zabbix Server 4.0监控Flume关键参数
zabbix Server 4.0监控Flume关键参数
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
Flume本身提供了http, ganglia的监控服务。当然我们也可以使用JMX的方式去监控Flume,然后只要能集成JMX监控的监控系统应该都能实现简介监控Flume,有网友说,监控Flume我们需要修改其源码让他支持zabbix监控,当然这得让咱们运维人员懂Java开发才行,而且还得有一定的功底,要是改出Bug了反而麻烦。Ganglia监控起来的确方便,但我们公司的监控系统使用的是Zabbix,有的小伙伴使用的是Open Falcon,我们建议大家统一一套监控系统,当然有2套监控系统也是可以的,留作备份也是不错的。
本片博客会手把手教你使用Zabbix Server监控Flume的重要参数。其实就是利用Flume本身提供的HTTP借口,关于zabbix和flume的部署方式我这里就不再赘述了。我假设你已经将zabbix监控系统和flue-ng进程启动成功啦。接下来我们就来动手干活。
一.启用Flume自身的Http监控功能
1>.查看Flume进程的启动脚本
[root@flume112 ~]# cat /soft/flume/conf/job/flume-conf-p2p01.properties
#定义别名
agent.sources = kafkaSource
agent.channels = kafkaSource
agent.sinks = hdfsSink #绑定关系
agent.sources.kafkaSource.channels = kafkaSource
agent.sinks.hdfsSink.channel = kafkaSource #指定source源为kafka source
agent.sources.kafkaSource.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafkaSource.kafka.bootstrap.servers = 10.1.2.114:,10.1.2.115:,10.1.2.116:,10.1.2.117:,10.1.2.118:
agent.sources.kafkaSource.topic = account-check
agent.sources.kafkaSource.kafka.consumer.group.id = -account-check
agent.sources.kafkaSource.kafka.consumer.max.partition.fetch.bytes =
agent.sources.kafkaSource.kafka.consumer.heartbeat.interval.ms =
agent.sources.kafkaSource.kafka.consumer.rebalance.timeout.ms =
agent.sources.kafkaSource.kafka.consumer.fetch.min.bytes =
agent.sources.kafkaSource.kafka.consumer.session.timeout.ms =
agent.sources.kafkaSource.kafka.consumer.request.timeout.ms =
agent.sources.kafkaSource.interceptors = i1
agent.sources.kafkaSource.interceptors.i1.userIp = true
agent.sources.kafkaSource.interceptors.i1.type = host #指定channel类型为kafka
agent.channels.kafkaSource.type = org.apache.flume.channel.kafka.KafkaChannel
agent.channels.kafkaSource.kafka.bootstrap.servers = 10.1.2.114:,10.1.2.115:,10.1.2.116:,10.1.2.117:,10.1.2.118:
agent.channels.kafkaSource.kafka.topic = channel.account-check--
agent.channels.kafkaSource.kafka.consumer.group.id = -channel.account-check--
agent.channels.kafkaSource.kafka.consumer.heartbeat.interval.ms =
agent.channels.kafkaSource.kafka.consumer.rebalance.timeout.ms =
agent.channels.kafkaSource.kafka.consumer.fetch.min.bytes =
agent.channels.kafkaSource.kafka.consumer.session.timeout.ms =
agent.channels.kafkaSource.kafka.consumer.request.timeout.ms = #指定sink的类型为hdfs
agent.sinks.hdfsSink.type = hdfs
agent.sinks.hdfsSink.hdfs.path = hdfs://hdfs-ha/user/p2p_kafka/%Y%m%d
agent.sinks.hdfsSink.hdfs.filePrefix = ---112_p2p01_%Y%m%d_%H
agent.sinks.hdfsSink.hdfs.fileSuffix = .txt
agent.sinks.hdfsSink.hdfs.useLocalTimeStamp = true
agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType=DataStream
agent.sinks.hdfsSink.hdfs.rollCount =
agent.sinks.hdfsSink.hdfs.rollSize =
agent.sinks.hdfsSink.hdfs.rollInterval =
agent.sinks.hdfsSink.hdfs.batchSize =
agent.sinks.hdfsSink.hdfs.threadsPoolSize =
agent.sinks.hdfsSink.hdfs.idleTimeout =
agent.sinks.hdfsSink.hdfs.minBlockReplicas =
agent.sinks.hdfsSink.hdfs.callTimeout=
agent.sinks.hdfsSink.hdfs.request-timeout=
agent.sinks.hdfsSink.hdfs.connect-timeout=
[root@flume112 ~]#
[root@flume112 ~]# cat /soft/flume/conf/job/flume-conf-p2p01.properties
[root@flume112 ~]# cat /soft/flume/shell/start_flume_p2p01.sh
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com
#Data:Thu Oct :: CST #启动flume自身的监控参数,默认执行以下脚本
nohup flume-ng agent -c /soft/flume/conf/job/ --conf-file=/soft/flume/conf/job/flume-conf-p2p01.properties --name agent -Dflume.monitoring.type=http -Dflume.monitoring.port= -Dflume.root.logger=INFO,console >> /soft/flume/logs/flume-http-p2p01.log >& & [root@flume112 ~]#
2>.我们启动上面的Flume agent后
[root@flume112 ~]# curl 10.1.2.112:/metrics | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
165k --:--:-- --:--:-- --:--:-- 177k
{
"SINK.hdfsSink": { #这是HDFS SINK监控数据。
"ConnectionCreatedCount": "", #下一个阶段(或存储系统)创建链接的数量(如HDFS创建一个文件)。
"ConnectionClosedCount": "", #下一个阶段(或存储系统)关闭链接的数量(如HDFS中关闭一个文件)。
"Type": "SINK", #很显然,这里是SINK监控项,类型为SINK
"BatchCompleteCount": "", #批量处理event的个数等于批处理大小的数量。
"BatchEmptyCount": "", #批量处理event的个数为0的数量(空的批量的数量),如果数量很大表示source写入数据的速度比sink处理数据的速度慢很多。
"EventDrainAttemptCount": "", #sink尝试写出到存储的事件总数量。
"StartTime": "", #channel启动时的毫秒值时间。
"EventDrainSuccessCount": "", #sink成功写出到存储的事件总数量。
"BatchUnderflowCount": "", #批量处理event的个数小于批处理大小的数量(比sink配置使用的最大批量尺寸更小的批量的数量),如果该值很高也表示sink比source更快。
"StopTime": "", #channel停止时的毫秒值时间,为0表示一直在运行。
"ConnectionFailedCount": "" #下一个阶段(或存储系统)由于错误关闭的连接数量(如HDFS上一个新创建的文件由于超市而关闭)。
},
"CHANNEL.kafkaSource": { #这是KAFKA SOURCE监控数据。
"KafkaEventGetTimer": "", #KAFKA事件获取计数器。
"ChannelSize": "", #目前channel中事件的总数量,目前仅支持File Channel,Memory channel的统计数据。我这里使用的是Kafka channel。
"EventTakeAttemptCount": "", #sink尝试从channel拉取事件的总次数。这不意味着每次时间都被返回,因为sink拉取的时候channel可能没有任何数据。
"StartTime": "", #channel启动时的毫秒值时间。
"KafkaCommitTimer": "", #KAFKA提交计数器。
"ChannelCapacity": "", #channel的容量,目前仅支持File Channel,Memory channel的统计数据。我这里使用的是Kafka channel。
"ChannelFillPercentage": "1.7976931348623157E308", #channel已填入的百分比。
"Type": "CHANNEL", #很显然,这里是CHANNEL监控项,类型为CHANNEL。
"EventTakeSuccessCount": "", #sink成功从channel读取事件的总数量。
"RollbackCount": "", #回滚的次数。
"KafkaEventSendTimer": "", #KAFKA事件发送计数器。
"EventPutAttemptCount": "", #Source尝试写入Channe的事件总次数。
