数据优化一些策略问题 不难看出,优化有两条路可以选择:硬件与技 ...
- python-数据描述与分析2(利用Pandas处理数据 缺失值的处理 数据库的使用)
2.利用Pandas处理数据2.1 汇总计算当我们知道如何加载数据后,接下来就是如何处理数据,虽然之前的赋值计算也是一种计算,但是如果Pandas的作用就停留在此,那我们也许只是看到了它的冰山一角,它 ...
随机推荐
- LaTeX 生成黑底白字的 PDF
最近需要深夜看论文,然而白底的 PDF 看久了眼睛很难受,想转换成黑底的.正好我有论文的 LaTeX 源码,因此可以直接编译黑底的 PDF 出来. 使用 darkmode 宏包 CTAN 上有一个 L ...
- vue中代理解决跨域
跨域是什么 简单的讲就是你在一个地方使用另一个地方的资源,被浏览器给挡下来了,不让不用!当然,它挡下来是有自己理由的:为了安全(╬▔皿▔)╯. 解决跨域 我是用vue开发的,就vue代理模式解决跨域说 ...
- .NET 压缩/解压文件
本文为大家介绍下.NET解压/压缩zip文件.虽然解压缩不是啥核心技术,但压缩性能以及进度处理还是需要关注下,针对使用较多的zip开源组件验证,给大家提供技术选型 目前了解到的常用技术方案有Syste ...
- tarjan—算法的神(一)
本篇包含 tarjan 求强连通分量.边双连通分量.割点 部分, tarjan 求点双连通分量.桥(割边)在下一篇. 伟大的 Robert Tarjan 创造了众多被人们所熟知的算法及数据结构,最著名 ...
- 数据结构 - 关键路径(AOE)
数据结构 - 关键路径求解
- 深度学习/NLP中的Attention注意力机制
首先是整体认知,Attention的位置: 传送门1:Attention 机制 传送门2:Attention用于NLP的一些小结 一句话概括:Attention就是从关注全局到关注重点. 借鉴了人类视 ...
- SQL Server – History Table (Audit/Archive Table)
前言 续上一篇的 Soft Delete 后, 我们继续来看看 History Table (Audit/Archive Table). Archive Table 市场上有了这样叫, 但我觉得它比较 ...
- c语言 宏的一些深层应用(##,#,宏函数)
"##" 宏拼接 #define CONCATENATE(a, b) a ## b CONCATENATE(student_, 1) // 将a和b拼接起来变成一个新的变量 -&g ...
- Maven高级——属性
属性 自定义属性 定义属性 <!-- 定义属性--> <properties> <spring.version>5.2.10.RELEASE</spring. ...
- QT框架中的缓存:为什么有QHash和QMap,还设计了QCache和QContiguousCache?
简介 本文介绍了QT框架中可用于缓存的几个数据类型各自的特点:通过本文读者可以了解到为什么有QHash和QMap,还设计了QCache和QContiguousCache? 目录 QHash和QMap有 ...