day18-19 Storm
课程介绍
课程名称:Storm是什么
课程目标:
通过该课程的学习能够了解离线计算与流式计算的区别、掌握Storm框架的基础知识、了解流式计算的一般架构图。
课程大纲:
1、 离线计算是什么?
2、 流式计算是什么?
3、 流式计算与离线计算的区别?
4、 Storm是什么?
5、 Storm与Hadoop的区别?
6、 Storm的应用场景及行业案例
7、 Storm的核心组件(重点掌握)
8、 Storm的编程模型(重点掌握)
9、 流式计算的一般架构图(重点掌握)
背景介绍
Storm背景介绍
课程内容
1、离线计算是什么?
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、***任务调度
1,hivesql
2、调度平台
3、Hadoop集群运维
4、数据清洗(脚本语言)
5、元数据管理
6、数据稽查
7、数据仓库模型架构
2、流式计算是什么
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果
3、离线计算与实时计算的区别
最大的区别:实时收集、实时计算、实时展示
4、Storm是什么?

Flume实时采集,低延迟
Kafka消息队列,低延迟
Storm实时计算,低延迟
Redis实时存储,低延迟
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
海量数据?数据类型很多,产生数据的终端很多,处理数据能力增强
5、Storm与Hadoop的区别
l Storm用于实时计算,Hadoop用于离线计算。
l Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。
l Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
l Storm与Hadoop的编程模型相似
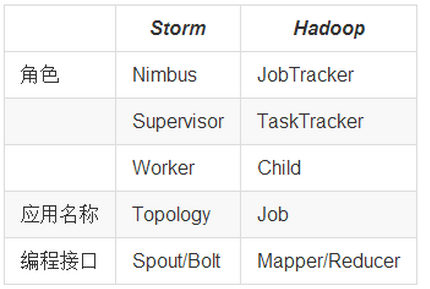
Job:任务名称
JobTracker:项目经理
TaskTracker:开发组长、产品经理
Child:负责开发的人员
Mapper/Reduce:开发人员中的两种角色,一种是服务器开发、一种是客户端开发
Topology:任务名称
Nimbus:项目经理
Supervisor:开组长、产品经理
Worker:开人员
Spout/Bolt:开人员中的两种角色,一种是服务器开发、一种是客户端开发
6、Storm应用场景及行业案例
Storm用来实时计算源源不断产生的数据,如同流水线生产。
6.1、运用场景
l 日志分析
从海量日志中分析出特定的数据,并将分析的结果存入外部存储器用来辅佐决策。
l 管道系统
将一个数据从一个系统传输到另外一个系统,比如将数据库同步到Hadoop
l 消息转化器
将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