"EventPutSuccessCount": "", #成功写入channel且提交的事件总次数。
"StopTime": "" #channel停止时的毫秒值时间,为0表示一直在运行。
},
"SOURCE.kafkaSource": {
"KafkaEventGetTimer": "", #KAFKA事件获取计数器。
"AppendBatchAcceptedCount": "", #成功提交到channel的批次的总数量。
"AppendReceivedCount": "", #每批只有一个事件的事件总数量(与RPC调用的一个append调用相等)。
"EventAcceptedCount": "", #成功写出到channel的事件总数量。
"StartTime": "", #source启动时的毫秒值时间。
"AppendBatchReceivedCount": "", #接收到事件批次的总数量。
"KafkaCommitTimer": "", #KAFKA提交计数器。
"EventReceivedCount": "", #目前为止source已经接收到的事件总数量。
"Type": "SOURCE", #很显然,这里是SOURCE监控项,类型为SOURCE。
"KafkaEmptyCount": "", #KAFKA空的批量的数量。
"AppendAcceptedCount": "", #逐条录入的次数,单独传入的事件到Channel且成功返回的事件总数量。
"OpenConnectionCount": "", #目前与客户端或sink保持连接的总数量,目前仅支持avro source展现该度量。
"StopTime": "" #source停止时的毫秒值时间,为0表示一直在运行。
}
}
[root@flume112 ~]#
温馨提示:
上图需要注意的点我已经用深颜色标识出来啦,当然,如果你还要想了解更多度量值,可参考官方文档:http://flume.apache.org/FlumeUserGuide.html#monitoring。
3>.上面是使用jq工具查看Flume自身监控的,当然,我们也可以使用sed命令将上面的内容格式化一下
[root@flume112 ~]# curl 10.1.2.112:/metrics >/dev/null |sed -e 's/\([,]\)\s*/\1\n/g' -e 's/[{}]/\n/g' -e 's/[",]//g'
SINK.hdfsSink:
ConnectionCreatedCount:
ConnectionClosedCount:
Type:SINK
BatchCompleteCount:
BatchEmptyCount:
EventDrainAttemptCount:
StartTime:
EventDrainSuccessCount:
BatchUnderflowCount:
StopTime:
ConnectionFailedCount:
CHANNEL.kafkaSource:
KafkaEventGetTimer:
ChannelSize:
EventTakeAttemptCount:
StartTime:
KafkaCommitTimer:
ChannelCapacity:
ChannelFillPercentage:1.7976931348623157E308
Type:CHANNEL
EventTakeSuccessCount:
RollbackCount:
KafkaEventSendTimer:
EventPutAttemptCount:
EventPutSuccessCount:
StopTime:
SOURCE.kafkaSource:
KafkaEventGetTimer:
AppendBatchAcceptedCount:
AppendReceivedCount:
EventAcceptedCount:
StartTime:
AppendBatchReceivedCount:
KafkaCommitTimer:
EventReceivedCount:
Type:SOURCE
KafkaEmptyCount:
AppendAcceptedCount:
OpenConnectionCount:
StopTime:
[root@flume112 ~]#
[root@flume112 ~]# curl 10.1.2.112:/metrics >/dev/null |sed -e 's/\([,]\)\s*/\1\n/g' -e 's/[{}]/\n/g' -e 's/[",]//g' | grep EventDrainSuccessCount #我们可以进一步拿到某个监控参数!
EventDrainSuccessCount:
[root@flume112 ~]#
4>.使用awk获取某个参数的值
[root@flume112 ~]# curl 10.1.2.112:/metrics >/dev/null |sed -e 's/\([,]\)\s*/\1\n/g' -e 's/[{}]/\n/g' -e 's/[",]//g' | grep EventDrainSuccessCount
EventDrainSuccessCount:
[root@flume112 ~]#
[root@flume112 ~]#
[root@flume112 ~]# curl 10.1.2.112:/metrics >/dev/null |sed -e 's/\([,]\)\s*/\1\n/g' -e 's/[{}]/\n/g' -e 's/[",]//g' | grep EventDrainSuccessCount | awk -F ':' '{print $2}'
[root@flume112 ~]#
[root@flume112 ~]#
二.zabbix agent端配置
1>.查看zabbix agent的主配置文件
[root@flume112 ~]# cat /etc/zabbix/zabbix_agentd.conf | grep Include | grep -v ^#
Include=/etc/zabbix/zabbix_agentd.d/*.conf
[root@flume112 ~]#
2>.编写采集数据的脚本
[root@flume112 ~]# cat /etc/zabbix/zabbix_agentd.d/flume_monitor.sh
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com
#Data:Thu Oct :: CST FLUME_PORT=$
METRIC_VALUE=$ curl 127.0.0.1:"$FLUME_PORT"/metrics >/dev/null |sed -e 's/\([,]\)\s*/\1\n/g' -e 's/[{}]/\n/g' -e 's/[",]//g' | grep "$METRIC_VALUE" | awk -F ':' '{print $2}'
[root@flume112 ~]#
[root@flume112 ~]# ll /etc/zabbix/zabbix_agentd.d/flume_monitor.sh
-rwxr-xr-x root root May : /etc/zabbix/zabbix_agentd.d/flume_monitor.sh
[root@flume112 ~]#
[root@flume112 ~]# chmod +x /etc/zabbix/zabbix_agentd.d/flume_monitor.sh #别忘了添加执行权限
[root@flume112 ~]#
[root@flume112 ~]# ll /etc/zabbix/zabbix_agentd.d/flume_monitor.sh
-rwxr-xr-x root root May : /etc/zabbix/zabbix_agentd.d/flume_monitor.sh
[root@flume112 ~]#
[root@flume112 ~]# /etc/zabbix/zabbix_agentd.d/flume_monitor.sh EventReceivedCount #我们光编写脚本添加了权限还是不够的,我们得手动验证一下脚本是否可用哟! [root@flume112 ~]#
[root@flume112 ~]# /etc/zabbix/zabbix_agentd.d/flume_monitor.sh ChannelFillPercentage
1.7976931348623157E308
[root@flume112 ~]#
[root@flume112 ~]# /etc/zabbix/zabbix_agentd.d/flume_monitor.sh EventAcceptedCount [root@flume112 ~]#
[root@flume112 ~]# /etc/zabbix/zabbix_agentd.d/flume_monitor.sh EventAcceptedCount [root@flume112 ~]#
3>.自定义zabbix agent监控配置文件
[root@flume112 ~]# cat /etc/zabbix/zabbix_agentd.d/flume_monitor.conf
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com
#Data:Thu Oct :: CST UserParameter=FLUME_STATUS[*],/etc/zabbix/zabbix_agentd.d/flume_monitor.sh $1 $
[root@flume112 ~]#
4>.重启zabbix agent服务
[root@flume112 ~]# systemctl restart zabbix-agent
[root@flume112 ~]#
[root@flume112 ~]# systemctl status zabbix-agent
● zabbix-agent.service - Zabbix Agent
Loaded: loaded (/usr/lib/systemd/system/zabbix-agent.service; enabled; vendor preset: disabled)
Active: active (running) since Thu -- :: CST; 6s ago
Process: ExecStop=/bin/kill -SIGTERM $MAINPID (code=exited, status=/SUCCESS)
Process: ExecStart=/usr/sbin/zabbix_agentd -c $CONFFILE (code=exited, status=/SUCCESS)
Main PID: (zabbix_agentd)
CGroup: /system.slice/zabbix-agent.service
├─ /usr/sbin/zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf
├─ /usr/sbin/zabbix_agentd: collector [idle sec]
├─ /usr/sbin/zabbix_agentd: listener # [waiting for connection]
├─ /usr/sbin/zabbix_agentd: listener # [waiting for connection]
├─ /usr/sbin/zabbix_agentd: listener # [waiting for connection]
└─ /usr/sbin/zabbix_agentd: active checks # [idle sec] May :: flume112.aggrx systemd[]: Starting Zabbix Agent...
