SMOTE算法解决样本不平衡
首先,看下Smote算法之前,我们先看下当正负样本不均衡的时候,我们通常用的方法:
- 抽样
常规的包含过抽样、欠抽样、组合抽样
过抽样:将样本较少的一类sample补齐
欠抽样:将样本较多的一类sample压缩
组合抽样:约定一个量级N,同时进行过抽样和欠抽样,使得正负样本量和等于约定量级N
这种方法要么丢失数据信息,要么会导致较少样本共线性,存在明显缺陷
- 权重调整
常规的包括算法中的weight,weight matrix
改变入参的权重比,比如boosting中的全量迭代方式、逻辑回归中的前置的权重设置
这种方式的弊端在于无法控制合适的权重比,需要多次尝试
- 核函数修正
通过核函数的改变,来抵消样本不平衡带来的问题
这种使用场景局限,前置的知识学习代价高,核函数调整代价高,黑盒优化
- 模型修正
通过现有的较少的样本类别的数据,用算法去探查数据之间的特征,判读数据是否满足一定的规律
比如,通过线性拟合,发现少类样本成线性关系,可以新增线性拟合模型下的新点
实际规律比较难发现,难度较高
算法基本原理:
(1)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
(2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
(3)对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本。
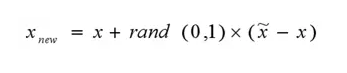
Smote算法的思想其实很简单,先随机选定n个少类的样本,如下图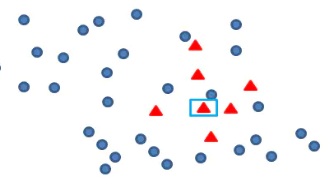
再找出最靠近它的m个少类样本,如下图
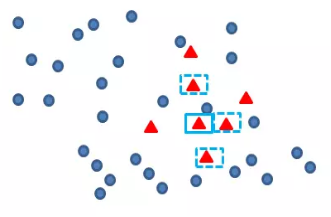
再任选最临近的m个少类样本中的任意一点,
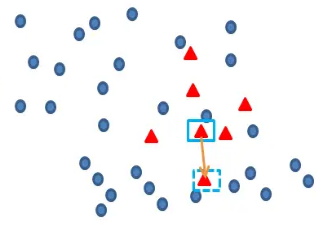
伪代码:
function SMOTE(T, N, k)
Input: T; N; k # T:少数类样本数目
# N:过采样的数目
# K:最近邻的数量
Output: (N/100) * T # 合成的少数类样本
Variables: Sample[][] # 存放原始少数类样本
newindex #控制合成数量
initialized to 0;
Synthetic[][]
if N < 100 then
Randomize the T minority class samples
T = (N/100)*T
N = 100
end if
N = (int)N/100 # 假定SMOTE的数量是100的整数倍
for i = 1 to T do
Compute k nearest neighbors for i, and save the indices in the nnarray
POPULATE(N, i, nnarray)
end for
end function
Algorithm 2 Function to generate synthetic samples
function POPULATE(N, i, nnarray)
Input: N; i; nnarray # N:生成的样本数量
# i:原始样本下标
# nnarray:存放最近邻的数组
Output: N new synthetic samples in Synthetic array
while N != 0 do
nn = random(1,k)
for attr = 1 to numattrs do # numattrs:属性的数量
Compute: dif = Sample[nnarray[nn]][attr] − Sample[i][attr]
Compute: gap = random(0, 1)
Synthetic[newindex][attr] = Sample[i][attr] + gap * dif
end for
newindex + +
N − −
end while
end function
项目经验:
1.采样方法比直接调整阈值的方法要好。
2.使用采样方法可以提高模型的泛化能力,存在过拟合风险,最好联合正则化同时使用。
3.过采样结果比欠采样多数时间稳定,但是还是要具体问题具体分析,主要还是看数据的分布,SMOTE效果还是不错的。
4.和SMOTE算法使用的模型最好是可以防止过拟合的模型,随机森林,L2正则+逻辑回归,XGBoost等模型。
SMOTE算法解决样本不平衡的更多相关文章
- 【深度学习】Focal Loss 与 GHM——解决样本不平衡问题
Focal Loss 与 GHM Focal Loss Focal Loss 的提出主要是为了解决难易样本数量不平衡(注意:这有别于正负样本数量不均衡问题)问题.下面以目标检测应用场景来说明. 一些 ...
