数据结构与算法之PHP查找算法(顺序查找)
对于查找数据来说,最简单的方法就是从列表的第一个元素开始对列表元素逐个进行判断,直到找到了想要的结果,或者直到列表结尾也没有找到,这种方法称为顺序查找。
// 顺序查找
function sequenceSearch($arr, $search) {
for ($i = 0; $i < count($arr); $i++) {
if ($arr[$i] == $search) {
return $i; // 如果在数组中找到了参数search,返回该值的下标。
}
}
return -1; // 如果没有找到要查找的数据,则返回-1。
} // 测试
$arr = array(1, 2, 4, 11, 25, 39, 78);
$res1 = sequenceSearch($arr, 333);
echo $res1; // -1
$res2 = sequenceSearch($arr, 11);
echo $res2; //
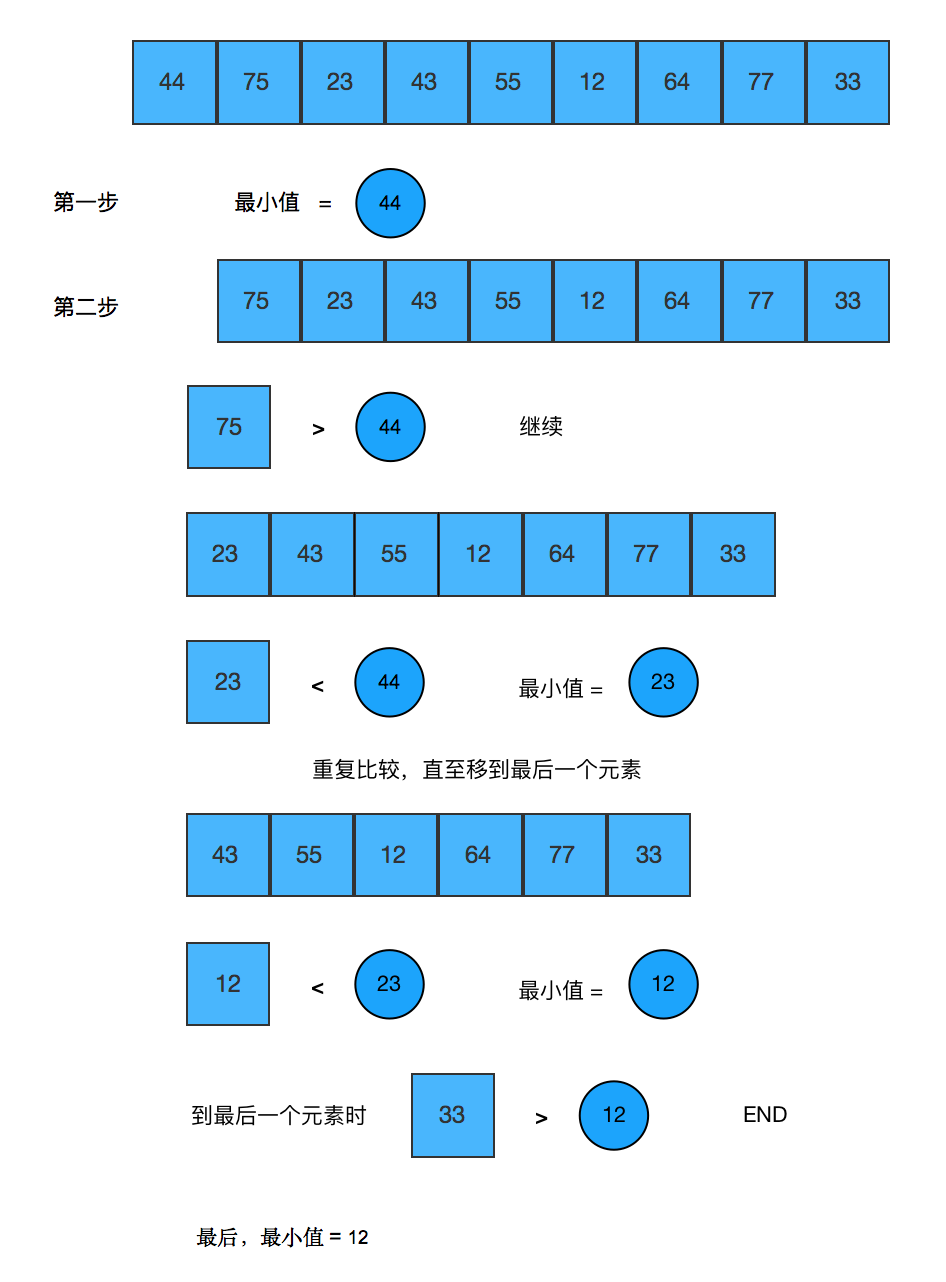
function findMin($arr) {
$min = $arr[0];
for ($i = 1; $i < count($arr); $i++) {
if ($arr[$i] < $min) {
$min = $arr[$i];
}
}
return $min;
}
function findMax($arr) {
$max = $arr[0];
for ($i = 1; $i < count($arr); $i++) {
if ($arr[$i] > $max) {
$max = $arr[$i];
}
}
return $max;
}
对于未排序的数组来说,当被查找的数据位于数组的起始位置时,查找是最快、最成功的。通过将成功找到的元素置于数据集的起始位置,可以保证在以后的操作中该元素能被更快地查找到。该策略背后的理论是:通过将频繁查找到的元素置于数组的起始位置来最小化查找次数。比如,一个元素经常被访问,可以把这个元素放在数组的最前面,经过多次查找后,查找最频繁的元素会从原来的位置移动到数组的起始位置。这就是数据的自组织——数据的位置并非由程序员在程序执行之前组织好的,而是在程序运行过程中由程序自动组织的。
// 包含自组织方式的 seqSearch() 函数
function seqSearch(&$arr, $data) {
for ($i = 0; $i < count($arr); $i++) {
if ($arr[$i] == $data) {
if ($i > 0) {
swap($arr, $i, $i - 1);
}
return true;
}
}
return false;
} function swap(&$arr, $a, $b) {
$temp = $arr[$a];
$arr[$a] = $arr[$b];