May :: flume112.aggrx systemd[]: zabbix-agent.service: Supervising process which is not our child. We'll most likely not notice when it exits.
May :: flume112.aggrx systemd[]: Started Zabbix Agent.
[root@flume112 ~]#
三.在zabbix server端进行取值
1>.创建模板

2>.点击目标名称
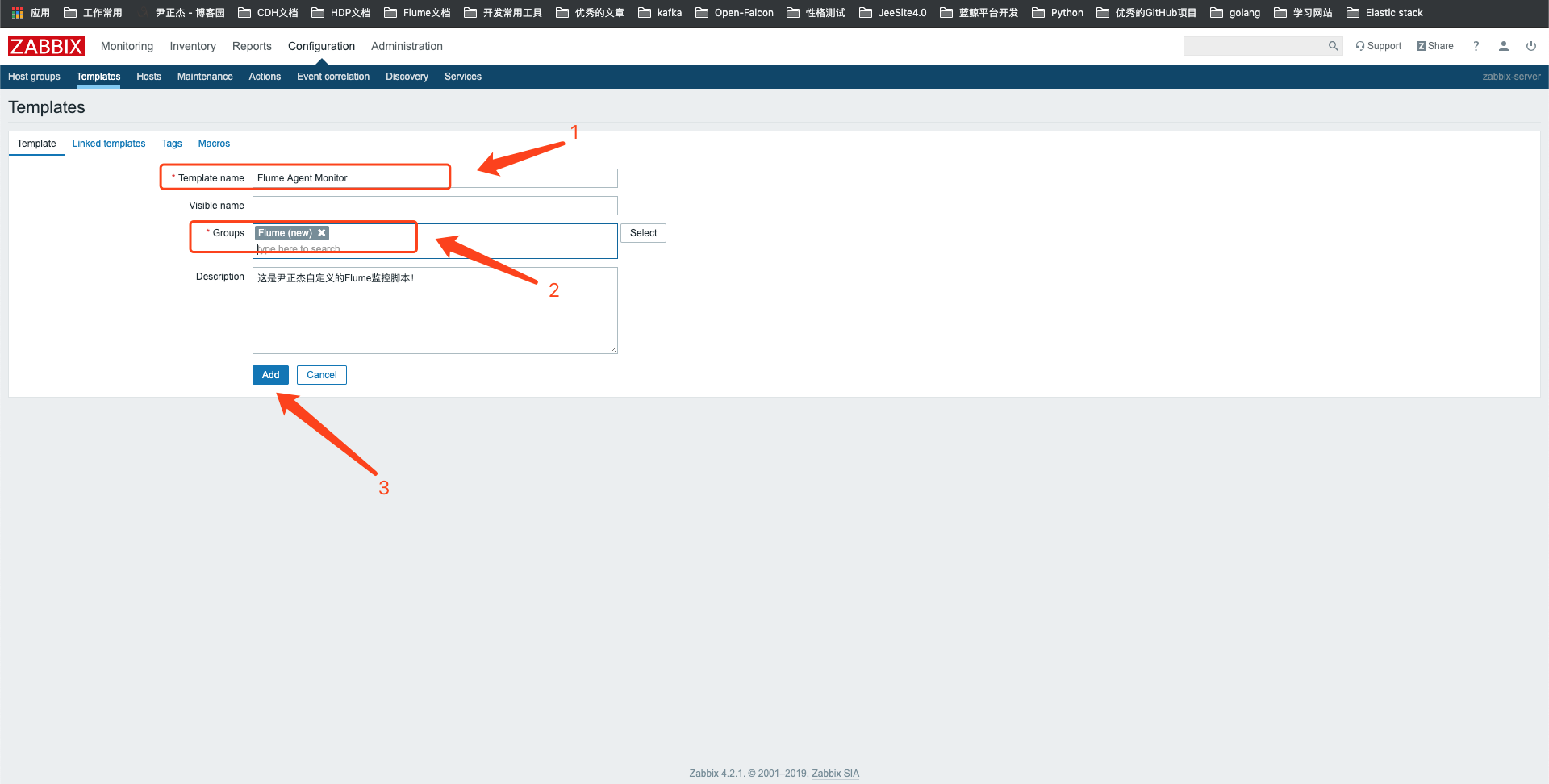
3>.模板创建完成
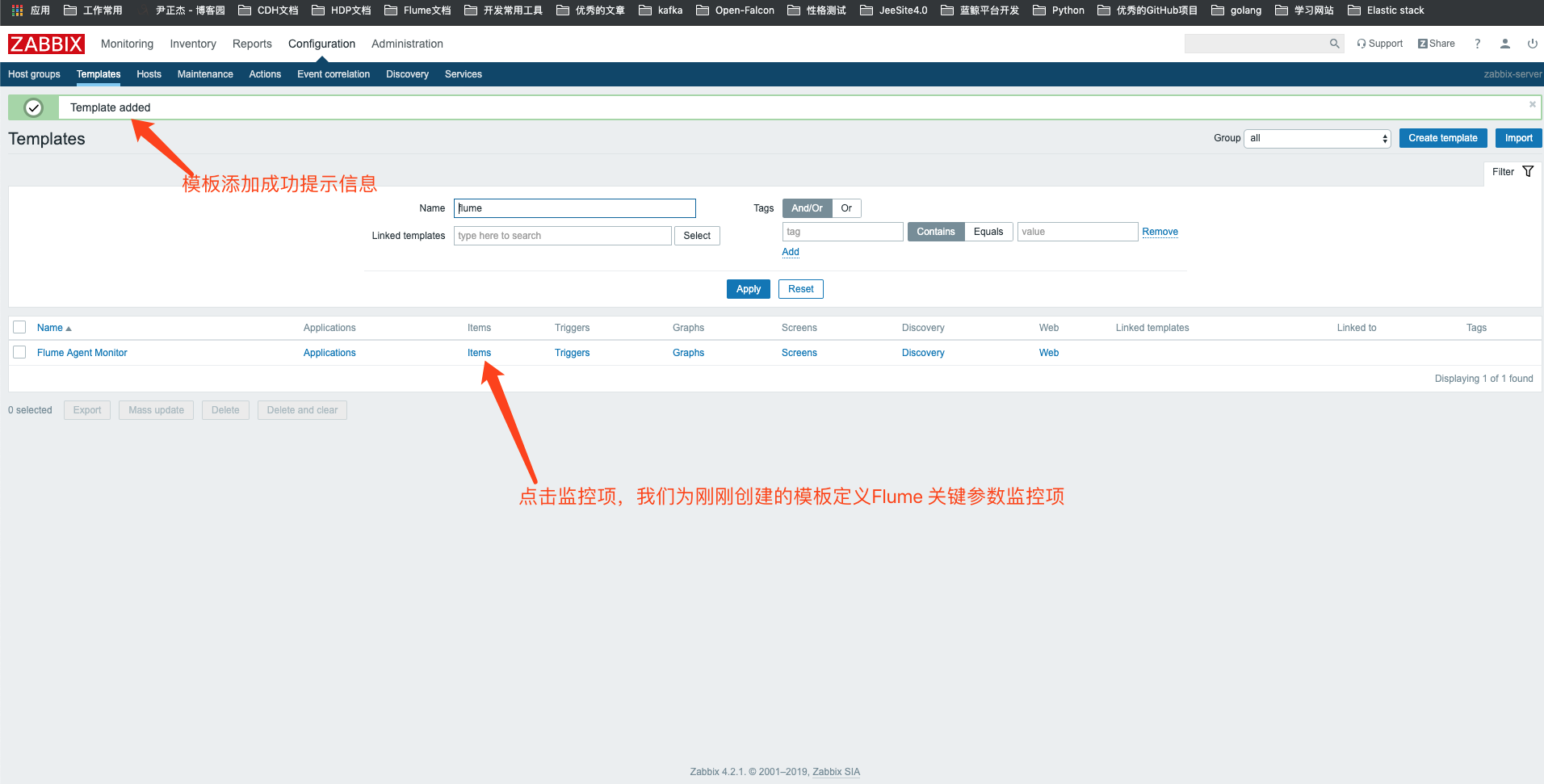
4>.为刚刚创建的模板创建监控项(item)
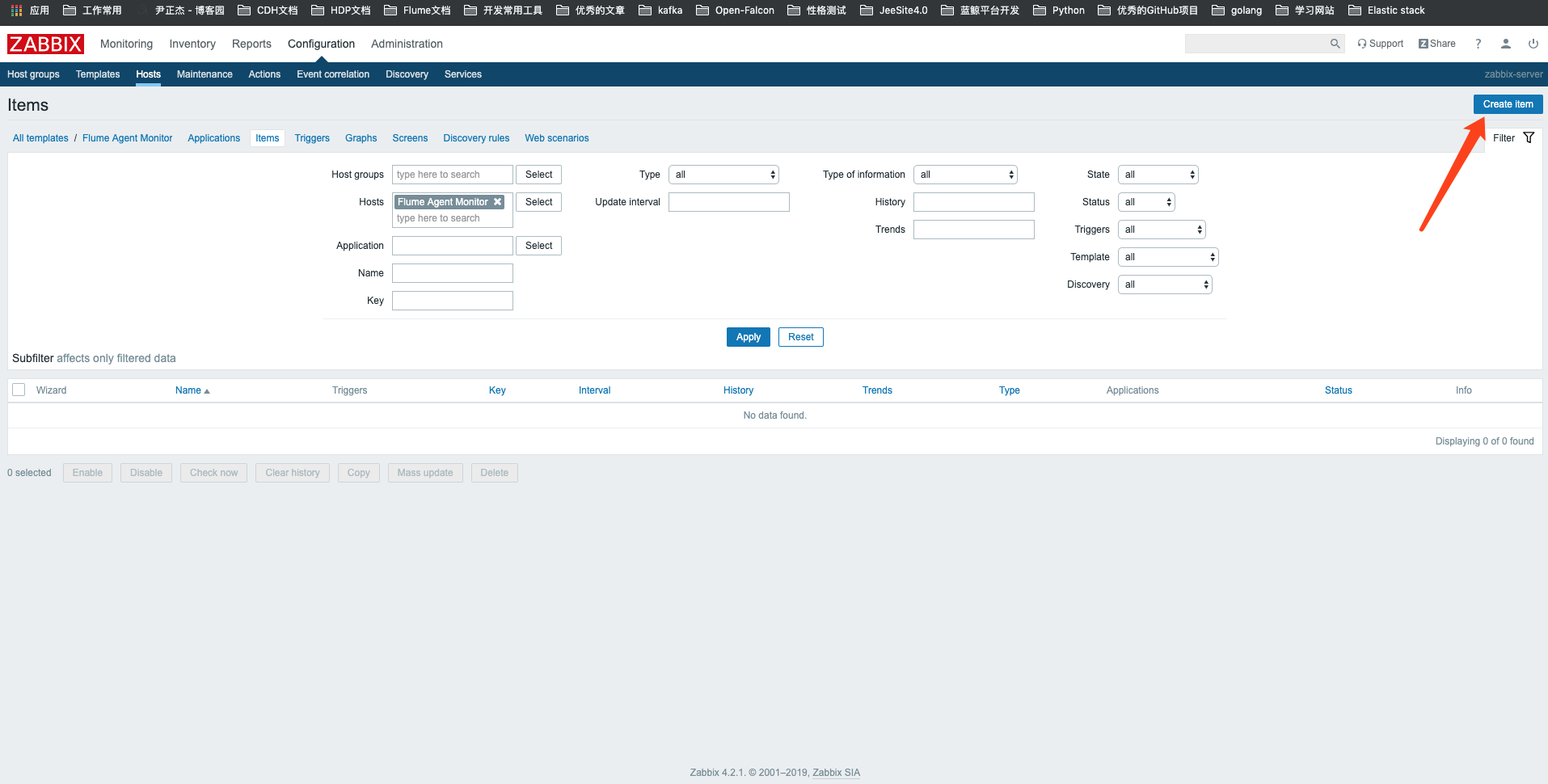
5>.自定义item
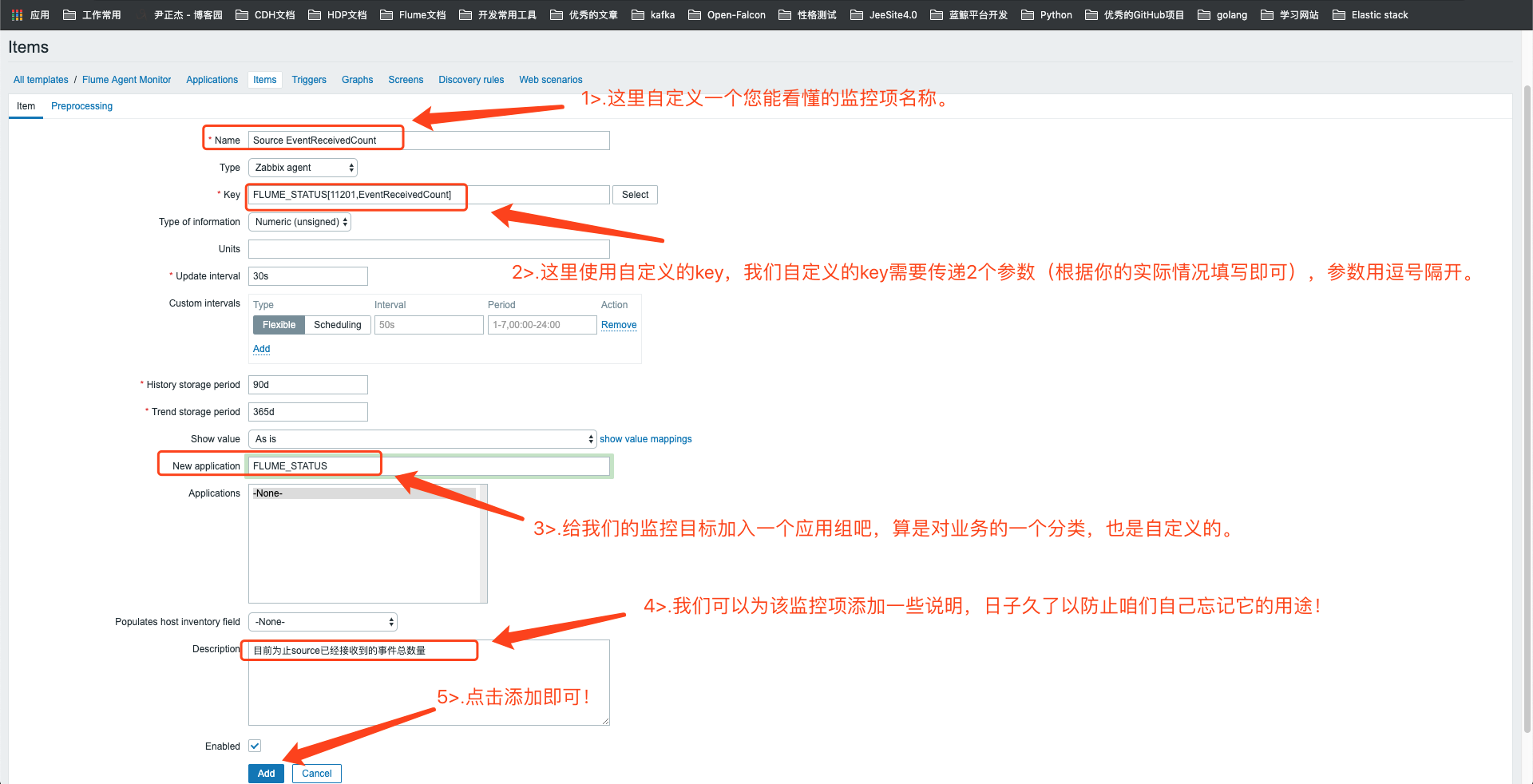
6>.添加完成
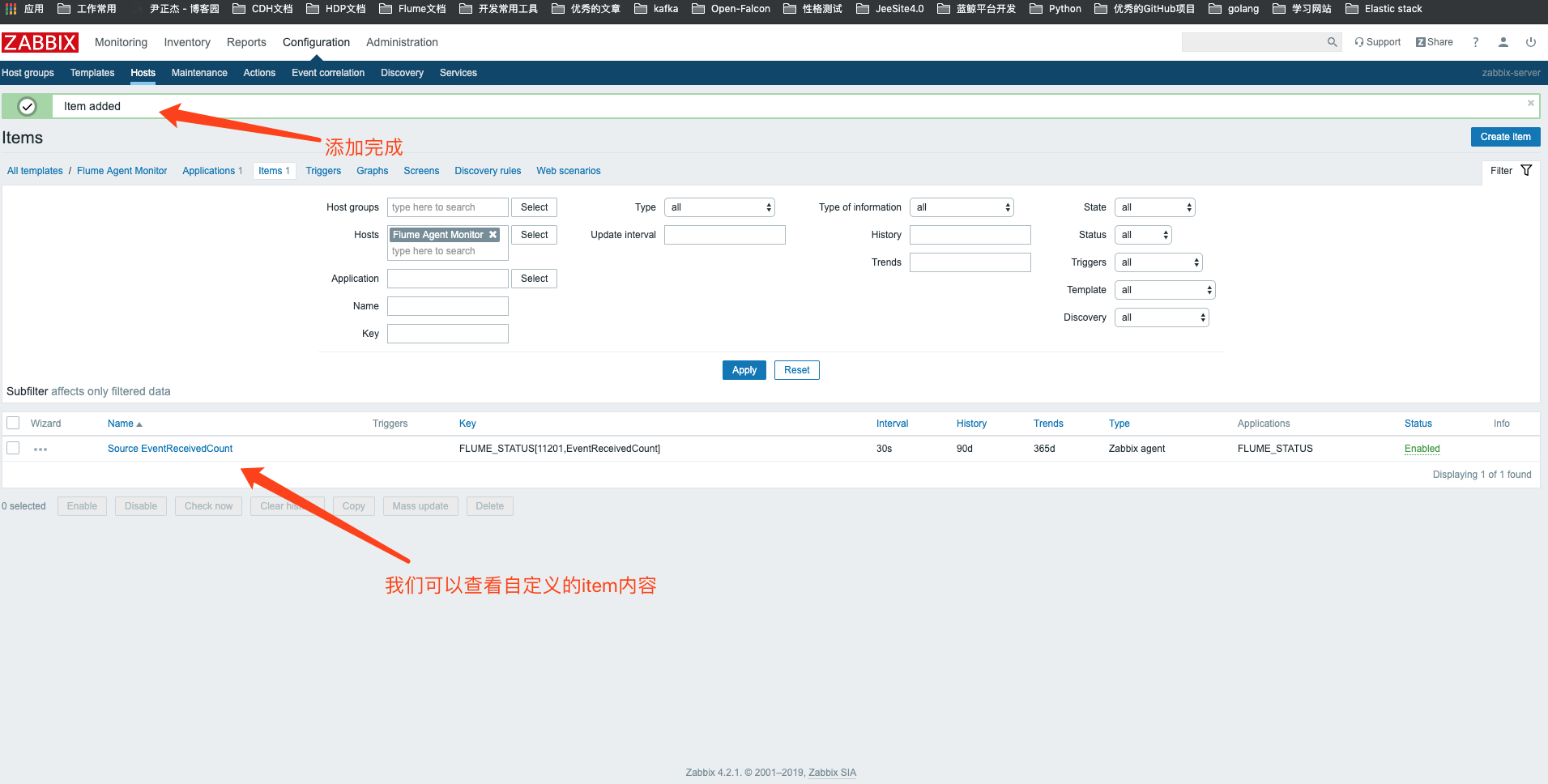
7>.查看item的内容,clone新的item,重复上面的操作,直到把我们需要监控的item添加完成