- 处理样本不平衡的LOSS—Focal Loss
0 前言 Focal Loss是为了处理样本不平衡问题而提出的,经时间验证,在多种任务上,效果还是不错的.在理解Focal Loss前,需要先深刻理一下交叉熵损失,和带权重的交叉熵损失.然后我们从样本 ...
- 类别不平衡问题之SMOTE算法(Python imblearn极简实现)
类别不平衡问题类别不平衡问题,顾名思义,即数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题.例如逻辑回归即不适合处理类别不平衡问题,例如逻辑回归在欺诈检测问题 ...
- Python:SMOTE算法——样本不均衡时候生成新样本的算法
Python:SMOTE算法 直接用python的库, imbalanced-learn imbalanced-learn is a python package offering a number ...
- 采用boosting思想开发一个解决二分类样本不平衡的多估计器模型
# -*- coding: utf-8 -*- """ Created on Wed Oct 31 20:59:39 2018 脚本描述:采用boosting思想开发一个 ...
- [ML] 解决样本类别分布不均衡的问题
转自:3.4 解决样本类别分布不均衡的问题 | 数据常青藤 (组织排版上稍有修改) 3.4 解决样本类别分布不均衡的问题 说明:本文是<Python数据分析与数据化运营>中的“3.4 解决 ...
- 过采样中用到的SMOTE算法
平时很多分类问题都会面对样本不均衡的问题,很多算法在这种情况下分类效果都不够理想.类不平衡(class-imbalance)是指在训练分类器中所使用的训练集的类别分布不均.比如说一个二分类问题,100 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- 题目1437:To Fill or Not to Fill:贪心算法解决加油站选择问题(未解决)
//贪心算法解决加油站选择问题 //# include<iostream> # include<stdio.h> using namespace std; # include& ...
- xsank的快餐 » Python simhash算法解决字符串相似问题
xsank的快餐 » Python simhash算法解决字符串相似问题 Python simhash算法解决字符串相似问题
随机推荐
- 手撕vector
Myclass.h #pragma once #include<iostream> #include<Windows.h> #define SUCCESS 1 // 成功 #d ...
- AT_kupc2019_g ABCのG問題题解
这题的难度不怎么好说,不过我认为还是挺简单的. 我们可以把答案看成由多个子图构成的图,这样我们只需要手打一个小子图,从中推出完整的答案. - 把小于子图范围的地方填上子图的字母 - 如果这个点的横坐标 ...
- 中电金信鲸视:以AI视觉技术为复杂行业场景装上“火眼金睛”
作为人工智能和计算机视觉的交叉领域,智能视觉通过仿生人类视觉机能,对不同形式的视觉输入进行处理.理解和决策.现今,智能视觉已成为应用广泛.市场覆盖大.形式多样的产业方向,得到了国家政策的大力支持. ...
- Qt编写的项目作品7-视频监控系统
一.功能特点 (一)软件模块 视频监控模块,各种停靠小窗体子模块,包括设备列表.图文警情.窗口信息.云台控制.预置位.巡航设置.设备控制.悬浮地图.网页浏览等. 视频回放模块,包括本地回放.远程回放. ...
- clip-retrieval检索本地数据集
clip-retrieval检索本地数据集 from clip_retrieval.clip_client import ClipClient, Modality from tqdm import t ...
- python创建项目虚拟环境
创建一个文件夹用于存放你的虚拟环境 cd 到存放虚拟环境的地址 安装虚拟环境库: pip3 install virtualenv 创建虚拟环境:python3 -m venv 环境名称 激活虚拟环境: ...
- 获取不同型号手机小程序导航栏的高度(uniapp)
uni.getSystemInfo({ success: function(e) { Vue.prototype.StatusBar = e.statusBarHeight; let custom = ...
- CDS标准视图:会计员 I_AccountingClerk
视图名称:会计员 I_AccountingClerk 视图类型:基础 视图代码: 点击查看代码 @AbapCatalog: { sqlViewName: 'IFIACCCLERK', // compi ...
- springboot+springsecurity项目
https://blog.csdn.net/qq_36748248/article/details/120932954 https://blog.csdn.net/weixin_41207479/ar ...
- Python生成成绩报告单:从理论到实践
在教育信息化日益普及的今天,自动化生成和处理学生成绩报告单已成为学校和教育机构的一项重要任务.Python作为一种功能强大且易于学习的编程语言,非常适合用于这种数据处理和报告生成任务.本文将详细介绍如 ...