6.2、典型案列
l 一淘-实时分析系统:实时分析用户的属性,并反馈给搜索引擎
最初,用户属性分析是通过每天在云梯上定时运行的MR job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
l 携程-网站性能监控:实时分析系统监控携程网的网站性能
利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。
l 阿里妈妈-用户画像:实时计算用户的兴趣数据
为了更加精准投放广告,阿里妈妈后台计算引擎需要维护每个用户的兴趣点(理想状态是,你对什么感兴趣,就向你投放哪类广告)。用户兴趣主要基于用户的历史行为、用户的实时查询、用户的实时点击、用户的地理信息而得,其中实时查询、实时点击等用户行为都是实时数据。考虑到系统的实时性,阿里妈妈使用Storm维护用户兴趣数据,并在此基础上进行受众定向的广告投放。
7、Storm核心组件(重要)
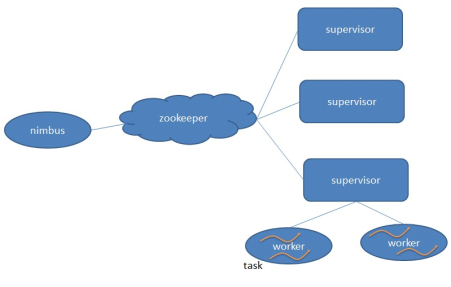
l Nimbus:负责资源分配和任务调度。
l Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。
l Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
l Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
8、Storm编程模型(重要)
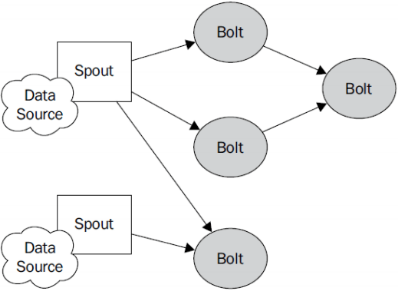

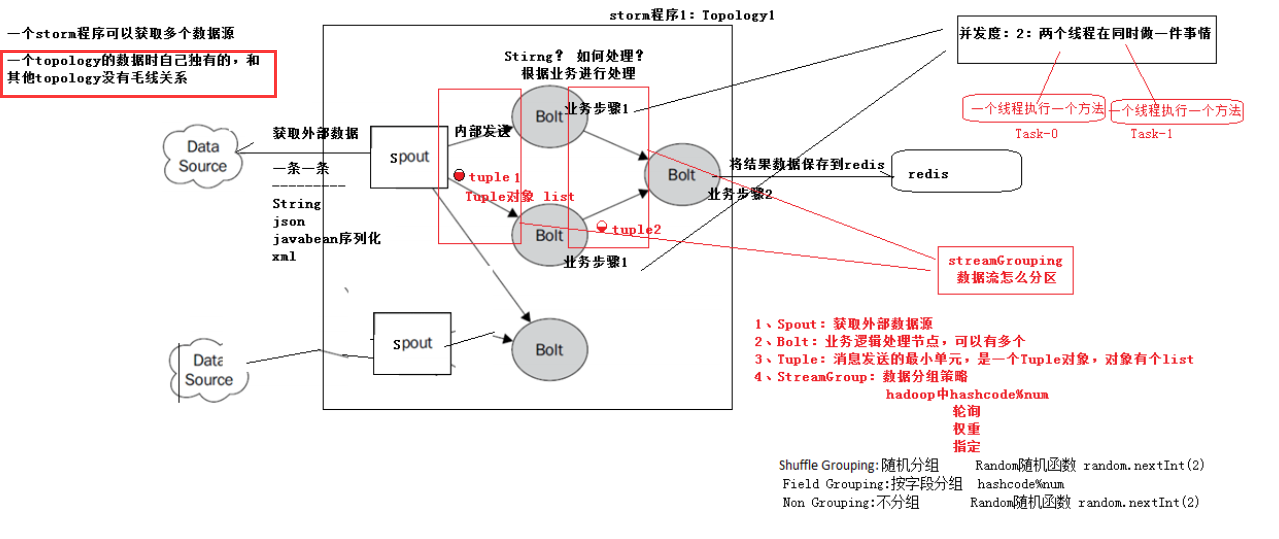
1、编程模型
DataSource:外部数据源
Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt
Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是Redis可以是mysql,或者其他。
Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
StreamGrouping:数据分组策略 (也就是为什么从这个bolt到下个bolt,为什么这么走,是可以设置的)
7种:shuffleGrouping(Random函数),Non Grouping(Random函数),FieldGrouping(Hash取模)、Local or ShuffleGrouping 本地或随机,优先本地。 2、并发度
用户指定的一个任务,可以被多个线程执行,并发度的数量等于线程的数量。一个任务的多个线程,会被运行在多个Worker(JVM)上,有一种类似于平均算法的负载均衡策略。
尽可能减少网络IO,和Hadoop中的MapReduce中的本地计算的道理一样。 3、架构
