Python +selenium之集成测试报告与unittest单元测试
随着软件不断迭代,对应的功能也会越来越多,从而对应的测试用例也会呈指数增长。如果将全部的测试用例集成在一个文件中就会显得特别的臃肿而且维护成本也会很高。
一个很好的放大就是将这些测试yo你给里按照功能类型进行拆分,分散到不同测试文件中,即一个项目,对应多个分支。
1.testbaidu.py文件
from selenium import webdriver
import unittest
import time class MyTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.maximize_window()
self.driver.implicitly.wait(10)
self.driver.get("https://www.baidu.com") def test_baidu(self):
driver = self.driver
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_key("unittest")
driver.find_element_by_id("su").click()
time.sleep(2)
title = self.assertEqual(title,"unittest_百度搜索") def tearDown(self):
self.driver.quit()
2.testyoudao.py文件
from selenium import webdriver
import unittest
import time class MyTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.maximize_window()
self.driver.implicitly.wait(10)
self.driver.get("https://www.baidu.com") def test_baidu(self):
driver = self.driver
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_key("youdao")
driver.find_element_by_id("su").click()
time.sleep(2)
title = self.assertEqual(title, "youdao_百度搜索") def tearDown(self):
self.driver.quit()
二、创建用于执行所有用例的ALL_HTMLtest.py文件
1.ALL_HTMLtest.py
# coding = utf -8
import unittest
import time
from HTMLTestRunner import HTMLTestRunner # 加载用例testbaidu,testyoudao
import testbaidu
import testyoudao # 将测试用例添加到测试集合中
suite = unittest.TestSuite()
suite.addTest(testbaidu.MyTest("test_baidu"))
suite.addTest(testyoudao.MyTest("test_youdao"))
if __name__ == '__main__':
# 执行测试
runner = unittest.TextTestRunner()
runner.run(suite)
拆分带来的好处显而易见,可以根据不同功能创建不同的测试文件,甚至不同的目录,还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,整体结构更加清晰。但依然存在缺陷(当用例达到成百上千条时,在ALL_HTMLtest.py中addTest()添加测试用例会变得非常麻烦)
2.TestLoader类
unittest单元测试框架提供了TestLoader类,该类负责根据各种标准加载测试用例,并将它们返回给测试套件。正常情况下不需要创建这个类的实例。
unittest提供了可以共享的defaultTestLoader类,可以使用其子类和方法创建实例,discover()方法就是其中之一。
discover(start_dir,pattern = 'test*.py',top_level_dir = None)
找到指定目录下的所有测试模块,并递归查找子目录下的测试模块,只有匹配到文件名才能被加载,如果启动的不是顶层目录,则顶层目录必须单独指定。
start_dir :要测试的模块名或测试用例;
pattern = ‘test*.py’:表示用例文件名的匹配原则,下面的例子中匹配文件名为以“test”开头的“.py”文件,星号“*”表示任意多个字符;
top_level_dir =None: 测试模块的顶层目录,如果没有顶层目录,默认为None;
注:discover()方法会自动根据测试目录(test_dir)匹配查找测试用例文件(test*.py),并将查找到的测试用例组装到测试套件中,因此可以直接通过run()方法执行discover,简化了测试用例的查找与执行。
# coding=utf_8
import unittest
from unittest import defaultTestLoader
# 定义测试用例的目录为当前目录
test_dir = './'
discover = unittest.defaultTestLoader.discover(test_dir,pattern='test*.py') if __name__ == '__main__':
runner = unittest.TextTestRunner()
runner.run(discover)
三、集成测试报告
HTMLTestRunner目前只针对单个测试文件生成测试报告,因此需要对上面的代码进行修改,修改后的内容如下:
# coding=utf-8
import unittest
import time
from unittest import defaultTestLoader
from HTMLTestRunner import HTMLTestRunner # 定义测试用例的目录为当前目录
test_dir = './test_case'
discover = unittest.defaultTestLoader.discover(test_dir, pattern='test*.py') #测试case所放的位置在test_dir下面下类似文件名为test的。py文件
if __name__ == "__main__":
now = time.strftime("%Y-%m-%d-%H-%M-%S")
filename = test_dir + '/' + now + 'result.html'
fp = open(filename, 'wb')
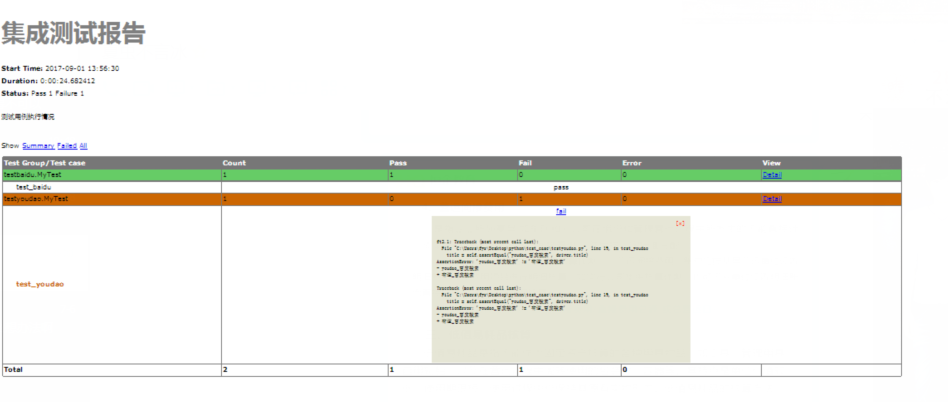
runner = HTMLTestRunner(stream=fp, title='集成测试报告', description='测试用例执行情况')
runner.run(discover)
fp.close()
注:
1.注意测试case所放的位置
Python +selenium之集成测试报告与unittest单元测试的更多相关文章
- Selenium+Python ---- 免登录、等待、unittest单元测试框架、PO模型
1.免登录在进行测试的过程中难免会遇到登录的情况,给测试工作添加了工作量,本文仅提供一些思路供参考解决方式:手动请求中添加cookies.火狐的profile文件记录信息实现.人工介入.万能验证码.去 ...