$arr[$b] = $temp;
return $arr;
} // 观察 66 被连续查找 3 次之后是如何冒泡到列表前面去的
$arr = array(1, 78, 4, 66, 25, 39, 3);
for ($i = 1; $i <= 3; $i++) {
seqSearch($arr, 66);
print_r($arr);
echo '<br>';
}
// 输出结果如下:
// 1, 78, 66, 4, 25, 39, 3
// 1, 66, 78, 4, 25, 39, 3
// 66, 1, 78, 4, 25, 39, 3
这种技巧可以保证已经在数组前面的元素不会被越移越远。
function seqSearch(&$arr, $data) {
$len = count($arr);
for ($i = 0; $i < $len; $i++) {
if ($arr[$i] == $data && $i > $len * 0.2) {
swap($arr, $i, 0);
return true;
} elseif ($arr[$i] == $data) {
return true;
}
}
return false;
}
function swap(&$arr, $a, $b) {
$temp = $arr[$a];
$arr[$a] = $arr[$b];
$arr[$b] = $temp;
return $arr;
}
// test
$arr = [4, 5, 1, 8, 10, 1, 3, 0, 1];
$res = seqSearch($arr, 3);
var_dump($res);
print_r($arr);
// 输出结果如下:
// true
// 3, 5, 1, 8, 10, 1, 4, 0, 1
如果要查找的目标数据位置在数组中很靠前,比如查找5,则可以观察到数组没有发生变化,这是因为被查找的元素很接近数组的起始位置,函数没有改变它的位置。
数据结构与算法之PHP查找算法(顺序查找)的更多相关文章
- 各种查找算法的选用分析(顺序查找、二分查找、二叉平衡树、B树、红黑树、B+树)
目录 顺序查找 二分查找 二叉平衡树 B树 红黑树 B+树 参考文档 顺序查找 给你一组数,最自然的效率最低的查找算法是顺序查找--从头到尾挨个挨个遍历查找,它的时间复杂度为O(n). 二分查找 而另 ...
- PHP算法之二分查找和顺序查找
一.二分查找 (数组里查找某个元素) /** * 二分查找 (数组里查找某个元素) * $k为要查找的关键字(注:待查找的数组元素为奇数个)$low为查找范围的最小键值,$high为查找范围的最大键值 ...
- 查找->静态查找表->顺序查找(顺序表)
文字描述 顺序查找的查找过程为:从表中最后一个记录开始,逐个进行记录的关键字和给定值的比较,若某个记录的关键字和给定值比较相等,则查找成功,找到所查记录:反之,若直至第一个记录,其关键字和给定值比较都 ...