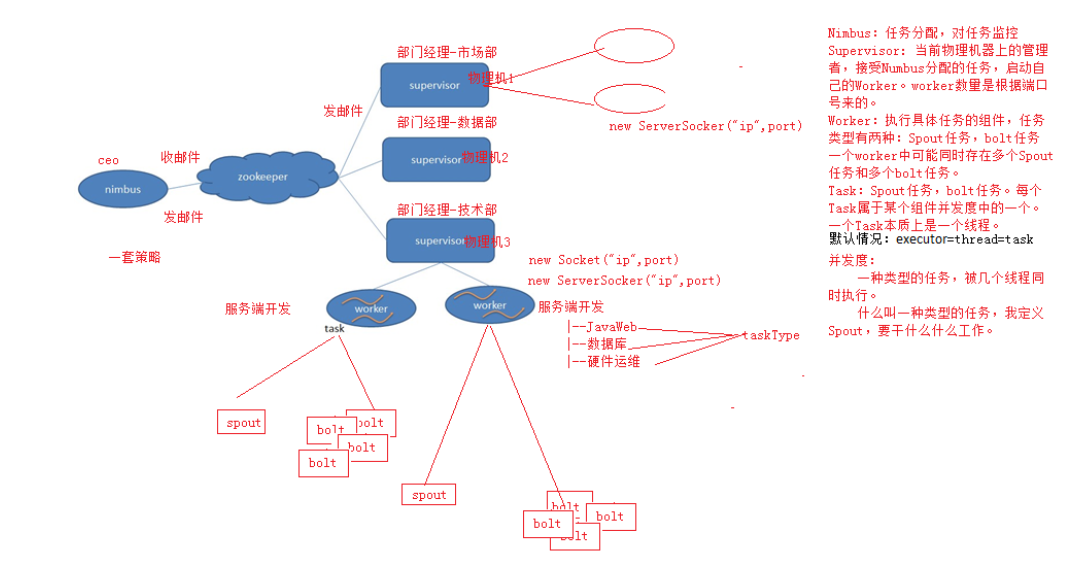
Nimbus:任务分配
Supervisor:接受任务,并启动worker。worker的数量根据端口号来的。
Worker:执行任务的具体组件(其实就是一个JVM),可以执行两种类型的任务,Spout任务或者bolt任务。
Task:Task=线程=executor。 一个Task属于一个Spout或者Bolt并发任务。
Zookeeper:保存任务分配的信息、心跳信息、元数据信息。 4、Worker与topology
一个worker只属于一个topology,每个worker中运行的task只能属于这个topology。 反之,一个topology包含多个worker,其实就是这个topology运行在多个worker上。
一个topology要求的worker数量如果不被满足,集群在任务分配时,根据现有的worker先运行topology。如果当前集群中worker数量为0,那么最新提交的topology将只会被标识active,不会运行,只有当集群有了空闲资源之后,才会被运行。
9、流式计算一般架构图(重要)
PS:前三个是用来相当于数据源。
其中flume用来获取数据。
l Kafka用来临时保存数据。
l Strom用来计算数据。
l Redis是个内存数据库,用来保存数据。
-----------------------------------Strom安装配置
http://blog.csdn.net/kwu_ganymede/article/details/52169861
https://www.cnblogs.com/zhaojiankai/p/7257617.html
PS:在安装配置的过程中遇到ui启动的错误,看了这个博客,执行了命令算是启动了
PS:同时又安装配置了一次zookeeper,详情看zookeeper的我的博客,也可参看第二个视频
PS:配置时,确保已经启动的了zookeeper
1、 集群部署的基本流程
集群部署的流程:下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
注意:
所有的集群上都需要配置hosts
vi /etc/hosts
192.168.239.128 storm01 zk01 hadoop01
192.168.239.129 storm02 zk02 hadoop02
192.168.239.130 storm03 zk03 hadoop03
2、 集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
l 关闭防火墙
chkconfig iptables off && setenforce 0
l 创建用户
groupadd realtime && useradd realtime && usermod -a -G realtime realtime
l 创建工作目录并赋权
