关于Zookeeper选举机制
一.Zookeeper集群
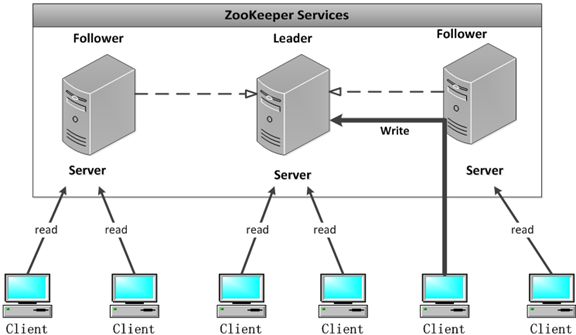
配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,
每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。
这篇主要分析leader的选择机制,zookeeper提供了三种方式:
(1)LeaderElection;
(2)AuthFastLeaderElection;
(3)FastLeaderElection;
默认的算法是FastLeaderElection,下面分析它的选举机制。
二.选择机制中的概念
1、服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
2、数据ID
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
3、逻辑时钟
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
4、选举状态
(1)LOOKING,竞选状态。
(2)FOLLOWING,随从状态,同步leader状态,参与投票。
(3)OBSERVING,观察状态,同步leader状态,不参与投票。
(4)LEADING,领导者状态。
5、选举消息内容
在投票完成后,需要将投票信息发送给集群中的所有服务器,它包含如下内容。
(1)服务器ID;
(2)数据ID;
(3)逻辑时钟;
(4)选举状态。
6、选举流程图
因为每个服务器都是独立的,在启动时均从初始状态开始参与选举,下面是简易流程图。

7、选举状态图
描述Leader选择过程中的状态变化,这是假设全部实例中均没有数据,假设服务器启动顺序分别为:A,B,C。

8、源码分析
QuorumPeer
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止。
public void run() {
//.......
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}
FastLeaderElection
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException {
//...
try {
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized(this){
//给自己投票
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//将投票信息发送给集群中的每个服务器
sendNotifications();
//循环,如果是竞选状态一直到选举出结果
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
//没有收到投票信息
if(n == null){
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
//...
}
//收到投票信息
else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) {
switch (n.state) {
case LOOKING:
// 判断投票是否过时,如果过时就清除之前已经接收到的信息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
//更新投票信息
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//发送投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid, proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
//忽略
break;
case FOLLOWING:
case LEADING:
//如果是同一轮投票
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if(termPredicate(recvset, new Vote(n.leader,
n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
//记录投票已经完成
outofelection.put(n.sid, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
if (termPredicate(outofelection, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, IGNOREVALUE)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
//忽略
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
} finally {
//...
}
}
判断是否已经胜出
默认是采用投票数大于半数则胜出的逻辑。
9、选举流程简述
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
(1)服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
(2)服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
(3)服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
(4)服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
(5)服务器5启动,后面的逻辑同服务器4成为小弟。
关于Zookeeper选举机制的更多相关文章
- 学习笔记:Zookeeper选举机制
1.Zookeeper选举机制 Zookeeper虽然在配置文件中并没有指定master和slave 但是,zookeeper工作时,是有一个节点为leader,其他则为follower Leader ...
- Zookeeper选举机制(转)
源:http://blog.csdn.net/tototuzuoquan/article/details/54426684 1.Zookeeper选举机制 Zookeeper虽然在配置文件中并没有指定 ...
- 理解zookeeper选举机制
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- 【转】Zookeeper学习---zookeeper 选举机制介绍
[原文]https://www.toutiao.com/i6593162565872779784/ zookeeper集群 配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的 ...
- zookeeper选举机制
在上一篇文章中我们大致浏览了zookeeper的启动过程,并且提到在Zookeeper的启动过程中leader选举是非常重要而且最复杂的一个环节.那么什么是leader选举呢?zookeeper为什么 ...
- zookeeper 选举机制 和 eruake
zookeeper简介: 在分布式环境中,多个服务之间协调一致.有提供分布式锁.服务配置.实现分布式领域CAP(consistency一致性,Availiablity高可用,patition tolr ...
- 8.8.ZooKeeper 原理和选举机制
1.ZooKeeper原理 Zookeeper虽然在配置文件中并没有指定master和slave但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通 ...
- Zookeeper的概述、安装部署及选举机制
一.Zookeeper概述 1.Zookeeper是Hadoop生态的管理者,它致力于开发和维护开源服务器,实现高度可靠的分布式协调. 2.Zookeeper的两大功能: (1)存储数据 (2)监听 ...
- zookeeper leader选举机制
最近看了下zookeeper的源码,先整理下leader选举机制 先看几个关键数据结构和函数 服务可能处于的状态,从名字应该很好理解 public enum ServerState { LOOKING ...
随机推荐
- MySQL中的存储过程和函数使用详解
一.对待存储过程和函数的态度 在实际项目中应该尽量少用存储过程和函数,理由如下: 1.移植性差,在MySQL中的存储过程移植到sqlsever上就不一定可以用了. 2.调试麻烦,在db中报一个错误和在 ...
- SQLI DUMB SERIES-1
less-1 (1) 可以看到提示输入ID,而且less-1题目也有提到GET,因此试试以下操作: http: 结果: http: 结果: 现在可知,“ ' ”并没有被过滤,因此可以进行以下操作: h ...
- rcnn系列
提纲挈领 https://blog.csdn.net/linolzhang/article/details/54344350 SPP https://www.cnblogs.com/gongxijun ...
- 错题:Test3
/** * * @ClassName: test3 * @Description: TODO(请问主程序运行结果是什么?) * @author yk * @date 2017年3月9日 上午11:20 ...
- 栈与队列(Stack and Queue)
1.定义 栈:后进先出(LIFO-last in first out):最后插入的元素最先出来. 队列:先进先出(FIFO-first in first out):最先插入的元素最先出来. 2.用数组 ...
- https://blog.csdn.net/qq_35447305/article/details/78587691
来源:https://blog.csdn.net/qq_35447305/article/details/78587691 需要去查看设置.C:\Users\用户名 目录下找到 .npmrc文件,删除 ...
- LeetCode - Merge Two Binary Trees
Given two binary trees and imagine that when you put one of them to cover the other, some nodes of t ...
- Spring boot Mybatis 整合
PS: 参考博客 PS: spring boot配置mybatis和事务管理 PS: Spring boot Mybatis 整合(完整版) 这篇博客里用到了怎样 生成 mybatis 插件来写程 ...
- css3新增内容
1.css3边框 border-radius box-shadow border-image 2.背景 background-size background-origin 3.文本效果 text-sh ...
- CSS如何实现”右部宽度固定,左部自适应“的布局
吃过晚饭后,开始刷前端笔试题,却遇到了一道CSS难题——使用CSS实现左部自适应.右部固定宽度为200px的布局.当时第一眼看到题目时,以为只是一道很简单的题目.不就是定义两个左浮动的div,右部的宽 ...