- javascript数据结构与算法---检索算法(顺序查找、最大最小值、自组织查询)
javascript数据结构与算法---检索算法(顺序查找.最大最小值.自组织查询) 一.顺序查找法 /* * 顺序查找法 * * 顺序查找法只要从列表的第一个元素开始循环,然后逐个与要查找的数据进行 ...
- 数据结构Java版之查找算法(三)
关于查找算法,这里只进行两个算法的说明.包括 顺序查找 和 折半查找. 顺序查找: 顺序查找常用于未排序的数据中.查找速度较慢,只能应用于较小的数据量. public int sequentialSe ...
- [Data Structure & Algorithm] 七大查找算法
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找.本文简单概括性的介绍了常见的七种查找算法,说是七种,其实二分查找.插值查找以及斐波那契查找 ...
- 七大查找算法(附C语言代码实现)
来自:Poll的笔记 - 博客园 链接:http://www.cnblogs.com/maybe2030/p/4715035.html 阅读目录 1.顺序查找 2.二分查找 3.插值查找 4.斐波那契 ...
- 七大查找算法(Python)
查找算法 -- 简介 查找(Searching)就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素. 查找表(Search Table):由同一类型的数据元素构成的集合 ...
- 查找算法(5)--Tree table lookup--树表查找
1.树表查找 (1) 最简单的树表查找算法——二叉树查找算法. [1]基本思想:二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后在就行和每个节点的父节点比较大小,查找最适 ...
- JS-七大查找算法
顺序查找 二分查找 插值查找 斐波那契查找 树表查找 分块查找 哈希查找 查找定义:根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录).查找算法分类:1)静态查找和动态查找:注 ...
随机推荐
- 17秋 SDN课程 第二次上机作业
1.控制器floodlight所示可视化图形拓扑的截图,及主机拓扑连通性检测截图 拓扑 连通性 2.利用字符界面下发流表,使得'h1'和'h2' ping 不通 流表截图 连通性 3.利用字符界面下发 ...
- C++中set的用法
set的特性是,所有元素都会根据元素的键值自动排序,set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值.set不允许两个元素有相同的键值. ...
- Java 数据库篇
一.简易封装JDBC工具类: package com.jackie.MyBatis.main; import java.sql.Connection; import java.sql.DriverMa ...
- 前端调用后端接口下载excel文件的几种方式
今天有一个导出相应数据为excel表的需求.后端的接口返回一个数据流,一开始我用axios(ajax类库)调用接口,返回成功状态200,但是!但是浏览器没有自动下载excel表,当时觉得可能是ajax ...
- BZOJ 4826 【HNOI2017】 影魔
题目链接:影魔 这道题就是去年序列的弱化版啊…… 我们枚举最大值的位置\(i\),找出左边第一个比\(a_i\)大的位置\(l\),右边第一个比\(a_i\)大的位置\(r\),然后我们分开考虑一下\ ...
- sqlserver 中通配符%和_的使用
--以a开头的数据 SELECT * FROM BCUSTOMER_MZN WHERE CST_NAME LIKE 'A%' --以Z结尾的数据 SELECT * FROM BCUSTOMER_MZN ...
- Abode Audition 的使用
讲一下音频的合并,音量放大,音频截取,音频删除等. 我下载的是Abode Audition 3.0的试用版本,可以免费使用30天. 1. 将抖音中小视频保存下来,成为mp4文件,然而Audition ...
- Token和SessionStorage(会话存储对象)
sessionStorage数据只在当前标签页共享 存在本地 关闭浏览器后会清除数据(关闭标签页不会清楚) localStorage数据会存在浏览器中 浏览器关了数据也还在 只有清除缓存才会消失 ...
- 大话WebRTC的前世今生
音视频的历史 音视频可以说是人类与生俱来的需求,人一出生就要用耳朵听,用眼睛看.中国的古代神话中为此还专门设置了两位神仙(千里眼和顺风耳),他们可以听到或看到千里之外的声音或景像. 为了解决听的远和看 ...
- 如何选择合适的 DDoS 防御服务
如果你没有对自己的站点采取一些必要的保护措施,将会使它直接暴露于 DDoS 攻击的风险下且无任何招架之力.你应该对法国大选日 knocked out 网站被 DDoS 攻击和 2016 年十月份时候美 ...