mkdir /export
mkdir /export/servers
chmod 755 -R /export
l 切换到realtime用户下
su realtime
3、Storm集群部署
3.1、下载安装包
3.2、解压安装包
tar -zxvf apache-storm-0.9.5.tar.gz -C /export/servers/
cd /export/servers/
ln -s apache-storm-0.9.5 storm
3.3、修改配置文件
mv /export/servers/storm/conf/storm.yaml /export/servers/storm/conf/storm.yaml.bak
vi /export/servers/storm/conf/storm.yaml
输入以下内容:
#指定storm使用的zk集群
storm.zookeeper.servers:
- "bee1"
- "bee2"
- "bee3"
#指定storm本地状态保存地址
storm.local.dir: "/apps/storm/workdir"
#指定storm集群中的nimbus节点所在的服务器
nimbus.host: "bee1"
#指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
#指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx1024m"
#指定supervisor节点上,每个worker启动JVM最大可用内存大小
worker.childopts: "-Xmx768m"
#指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。
ui.childopts: "-Xmx768m"
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker
supervisor.slots.ports:
-
-
-
-
3.4、分发安装包
scp -r /export/servers/apache-storm-0.9.5 storm02:/export/servers
然后分别在各机器上创建软连接
cd /export/servers/
ln -s apache-storm-0.9.5 storm
3.5、启动集群
l 在nimbus.host所属的机器上启动 nimbus服务
cd /export/servers/storm/bin/
nohup ./storm nimbus &
l 在nimbus.host所属的机器上启动ui服务
cd /export/servers/storm/bin/
nohup ./storm ui &
l 在其它个点击上启动supervisor服务
cd /export/servers/storm/bin/
nohup ./storm supervisor &