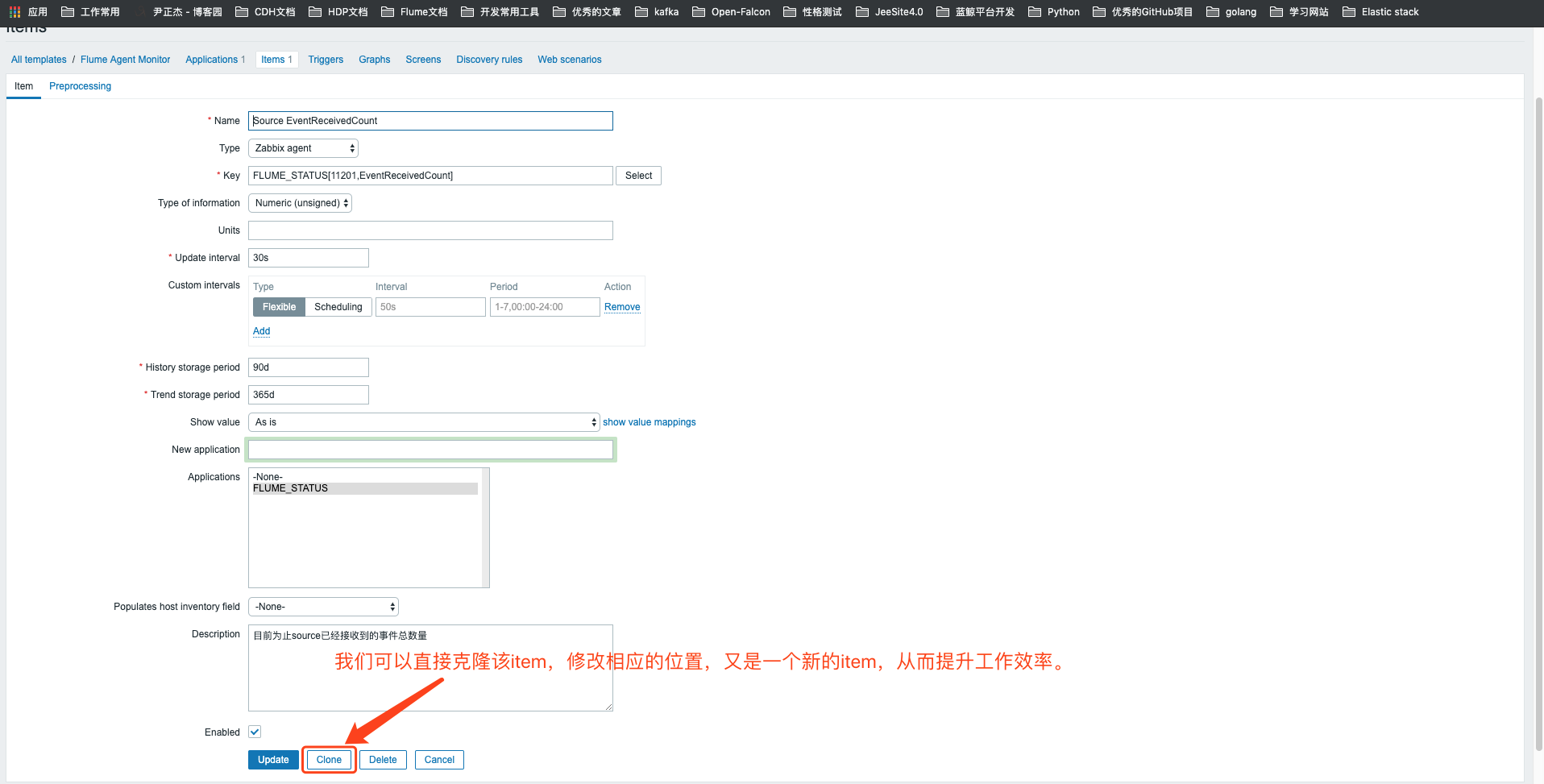
8>.模板关键参数监控创建完毕
9>.点击创建主机
10>.添加主机信息
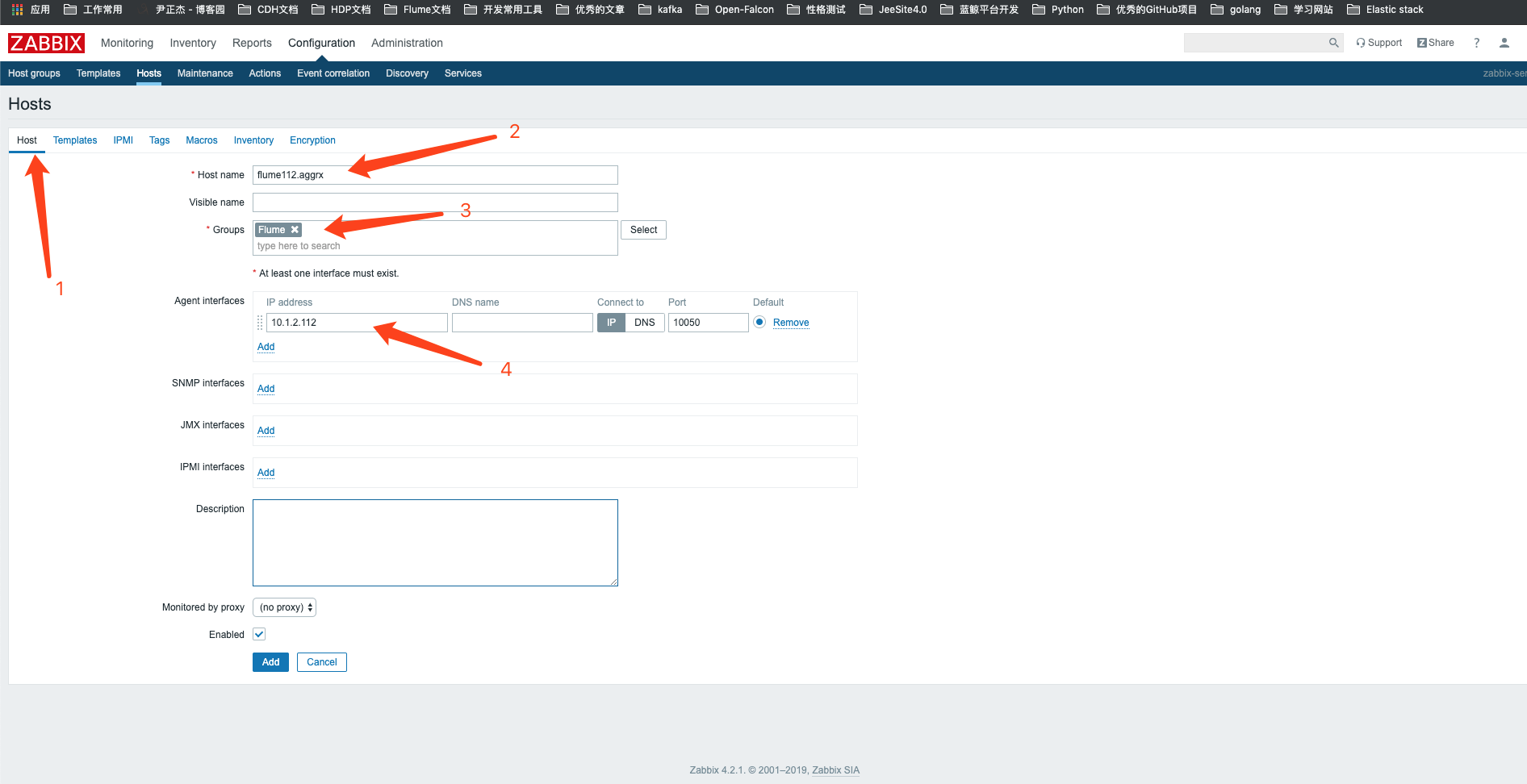
11>.为主机绑定模板,并点击添加按钮

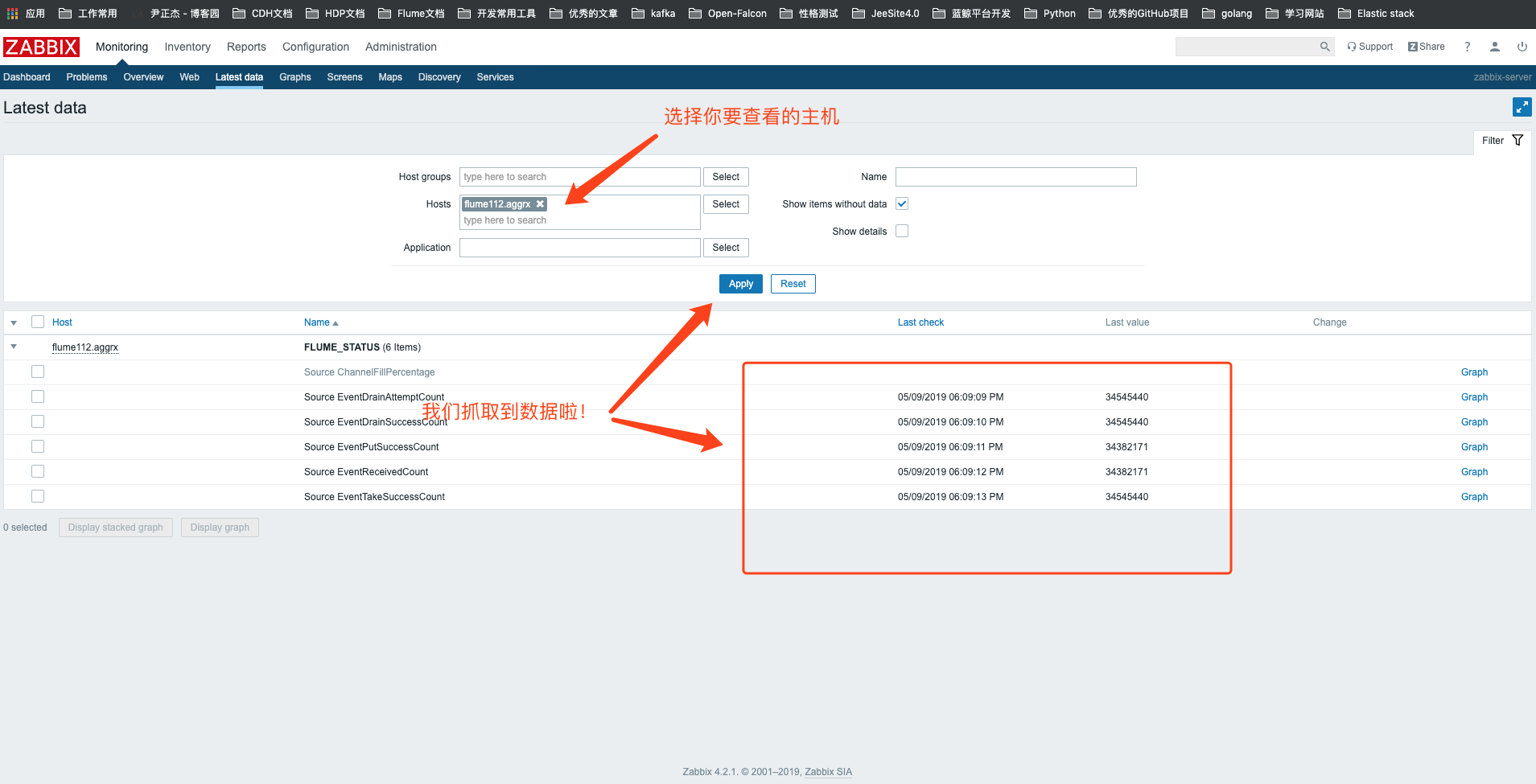
12>.查看该主机的最新数据信息,可以点击旁边的Graph
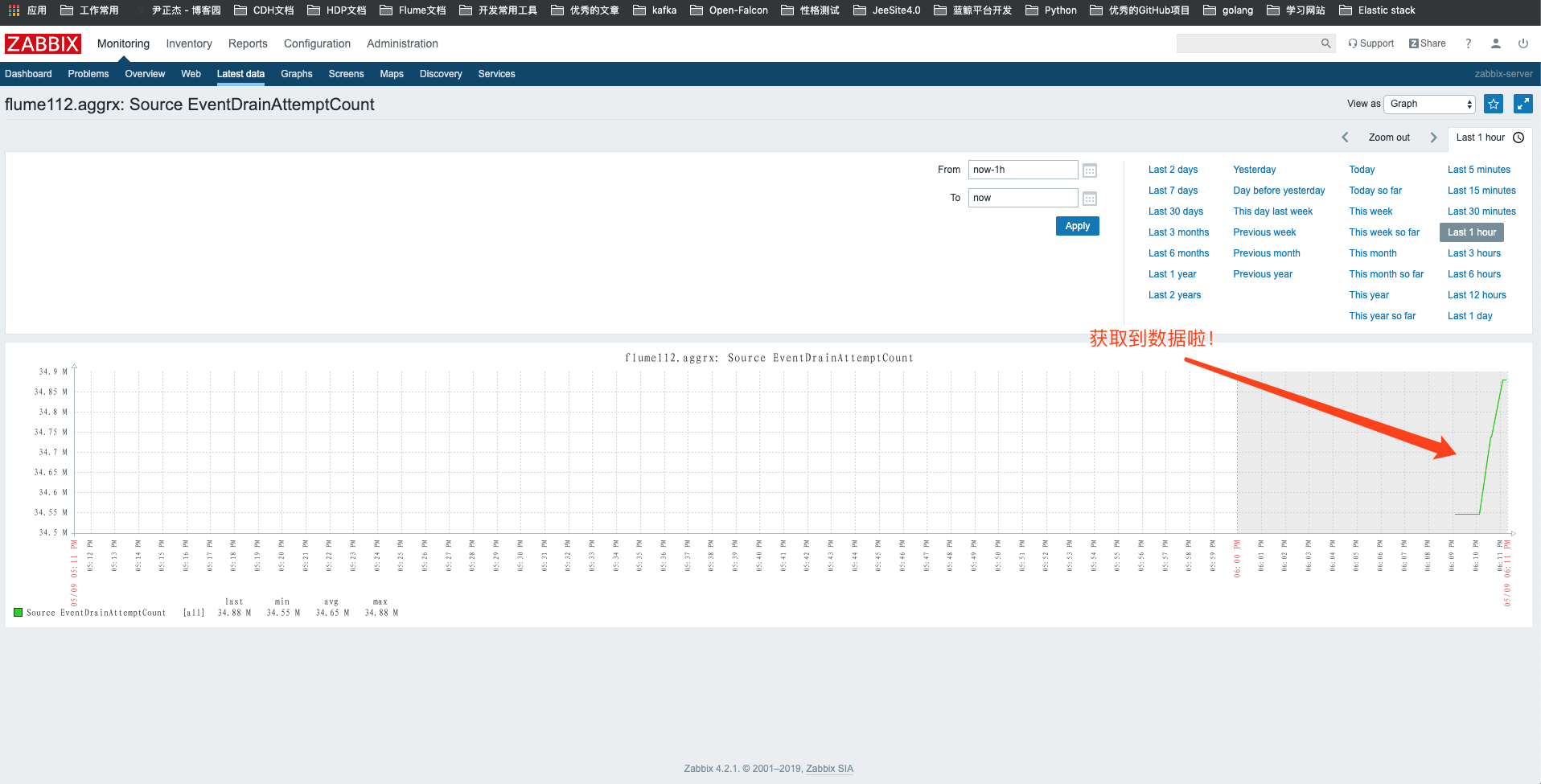
13>.查看监控图
zabbix Server 4.0监控Flume关键参数的更多相关文章
- zabbix Server 4.0 监控TCP的12种状态
zabbix Server 4.0 监控TCP的12种状态 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大家对TCP三次握手比较熟悉了,都知道当发生DOSS攻击时,客户端发送 ...
- zabbix Server 4.0 监控JMX监控详解
zabbix Server 4.0 监控JMX监控详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大家都知道,zabbix server效率高是使用C语言编写的,有很多应用 ...
