Python数据分析Pandas的编程经验总结
Pandas的api 参考手册DataFrame部分:https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
数据处理部分:
待处理的数据:
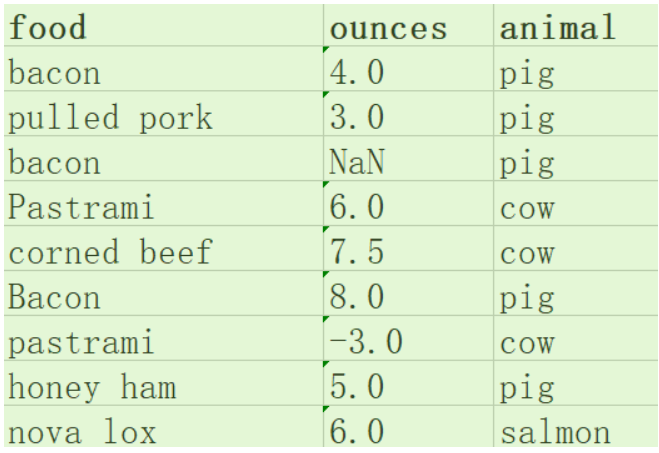
处理要求:1.food栏,大小写统一,2.删除NaN行,3.把ounces中的负值取绝对值,4.把food名称相同的字段合并,合并后ounces的值为合并前他们的平均值
代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
df = pd.read_csv('E:/python3Project/11.csv')
#print(df)
df['food'] = df['food'].str.lower() #统一大小写字母 df.dropna(inplace=True) #删除数据缺失的记录
print(df)
df['ounces']=df['ounces'].apply(lambda a:abs(a)) #负值不合法,取绝对值
#print(df)
#查找food重复的记录,分组求其平均值
#print(df['food'].duplicated(keep=False))
#d_rows = df[df['food'].duplicated(keep=False)] # keep=False的意思是把所有的food列下重复的字段都找出来
#print(d_rows)
#g_items = d_rows.groupby('food').mean() # 学学groupBy
#print(g_items)
#g_items['food']=g_items.index #效果就是新增一列food
#print(g_items) #把第一个出现的bacon替换成平均值
df.loc[0,'ounces']=df[df['food'].isin(['bacon'])].mean()['ounces']
# 删除第二个ounce
df.drop(df.index[4],inplace=True)
print(df)
df.index =range(len(df)) # 重新把row的index排列一下,按照连贯顺序,从小到大
print(df) #把第一个出现的pastrami替换成平均值
df.loc[0,'ounces']=df[df['food'].isin(['pastrami'])].mean()['ounces']
# 删除第二个ounce
df.drop(df.index[4],inplace=True)
print(df)
df.index =range(len(df)) # 重新把row的index排列一下,按照连贯顺序,从小到大
print(df)
Python数据分析Pandas的编程经验总结的更多相关文章
- Python/Numpy大数据编程经验
Python/Numpy大数据编程经验 1.边处理边保存数据,不要处理完了一次性保存.不然程序跑了几小时甚至几天后挂了,就啥也没有了.即使部分结果不能实用,也可以分析程序流程的问题或者数据的特点. ...
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- Python数据分析--Pandas知识点(二)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) 下面将是在知识点一的基础上继续总结. 13. 简单计算 新建一个数据表 ...
- Python数据分析-Pandas(Series与DataFrame)
Pandas介绍: pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. Pandas的主要功能: 1)具备对其功能的数据结构DataFrame.Series 2)集成时间序 ...
- python 数据分析--pandas
接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利用pandas的DataFrames进行统计分析 ...
- Python数据分析Pandas库方法简介
Pandas 入门 Pandas简介 背景:pandas是一个Python包,提供快速,灵活和富有表现力的数据结构,旨在使“关系”或“标记”数据的使用既简单又直观.它旨在成为在Python中进行实际, ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- Python数据分析Pandas库之熊猫(10分钟二)
pandas 10分钟教程(二) 重点发法 分组 groupby('列名') groupby(['列名1','列名2',.........]) 分组的步骤 (Splitting) 按照一些规则将数据分 ...
- Python数据分析Pandas库之熊猫(10分钟一)
pandas熊猫10分钟教程 排序 df.sort_index(axis=0/1,ascending=False/True) df.sort_values(by='列名') import numpy ...
随机推荐
- Android中获取实时网速(2)
一.实现思路: 1.Android提供有获取当前总流量的方法 2.上一秒 减去 下一面的流量差便是网速 3.注意计算 二.计算网速的工具类: package imcs.cb.com.viewappli ...
- vue学习指南:第七篇(详细) - Vue的 组件通信
Vue 的 父传子 子传父 一.父组件向子组件传值: 父传子 把需要的数据 传递给 子组件,以数据绑定(v-bind)的形式,传递到子组件内部,供子组件使用 缩写是(:) 1.创建子组件,在src/ ...
- Java面试题:JVM中的类加载机制
JVM 的类加载机制是指 JVM 把描述类的数据从 .class 文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的 Java 类型,这就是 JVM 的类加载机制. 类 ...
- nullptr与NULL
NULL NULL can be defined as any null pointer constant. Thus existing code can retain definitions of ...
- Graph Embedding Review:Graph Neural Network(GNN)综述
作者简介: 吴天龙 香侬科技researcher 公众号(suanfarensheng) 导言 图(graph)是一个非常常用的数据结构,现实世界中很多很多任务可以描述为图问题,比如社交网络,蛋白体 ...
- webapi序列化控制
我们都知道在使用WebApi的时候Controller会自动将Action的返回值自动进行各种序列化处理(序列化为json,xml等),但是如果Controller的自动序列化后的结果不是我们想要的该 ...
- 【oracle】存储过程:将select查询的结果存到变量中
- SQL Server 迁移数据库 (二)分离和附加
分离和附加其实比导入和导出,步骤要少一些,但是数据量大的话,跨服务器拷贝数据文件可能要慢一些 1. 分离数据库 这里最好选择断开链接,断开之前要确保你记得数据库的路径,一般默认都是C:\Program ...
- F5 开发
产品试用申请 https://www.f5.com/trials 默认终端登录密码 root/default 默认网页登录信息 admin/admin logstash添加user agent插件 h ...
- linux翻页及字符串搜索操作
向下翻动一屏幕: space, ctrl + f, ctrl + v, ctrl + F 向下翻动半屏: d, ctrl + D 向下翻动一行: 回车, e, j 向上翻动一屏幕: b, ctrl + ...