3.6、查看集群
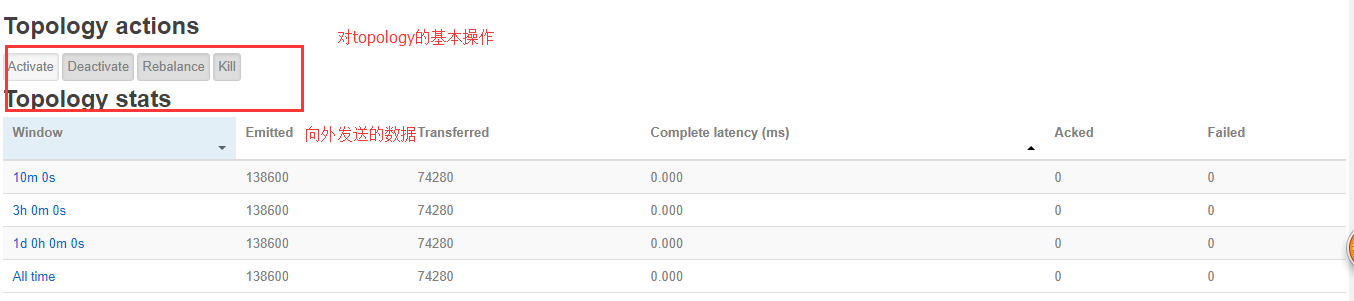
访问nimbus.host:/8080,即可看到storm的ui界面。
PS:对从机器执行storm supervisor&,我们看一下可执行机器

PS:每个集群有4个,所以有8个

PS:对从机器介绍




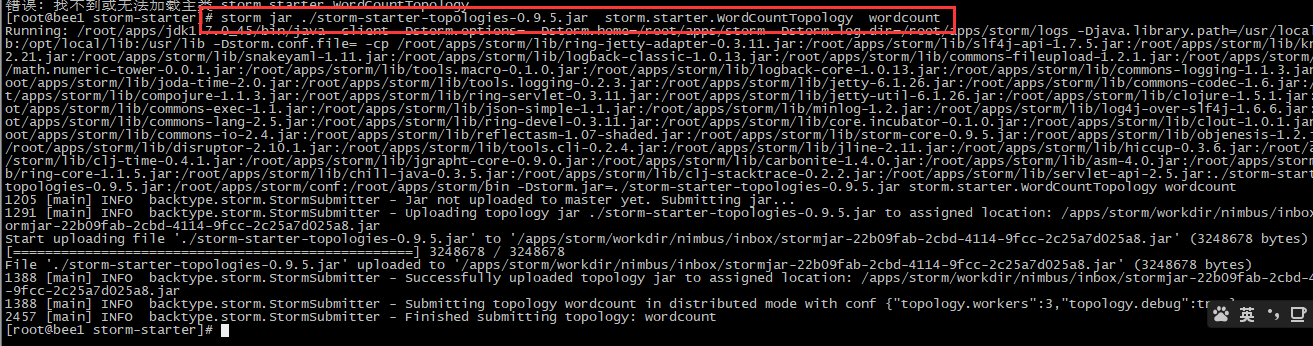
测试wordCount例子
PS:storm jar /root/apps/storm/examples/storm-starter/storm-starter-topologies-0.9.5.jar storm.starter.WordCountTopology wordcount
PS:有3个workerS,就会有3个jvm,会有3个端口号,一个对口号就是一个槽
PS:同时提交4个以后,不够的只能等待了;当有空闲的worker就会执行空闲的
、Worker与topology
一个worker只属于一个topology,每个worker中运行的task只能属于这个topology。 反之,一个topology包含多个worker,其实就是这个topology运行在多个worker上。
一个topology要求的worker数量如果不被满足,集群在任务分配时,根据现有的worker先运行topology。如果当前集群中worker
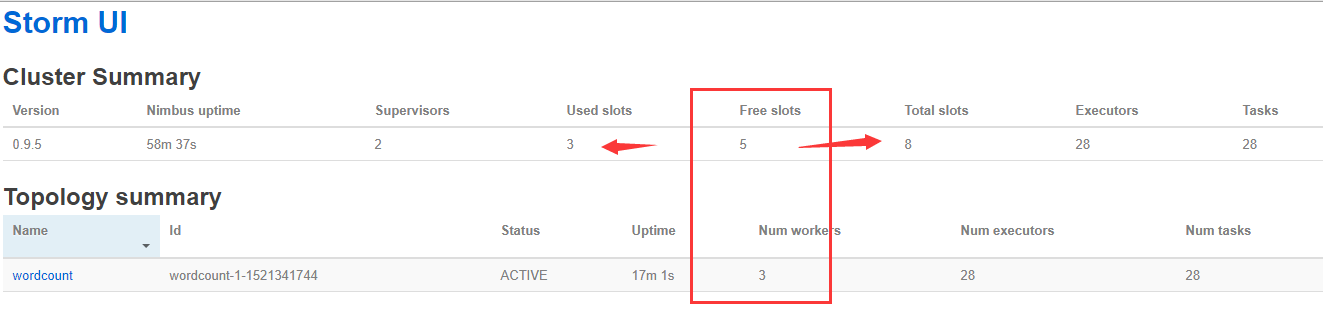


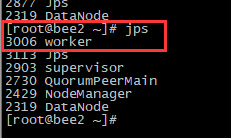
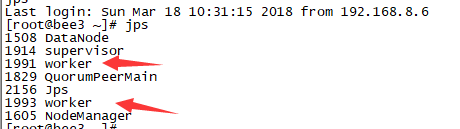
PS:提交命令以后,worker自动启动,杀死程序以后,worker就没有了
------------------------------------------
PS:从上面可以看到,我们现在的研究主要是两个
1.并发度如何配置
2.worker的数量如何配置
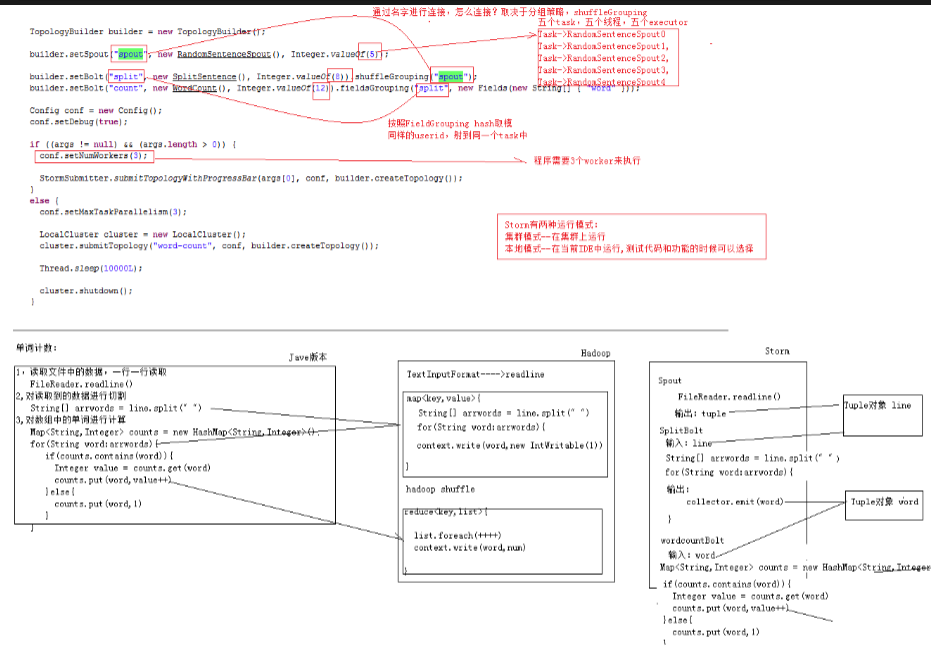
PS:我们可以从源码中看到,在代码中设置的并发读和任务的执行度,下面分别是java、hadoop、storm的执行方式
PS:当在执行maven程序的时候,要注意scope,因为上传的时候,集群中都有了,所以不用再执行了,所有要注释
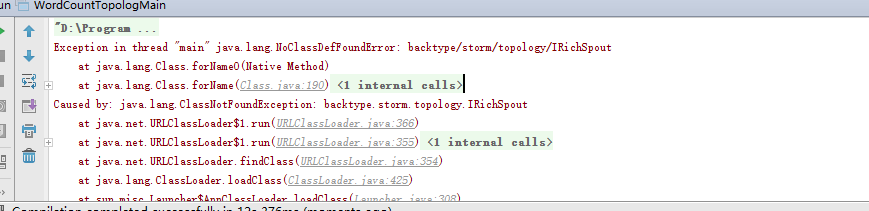
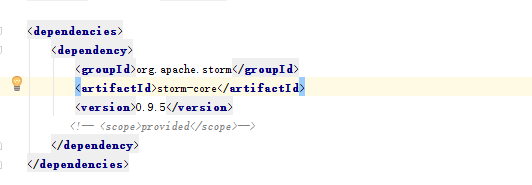
------------------------------
package cn.itcast.storm; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields; /**
* Created by bee on 2018/3/19.