- 运维监控-基于yum的方式部署Zabbix Server 4.0 版本
运维监控-基于yum的方式部署Zabbix Server 4.0 版本 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.如何选择zabbix版本 1>.打开zabbix官方 ...
- zabbix Server 4.0 部署及之内置item使用案例
zabbix Server 4.0 部署及之内置item使用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.zabbix组件架构概述(图片摘自网络) 1>.zabbi ...
- Centos 7.0 下安装 Zabbix server 3.0服务器的安装及 监控主机的加入(1)
一.本系列分为6部分 1.Centos 7.0 下安装 Zabbix server 3.0服务器的安装及 监控主机的加入 2.Centos 6.5 下安装 Zabbix server 3.0服务器的安 ...
- zabbix Server 4.0 触发器(Trigger)篇
zabbix Server 4.0 触发器(Trigger)篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.触发器(Trigger)概述 1>.上一篇博客我们介绍了“内 ...
- Centos 6.5_64bit 下安装 Zabbix server 3.0监控主机的加入
安装Zabbix server 3.0客户端之前需要先关闭selinux和打开10050和10051端口 关闭selinux 1 vi /etc/selinux/config 2 ...
- zabbix Server 4.0 报警(Action)篇
zabbix Server 4.0 报警(Action)篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看zabbix默认的Actions 1>.点击默认的Actio ...
- 007-zabbix Server 4.0 监控TCP的12种状态
大家对TCP三次握手比较熟悉了,都知道当发生DOSS攻击时,客户端发送SYN给服务端后,服务端响应SYN+ACK,此时客户端就不回应服务端ACK啦(如果正常建立三次握手客户端会回应ACK,表示三次握手 ...
随机推荐
- 【翻译】Flink Table Api & SQL —— 概念与通用API
本文翻译自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/common.html Flink Tabl ...