- Selenium:集成测试报告
参考内容:虫师:<selenium2自动化测试实战——基于python语言> PS:书中的代码,只能做参考,最好还是自己码一码,不一定照搬就全是对的,实践出真知啊,踩了很多坑的说... 随 ...
- Python+selenium 2【测试报告】
HTML报告 http://tungwaiyip.info/software/HTMLTestRunner.html 下载地址 这个扩展非常简单,只有一个HTMLTestRunner.py文件,选 ...
- Selenium实战(四)——unittest单元测试框架1
Python中的单元测试框架包含:doctest.unittest.pyttest.nose等,使用unittest单元测试框架不需要自行定义断言失败的提示,并且当一个测试函数执行失败后,后面的测试函 ...
- python学习笔记(27)-unittest单元测试-测试用例
单元测试 #单元测试 #unittest+接口 unittest python自带 pytest+jenkins+allure #接口测试的本质 就是测试类里面的函数 #单元测试的本质 测试函数 代码 ...
- Python+selenium自动化生成测试报告
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Selenium实战(四)——unittest单元测试2(断言方法+discover()多测试用例的执行)
一.断言方法 方法 检查 版本 assertEqual(a,b) a==b assertNotEqual(a,b) a!=b assertTrue(x) bool(x) is True a ...
- Python操作Excel,并结合unittest单元测试框架
第一步:写Excel操作方法 excel_operate.py文件 from openpyxl import load_workbook #引入模块 class MyExcel: def __init ...
- Python+Selenium框架 ---自动化测试报告的生成
本文来介绍如何生成自动化测试报告,前面文章尾部提到了利用HTMLTestRunner.py来生成自动化测试报告.关于HTMLTestRunner不过多介绍,只需要知道是一个能生成一个HTML格式的网页 ...
随机推荐
- [poj1811]Prime Test(Pollard-Rho大整数分解)
问题描述:素性测试兼质因子分解 解题关键:pollard-rho质因数分解,在RSA的破译中也起到了很大的作用 期望复杂度:$O({n^{\frac{1}{4}}})$ #include<cst ...
- 《Java多线程编程核心技术》读后感(九)
当interrupt方法遇到wait方法 当线程呈wait()状态时,调用线程对象的interrupt()会出现InterruptedException异常 package Third; public ...
- 快速部署Kubernetes集群管理
这篇文章介绍了如何快速部署一套Kubernetes集群,下面就快速开始吧! 准备工作 //关闭防火墙 systemctl stop firewalld.service systemctl disabl ...
- mysql的索引key_len计算方法,及个字段所占字节数
key_len的长度计算公式: varchr(10)变长字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段) ...
- linux抢占式调度
为什么会发生调度? 因为cpu是有限的,而操作系统上的进程很多,所以操作系统需要平衡各个进程的运行时间 比如说有的进程运行时间已经很长了,已经占用了cpu很长时间了,这个时候操作系统要公平 就会换 ...
- js获取当前地址栏的域名、Url、相对路径和参数以及指定参数
以下代码整理于网络 1.设置或获取对象指定的文件名或路径. window.location.pathname 例:http://localhost:8086/topic/index?topicId=3 ...
- Spring - SpringIOC容器详解
一.什么是Spring IOC: Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想. 在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是 ...
- 小程序,用js获取当前系统时间并显示
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- IDEA打开项目格式问题
今天遇到一个奇葩问题,从git上面迁maven代码下来后,然后打开文件,加载项目,会导致Modules模块加载的内容不正确,出现这种情况,要么删除原来的模块,重新导入main模块,要么采用第三张图片的 ...
- Ajax案例:异步加载商品分类信息