*/
public class WordCountTopologMain { public static void main(String [] args) throws AlreadyAliveException, InvalidTopologyException {
//1、准备一个TopologyBuilder
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("mySpout",new MySpout(),1);//设置并发度
topologyBuilder.setBolt("mybolt1",new MySplitBolt(),10).shuffleGrouping("mySpout");
topologyBuilder.setBolt("mybolt2",new MyCountBolt(),2).fieldsGrouping("mybolt1",new Fields("word"));
//2、创建一个configuration,用来指定当前topology 需要的worker的数量
Config config = new Config();
config.setNumWorkers(2); //3、提交任务 -----两种模式 本地模式和集群模式
// StormSubmitter.submitTopology("mywordcount",config,topologyBuilder.createTopology());
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mywordcount",config,topologyBuilder.createTopology());
}
}
package cn.itcast.storm; import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values; import java.util.Map; /**
* Created by bee on 2018/3/19.
*/
public class MySpout extends BaseRichSpout {
SpoutOutputCollector collector;
/**
* 初始化方法,给nextTuple使用
* @param map
* @param topologyContext
* @param spoutOutputCollector
*/
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
//storm 框架在 while(true) 调用nextTuple方法
public void nextTuple() {
collector.emit(new Values("bi yang qiang love zhao huan huan"));//这个values继承自ArrayList
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("Love"));//我自己的声明,想叫什么叫什么
} }
package cn.itcast.storm; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; import java.util.Map; /**
* Created by bee on 2018/3/19.
*/
public class MySplitBolt extends BaseRichBolt { OutputCollector collector;
//初始化方法
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
} // 被storm框架 while(true) 循环调用 传入参数tuple;这个参数来自于spout所发射的
public void execute(Tuple input) {
String line = input.getString(0);//这里是0的原因是,因为发的是List的一个值,所有取list的第一个元素,这个是自己知道
String[] arrWords = line.split(" ");
for (String word:arrWords){
collector.emit(new Values(word,1));
}
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","num"));//声明的原因是上面发射出来两个字段
}
}
package cn.itcast.storm; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple; import java.util.HashMap;
import java.util.Map; /**
* Created by bee on 2018/3/19.