- [LeetCode] 407. Trapping Rain Water II 收集雨水 II
Given an m x n matrix of positive integers representing the height of each unit cell in a 2D elevati ...
- rabbitmq设置消息优先级、队列优先级配置
1.首先在consume之前声明队列的时候,要加上x-max-priority属性,一般为0-255,大于255出错 -----配置队列优先级 配置成功后rabbitmq显示: 2.在向exchan ...
- Python 内置函数--super()
描述 super() 函数是用于调用父类(超类)的一个方法. super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO).重复 ...
- 【转】Axure RP9.0.0.3661Team Edition激活码
被授权人:Axure 授权密码:ydiJnG8quHEhHLu/MWonjkeul5LYB1+tX9fyPVnpdmU0cb/NJzVs45uD7z5Iswmi 转载于:http://menvscod ...
- USACO19DEC题解
Bronze A Cow Gymnastics 题目:https://www.luogu.com.cn/problem/P5831 题解:用数组存一下出现位置,O(n^2)枚举一下就好. 代码: #i ...
- KAFA 监测| Kafka监测的方法和工具
1.目标 在我们上一篇Kafka教程中,我们讨论了Kafka Tools.今天,我们将看到Kafka Monitoring.在此,我们将学习如何监控Apache Kafka的概念.此外,我们将涵盖在故 ...
- Java开发笔记(一百三十四)Swing的基本对话框
桌面程序在运行过程中,时常需要在主界面之上弹出小窗,把某种消息告知用户,以便用户及时知晓并对症处理.这类小窗口通常称作对话框,依据消息交互的过程,可将对话框分为三类:消息对话框.确认对话框.输入对话框 ...
- PB对象Event ID说明
原地址:https://www.cnblogs.com/nickflyrong/p/5973795.html Event ID 含义 内容浅析 event可以用pb自带的id,自动触发事件,而func ...
- Js学习01--基础知识
一. JavaScript有三种书写格式 1.行内式 <button onclick = 'alert('nice day!');'>Nice Day</button> 2. ...