*/
public class MyCountBolt extends BaseRichBolt {
OutputCollector collector;
Map<String, Integer> map = new HashMap<String, Integer>(); public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String word = input.getString(0);//因为上面发了两处数据
Integer num = input.getInteger(1);
System.out.println(Thread.currentThread().getId() + " word:"+word);
if (map.containsKey(word)){
Integer count = map.get(word);
map.put(word,count + num);
}else {
map.put(word,num);
}
System.out.println("count:"+map);
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
//不輸出
}
}
PS:nimbus负责任务的分配,在程序中我设置了 wordcount的执行线程数,spout数量。那么就有8个task;同时设置两个worker;worker就会对上诉的task就行细分
然后在不同bolt传输的规则还不太一样,见最下面。
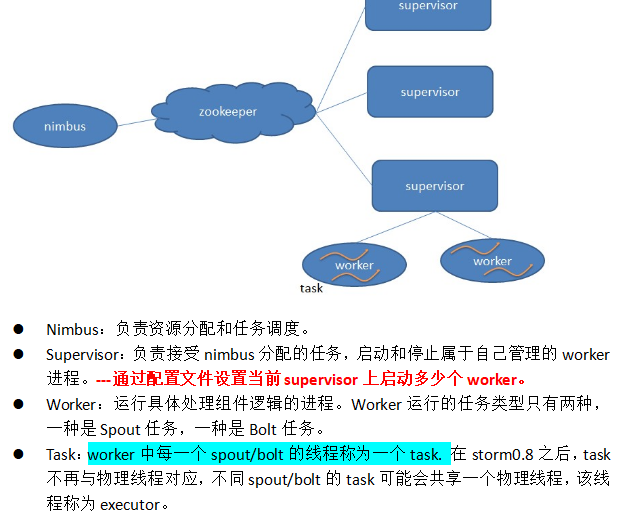
架构模型图
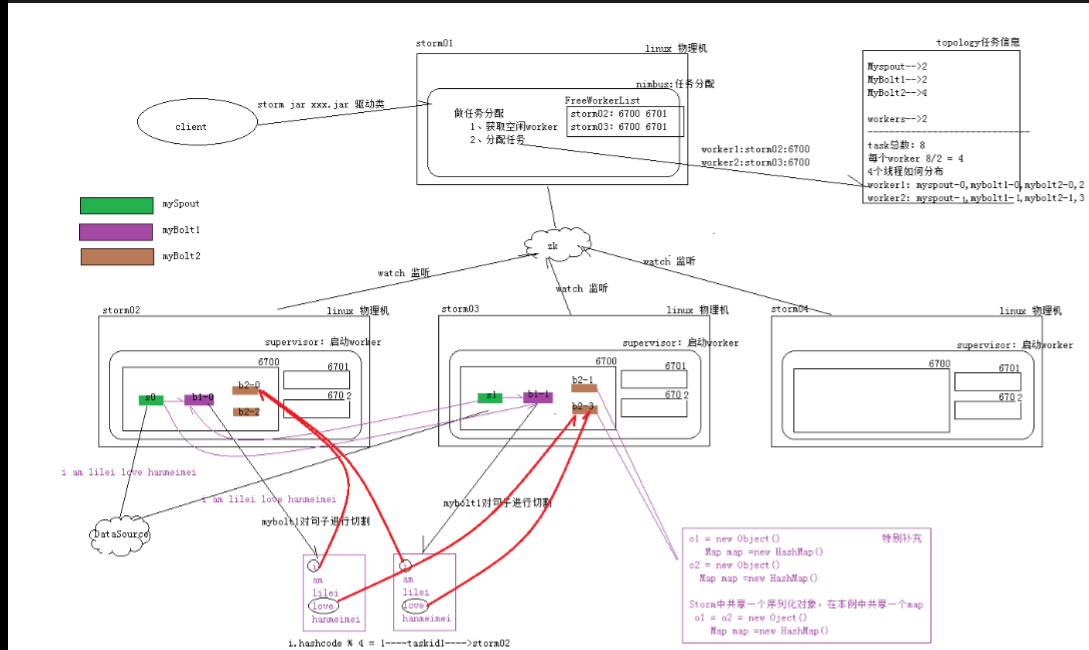

------------------------
PS:实时是今后的趋势。


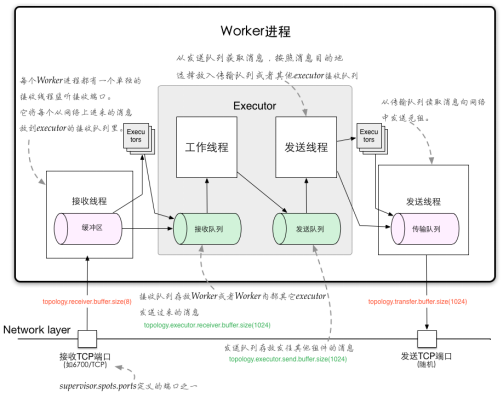
2、Storm通信机制
Worker间的通信经常需要通过网络跨节点进行,Storm使用ZeroMQ或Netty(0.9以后默认使用)作为进程间通信的消息框架。
Worker进程内部通信:不同worker的thread通信使用LMAX Disruptor来完成。
不同topologey之间的通信,Storm不负责,需要自己想办法实现,例如使用kafka等;
2.1、Worker进程间通信
worker进程间消息传递机制,消息的接收和处理的大概流程见下图
PS:详细看课件,本节听的不是太明白
day18-19 Storm的更多相关文章
- storm 机制
storm基础系列之二----zookeeper的作用 https://www.cnblogs.com/xyang/p/5643745.html Zookeeper+Storm集群搭建 https:/ ...
- 由提交storm项目jar包引发对jar的原理的探索
序:在开发storm项目时,提交项目jar包当把依赖的第三方jar包都打进去提交storm集群启动时报了发现多个同名的文件错误由此开始了一段对jar包的深刻理解之路. java.lang.Runtim ...
- [Storm] Storm与asm的恩恩怨怨
asm的引用冲突 1. Jersey & Storm 0.9.3 jersey 1.8 (which depends on asm 3.0) Storm 0.93 (which depends ...
- kafka storm hbase性能
kafka 单台机器部署 1个partition storm 单台机器部署 hbase 四台机器集群 机器配置大概是4G cpu 4G内存 从kafka 读出到storm,然后flush到hbase ...
- Learning storm book 笔记8-Log Processing With Storm
有代码的书籍看起来就是爽,看完顺便跑个demo,感觉很爽! 场景分析 主要是利用apache的访问日志来进行分析统计 如用户的IP来源,来自哪个国家或地区,用户使用的Os,浏览器等信息,以及像搜索的热 ...
- Storm命令详解
在Linux终端直接输入storm,不带任何参数信息,或者输入storm help,可以查看storm命令行客户端(Command line client)提供的帮助信息.Storm 0.9.0.1版 ...
- redhat6.4上build storm 0.9.0.1
1.安装mvn 2.下载源代码 3.build mvn package 过程中出现问题,clojars.org 访问不了.通过私服映射clojars.org并在pom.xml中将dependency的 ...
- mac10.9下eclipse的storm开发环境搭建
--------------------------------------- 博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1& ...
- Apache Storm 的历史及经验教训——Nathan Marz【翻译】
英文原文地址 中英文对照地址 History of Apache Storm and lessons learned --项目创建者 Nathan Marz Apache Storm 最近成为了ASF ...
- 从Apache Storm学到的经验教训 —— storm的由来(转)
阅读目录 Storm来源 初探 再探 构建第一个版本 被Twitter收购 开源的Storm 发布之后 Storm的技术演进 构建开发者社区版 离开Twitter 提交到Apache Apache孵化 ...
随机推荐
- bzoj3997
题解: dp f[i][j]=max(f[i-1][j+1]+a[i][j],max(f[i-1][j],f[i][j+1])); 代码: #include<bits/stdc++.h> ...
- @ResponseBody中文乱码解决方案
java web项目,使用了springmvc4.0,用@ResponseBody返回中文字符串,乱码$$ 本以为很简单的问题,不过也找了一个小时. 网上有说这样配置的: <mvc:annota ...
- redis:集群配置
一.redis集群相关 1.概念:redis集群是通过数据分区提供可用性的,这样即使一部分节点失效也可以继续处理请求. 2.原理:集群使用数据分片实现,一个redis集群包括16384个哈希槽,数据库 ...
- oo作业总结(四)
测试与正确性论证 测试是通过构造一系列测试数据,通过对比程序的实际运行结果和预期输出结果来判断程序是否有bug的一种手段.同时,在测试的时候是默认看不到程序的具体实现的,即进行黑盒测试,例如每次OO作 ...
- Django 数据库连接配置(Oracle、Mysql)
一.Django Oracle连接配置 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.oracle', 'NAME': 'DEMO' ...
- HTML(四)Form标签
<form>…</form> 定义供用户输入的 HTML 表单 例子 <html> <body> <form method="ge ...
- mvc+struct1+struct2
转一篇写得很棒的文章:https://my.oschina.net/win199176/blog/208171?p=7&temp=1495894148424 1.基于web开发中最原始的jsp ...
- 关于iOS设备的那些事
首先推荐一个在用的库XYQuick 地址:https://github.com/uxyheaven/XYQuick idfa: 获取方式 [ASIdentifierManager sharedMana ...
- Web API 跨域访问(CORS)
1.在web.config里把“ <remove name="OPTIONSVerbHandler" /> ”删掉. 2. 到nuget上装一个包: ht ...
- Vue.js与WdatePicker日历控件冲突问题的解决方案
问题:同时使用Vue.js与WdatePicker时,双向绑定的日期字段获取不到界面输入的值,而且别的字段的值改变后,日期控件的内容会被清空 原因:WdatePicker不是Vue的插件,不能响应Vu ...